
Hive的row_number和regexp_extract结合带来的乱码问题

select userid, from_unixtime(createtime,'yyyy-MM-dd') as dateid, regexp_extract(browser,'^([^\\(]*).*$',1) as browser, operationsystem, device, row_number() over (partition by userid order by createtime) as rn from ods_log_full where module='user' and action='login_success' and from_unixtime(createtime,'yyyy-MM-dd')='2023-07-26'
如果这样的话,那么中文会出现乱码。
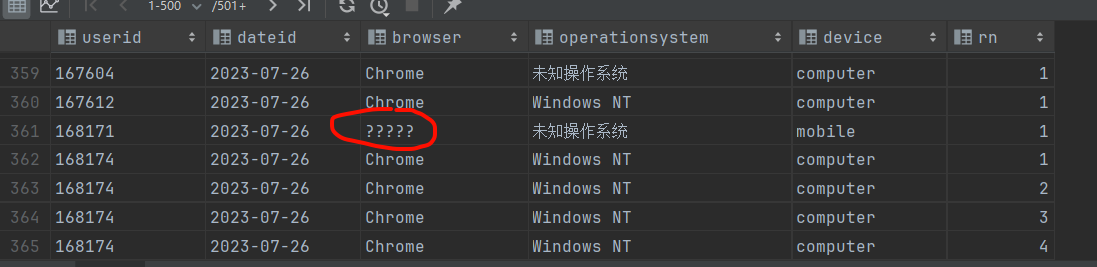
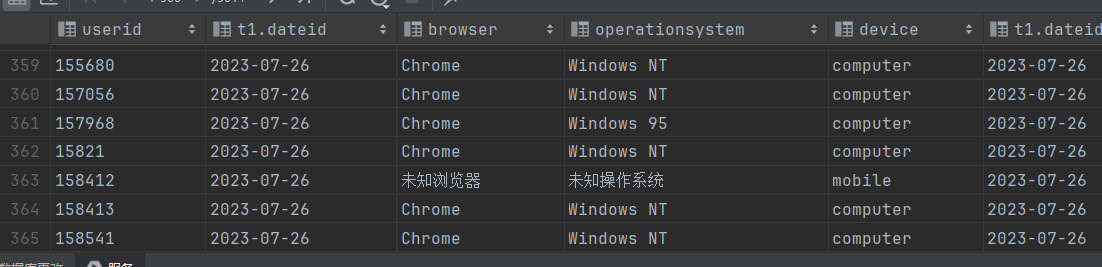
暂时的解决办法时,使用hive的regexp_replace函数。这个函数没有上述的问题。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步