
hive on spark内存模型
内容介绍
hive on spark的调优,那必然涉及到这一系列框架的内存模型。本章就是来讲一下这些框架的内存模型。
hive on spark的任务,从开始到结束。总共涉及了3个框架。分别是:yarn、hive、spark
其中,hive只是一个客户端的角色。就不涉及任务运行时的内存。所以这里主要讲的yarn和spark的内存模型。
其中,由于spark是运行在yarn的container中。所以我们从外到内。先将yarn的资源分配。后讲spark的内存模型。
hive on spark提交流程
hive阶段
首先上场的是hive框架。当我们写了一个SQL语句的时候,会被hive进行解析(hive用的SQL解析框架是Antlr4)。解析的流程是:
- 解析器将SQL解析成AST(抽象语法树)
- 逻辑生成器
- 逻辑优化器 (这里主要做一些谓词下推的操作)
- 物理生成器
- 物理优化器(这里则是做基于代价的优化,简称CBO)
- 执行器 (在这里就会将Spark任务提交给yarn)
这里是进行物理优化器的地方,可以看见,从这里开始,就已经根据引擎的不同,进行不同的优化了。
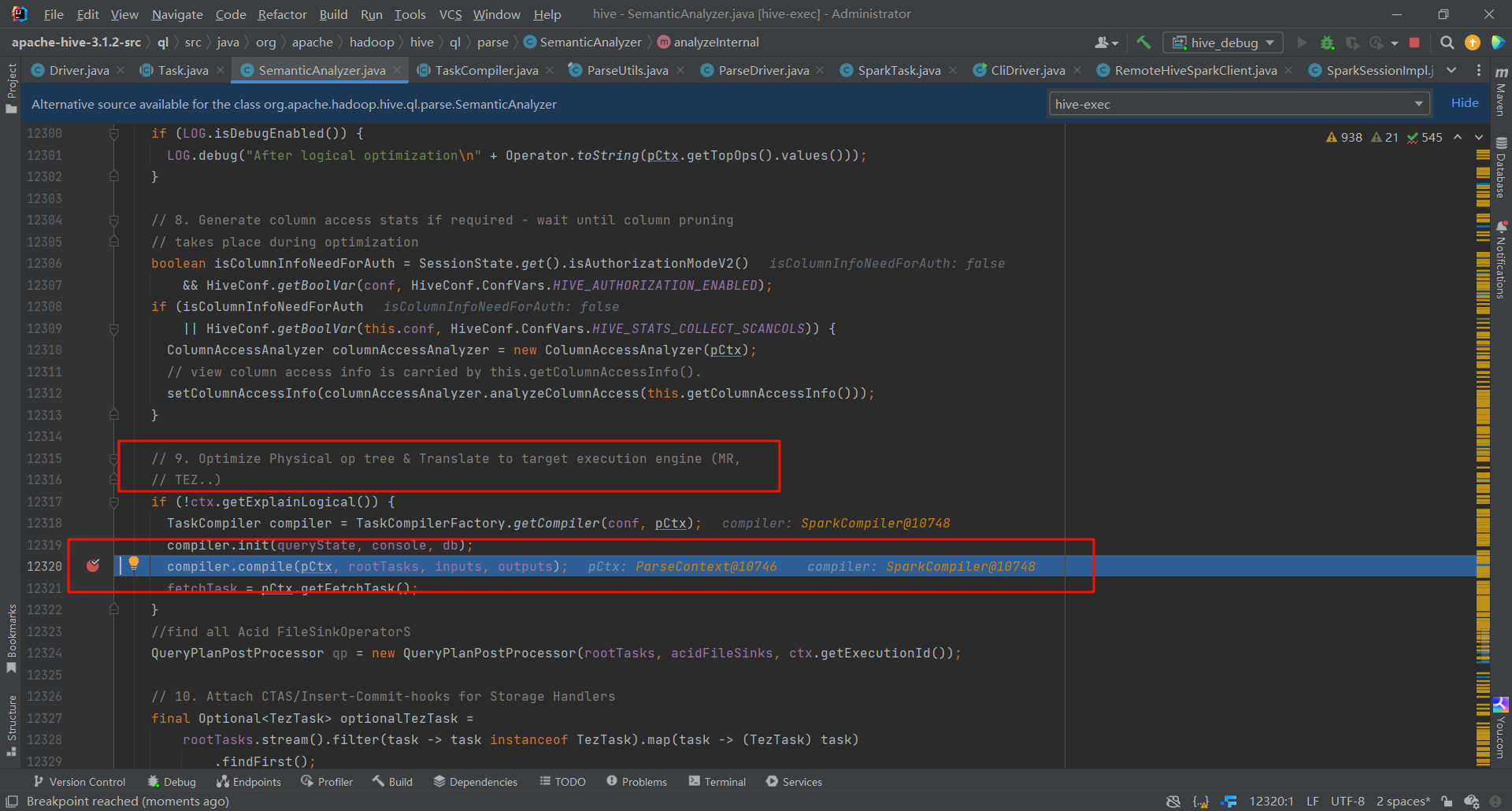
此处就是执行器
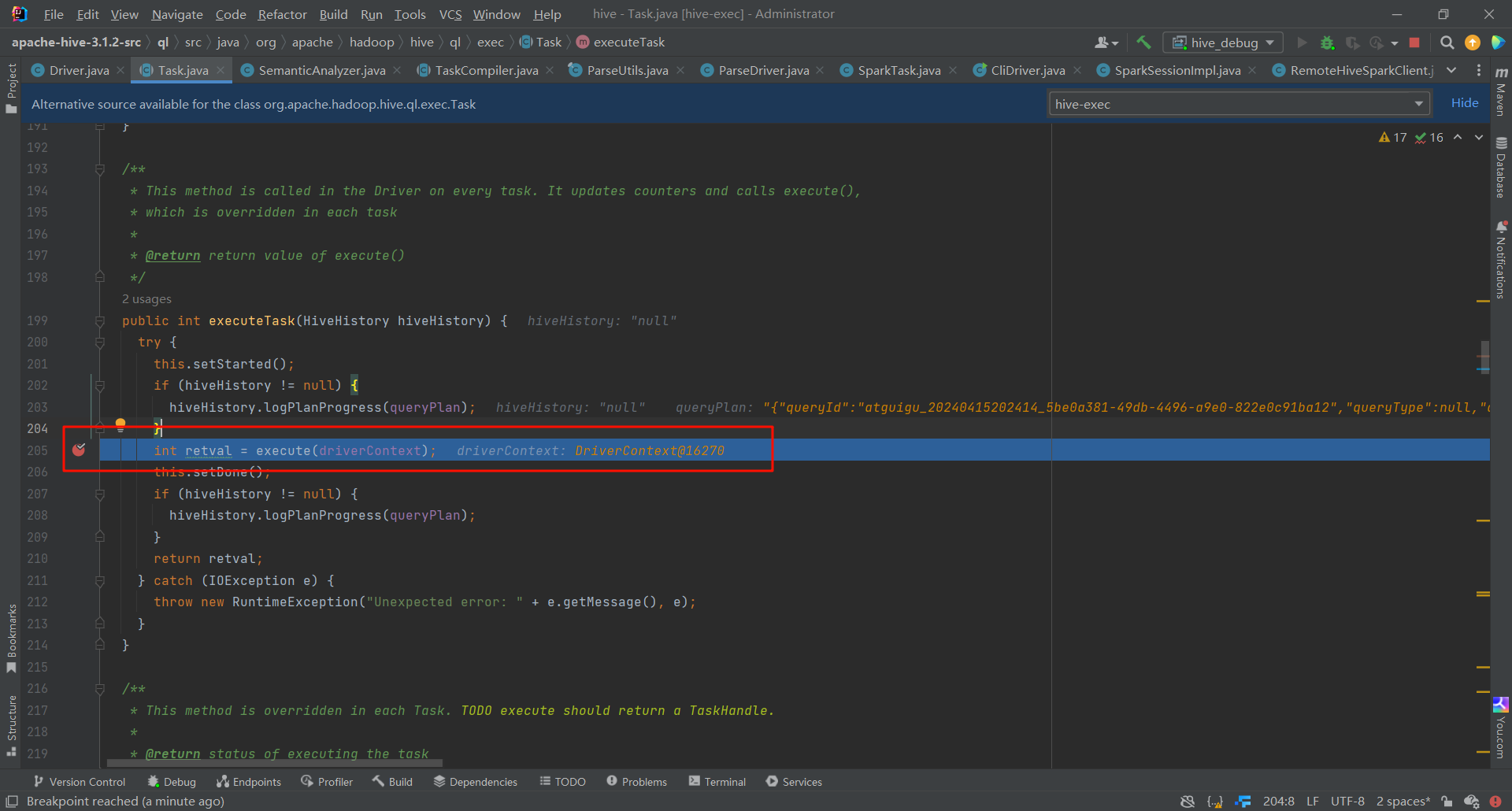
我们进去之后就可以看见 提交Spark任务
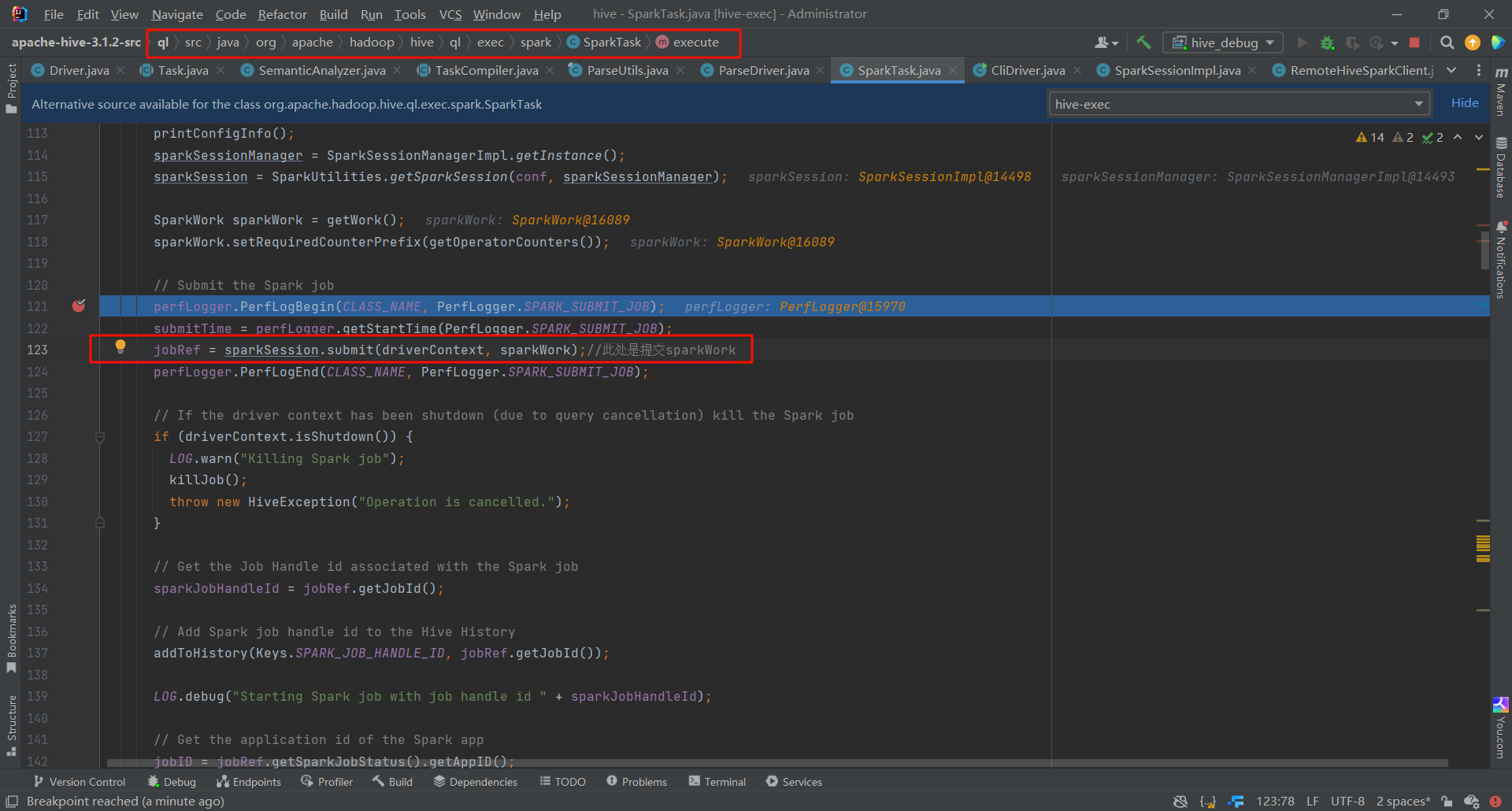
我们可以在这里看见,把job上传到yarn上,并且添加了一些监听器来获取job的状态
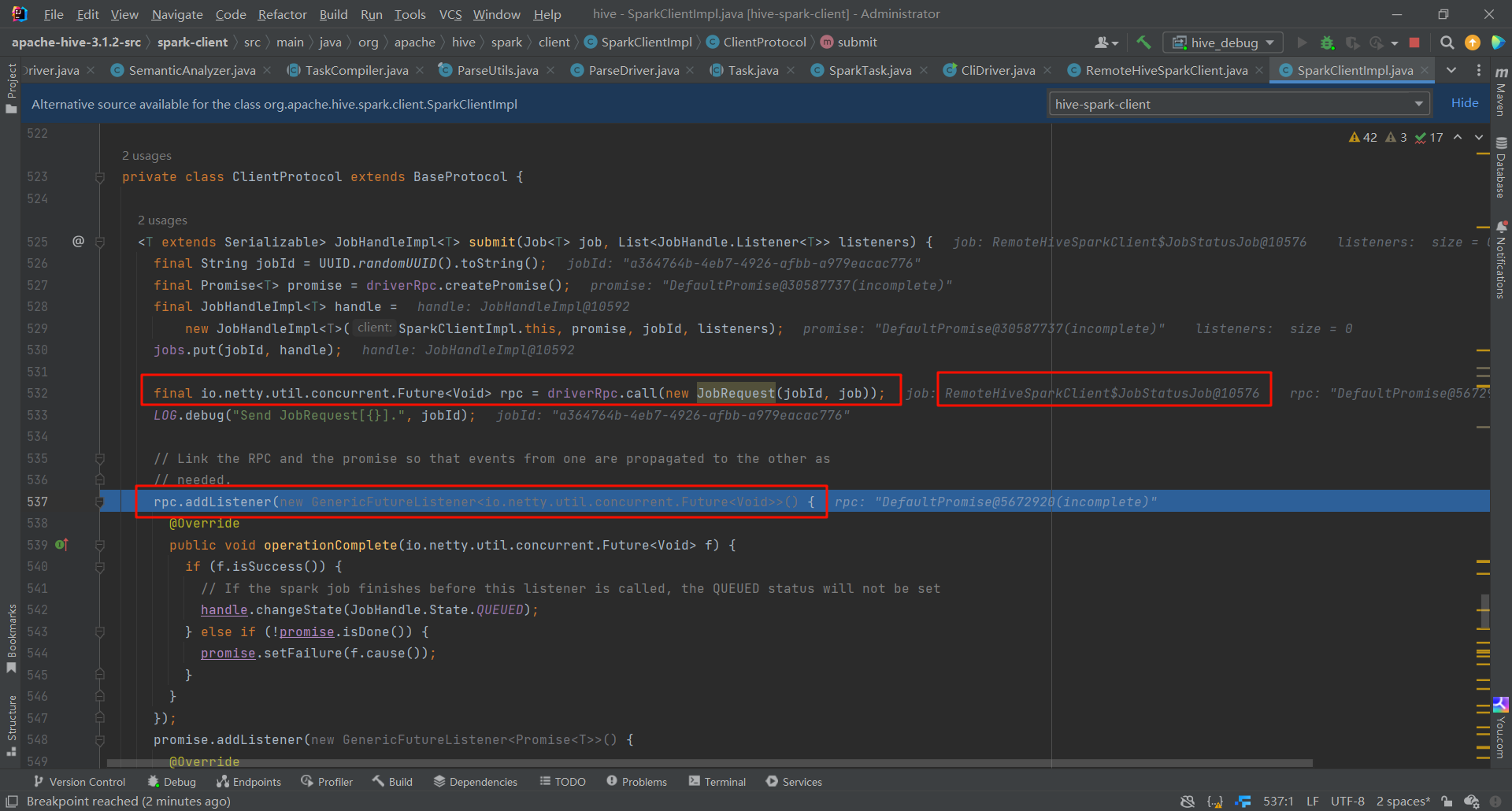
这样之后,SQL就会被转为Spark一系列的RDD。
yarn资源
在hive中,我们已经把spark job提交到yarn上面。现在我们就来看一下yarn的内存模型。
yarn的组成很简单,有ResourceManager和NodeManager,其中ResourceManager是大哥。对客户端传来的请求做处理。NodeManager是小弟。负责运行任务。
就此而言,我们就可以做出一个简单的判断:对于资源(内存和CPU)的分配,我们要多给NodeManager资源。ResourceManager无需很多的资源。因为ResourceManager仅仅是处理客户端的请求和管理NodeManager。并不进行任务的计算。
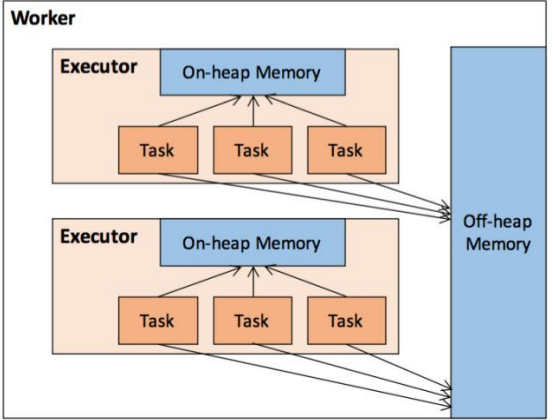
NodeManager里面是很多的Container,我们的Spark任务就是跑在Container里面的。
yarn中关于资源的参数
由于spark任务是跑在NodeManager下的Container中。所以我们可以对NodeManager和Contaniner进行参数的调整(资源的配置)
NodeManager的参数
- yarn.nodemanager.resource.memory-mb : NodeManager可以给Container分配内存
- yarn.nodemanager.resource.cpu-vcores :NodeManager可以给Container分配的虚拟核数(因为不同的CPU可能计算能力不同。有可能一个i7的CPU顶两个i5的。所以就可以把i7的cpu映射为两个虚拟核。这样的话,就不会出现因为CPU的差异,而导致的:相同的任务跑多次。每次所耗的时间相差特别大。)
Container的参数
- yarn.scheduler.maximum-allocation-mb : 单个Container可以使用的最大内存
- yarn.scheduler.minimum-allocation-mb : 单个Container可以使用的最小内存
Spark资源
Spark的内存模型可以大致分为堆内内存和堆外内存
堆内内存
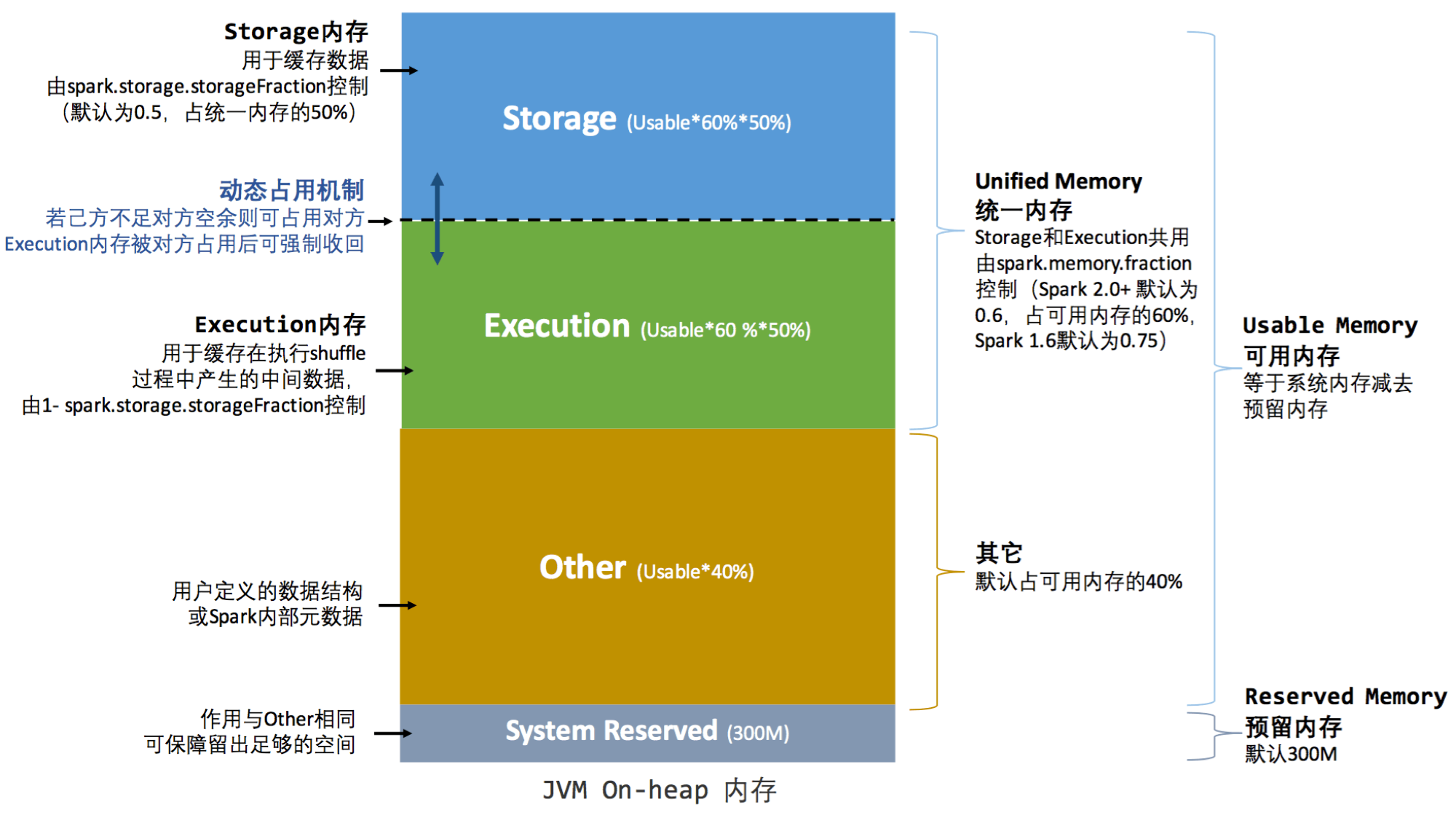
动态占用机制:简单的来说,
- 当存储和执行的内存都不足时。存储会存放到硬盘。
- 当存储占用了执行的内存后,执行想收回内存时。存储会将占用的部分转存到硬盘。归还内存
- 当执行占用了存储的内存后,存储想收回内存时,执行无法归还内存。需要等到执行使用完毕,才可以归还内存。(朴素的想一想,比较计算重要。不能停止,只好让存储等一等。等执行计算完毕,再归还内存)
堆外内存
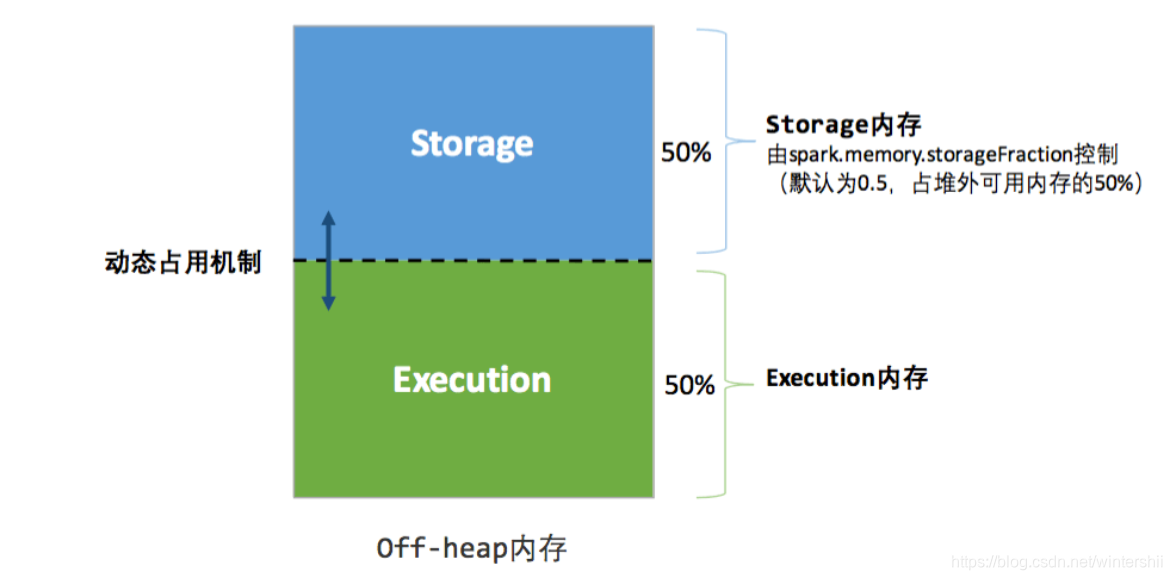
在默认情况下,堆外内存并不启用。可以通过spark.memory.offHeap.enabled开启。
堆外内存的大小由spark.memory.offHeap.size指定。
堆外内存的优点:
- Spark直接操作系统堆外内存,减少了不必要的内存开销,和频繁的GC的扫描和回收,提高了性能
- 可以被精准的申请和释放。(因为堆内内存是由JVM管理的。所以无法实现精准的释放)
整合yarn和Spark
我们先对一台服务器的资源配置做出假设,并根据这些假设,对资源进行合理的分配。
服务器的资源情况: 32核CPU,128G内存
因为我们的服务器不可能只是为yarn一个框架提供资源。其他的框架也需要资源。所以我们可用分配给yarn的资源为:16核CPU,64G内存
Spark任务分为Driver和Executor。
Executor
由于 Spark 的Executor的CPU建议数量是4~6个。 然后服务器中yarn可用的CPU资源数是16。
16/4=4;16/5=3...1;16/6=2...4;可以看出。单个Executor的CPU核数为5、6的时候,都会有一些CPU核未使用上,造成CPU的浪费。所以我们选取 单个Executor的CPU核数为4。然后我们根据1CU原则(1个CPU对应4G内存)。所以Executor的内存数为4*4G。
单个Executo资源情况: 4核CPU,16G内存。
根据资源的配置情况可知, 一个节点能运行的Executo数量为 4
这样,我们对于单个Executor 的资源分配好了。我们再来看Executor内部的内存分配。
由上面的Spark的内存模型可知。Spark的内存分为堆内和堆外内存。在默认情况下 堆外内存=堆内内存0.1 (spark.executor.memoryOverhead=spark.executor.memory0.1)
所以简单的计算一下就可知:
spark.executor.memoryOverhead=\(\frac{1}{11}*16G(单个Executor的可用的总内存)\)spark.executor.memory=\(\frac{10}{11}*16G(单个Executor的可用总内存)\)
当然,很多情况下这个结果都不是整数。所以计算出结果后,再进行一些个人的调整就好。
在这里Executor内部实际的内存分配情况如下:
spark.executor.memoryOverhead=2G
spark.executor.memory=14G
到这里,我们给各个组件的资源就已经分配完毕了。
下面我们来从Spark任务的角度谈一下,一个Spark任务,应该使用多少个Executor合适。
对于一个Spark任务的Executor数量,有静态分配和动态分配两种选择。
我们当然是选择动态分配。(因为静态分配相比于动态分配,更容易造成资源的浪费或者Spark任务资源的不足。)
动态分配: 根据Spark任务的工作负载,可用动态的调整所占用的资源(Executor的数量)。需要时申请,不需要时释放。下面是动态分配的一些参数的设置
#启动动态分配
spark.dynamicAllocation.enabled true
#启用Spark shuffle服务
spark.shuffle.service.enabled true
#Executor个数初始值
spark.dynamicAllocation.initialExecutors 1
#Executor个数最小值
spark.dynamicAllocation.minExecutors 1
#Executor个数最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空闲时长,若某Executor空闲时间超过此值,则会被关闭
spark.dynamicAllocation.executorIdleTimeout 60s
#积压任务等待时长,若有Task等待时间超过此值,则申请启动新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
#spark shuffle老版本协议
spark.shuffle.useOldFetchProtocol true
\(\color{ForestGreen}{为什么启动Spark的shuffle}\):作用是将map的输出文件落盘。供后续的reduce使用。
\(\color{ForestGreen}{为什么落盘}\):因为如果map的输出的文件不落盘。map就不会被释放。也就无法释放这个空闲的Executor。只有将输出文件落盘后,这个Executor才会被释放。
Driver
Driver主要的配置参数有spark.driver.memory和spark.driver.memoryOverhead。
此处spark.driver.memory和spark.driver.memoryOverhead的分配的内存比例和Executor一样。都是spark.driver.memoryOverhead=spark.driver.memory*0.1
对于Driver的总内存,有一个经验公式:(假定yarn.nodemanager.resource.memory-mb设为\(X\))
- 若\(X>50G\),则Driver设为12G
- 若\(12G<X<50G\),则Driver设为4G
- 若\(1G<X<12G\),则Driver设为1G
因为我们的yarn.nodemanager.resource.memory-mb=64G。所以:
spark.driver.memory= 10Gspark.driver.memoryOverhead= 2G
配置文件的设置
spark-defaults.conf
配置文件的位置:$HivE_HOME/conf/spark-defaults.conf
由于我们多个节点有Spark。所以可能会有一些疑问:\(\color{ForestGreen}{这么多Spark,这么多配置文件,究竟是Spark任务运行的节点 的配置文件生效呢?还是Hive目录下的配置文件生效呢?}\)
答案:当然是Hive目录下的配置文件生效。如果我们了解过Spark的任务提交流程就知道。当我们运行了一条命令行后。Spark-submit会解析参数。然后再向yarn提交请求。
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.shuffle.useOldFetchProtocol true
spark-shullfe
Spark的shullfe会因为Cluster Manager(standalone、Mesos、Yarn)的不同而不同。
此处我们是yarn。
步骤如下:
- 拷贝
$SPARK_HOME/yarn/spark-3.0.0-yarn-shuffle.jar到$HADOOP_HOME/share/hadoop/yarn/lib - 向集群分发
$HADOOP_HOME/share/hadoop/yarn/lib/spark-3.0.0-yarn-shuffle.jar - 修改
$HADOOP_HOME/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
- 分发
$HADOOP_HOME/etc/hadoop/yarn-site.xml - 重启yarn

