

结对第二次—文献摘要热词统计及进阶需求
|
:-😐:-😐:-😐
课程链接|软件工程实践
作业要求|结对第二次—文献摘要热词统计及进阶需求
结对学号|221600425 221600429
作业目标|1.基本需求:实现一个能对文本文件中的单词的词频进行统计的控制台程序
2.进阶需求:在基本需求实现的基础上,编码实现顶会热词统计器
Github项目地址|基本需求 进阶需求
分工|221600425负责主要代码编写与测试,221600429负责爬虫编写和博客撰写
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个任务需要多少时间 | 2320 | 2910 |
| Development | 开发 | 700 | 900 |
| Analysis | 需求分析 (包括学习新技术) | 100 | 200 |
| Design Spec | 生成设计文档 | 120 | 180 |
| Design Review | 设计复审 | 40 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 300 | 480 |
| Coding | 具体编码 | 700 | 800 |
| Code Review | 代码复审 | 100 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 100 | 100 |
| Test Report | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 70 | 70 |
| 合计 | 2320 | 2910 | |
解题思路描述
在拿到题目并进行理解后,我们第一步便是想到使用正则表达式。但是由于JAVA的已经封装好,使用起来比较方便,而且C++需要用库文件支持正则,这些库的语法也是不同的,因此我们选择使用JAVA进行编程。在确定了所使用的语言后,我们通过课程链接所提供的博客以及百度搜索了解了完成作业所需要的基本技能(如GitHub的一些使用方法等)。其实在搞懂基本需求和进阶需求的各个规则后,编程工作其实并不是很难,因为以前写过类似的程序;但我们并没有编写过爬虫程序,所以我们会将·一部分时间花在爬虫上面,主要通过CSDN和博客园上的博客进行学习。
设计实现过程
本次设计分为两个类,一个类用来存放实现功能的各种函数,另一个类用来编写主函数。实现功能的函数包括1.计算字符数个数的Lib.charNum(String)2.计算文本行数的 lineNum(String fileName)3.判断是否为单词的isLetter(String letter)4,计算单词总数的letterNum(String fileName)5.用例统计词频的getWordAndCount(String fileName,List
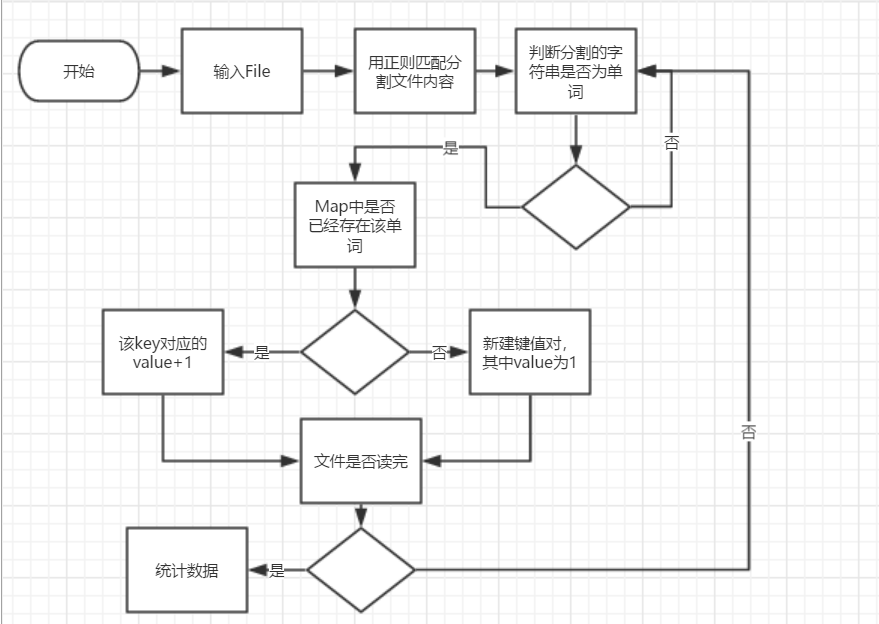
基本需求流程图
单元测试设计
测试是检查应用程序是否是工作按照要求,并确保在开发者水平,单元测试进入功能性的处理。单元测试是单一实体(类或方法)的测试。 单元测试在每一个软件公司开发高品质的产品给他们的客户是十分必要的。Eclipse是直接对junit进行了集成的,我们可以直接用。首先编写测试函数,然后我们通过输入一个测试文件进行单元测试。
代码组织与内部实现设计(类图)

进阶需求流程图

程序性能改进
由于能力有限,所以在性能分析中基本需求和进阶需求中的文献统计部分的性能改进的不是很明显,因此这里只展示爬虫部分的 ###关于爬虫程序的性能分析 优化前 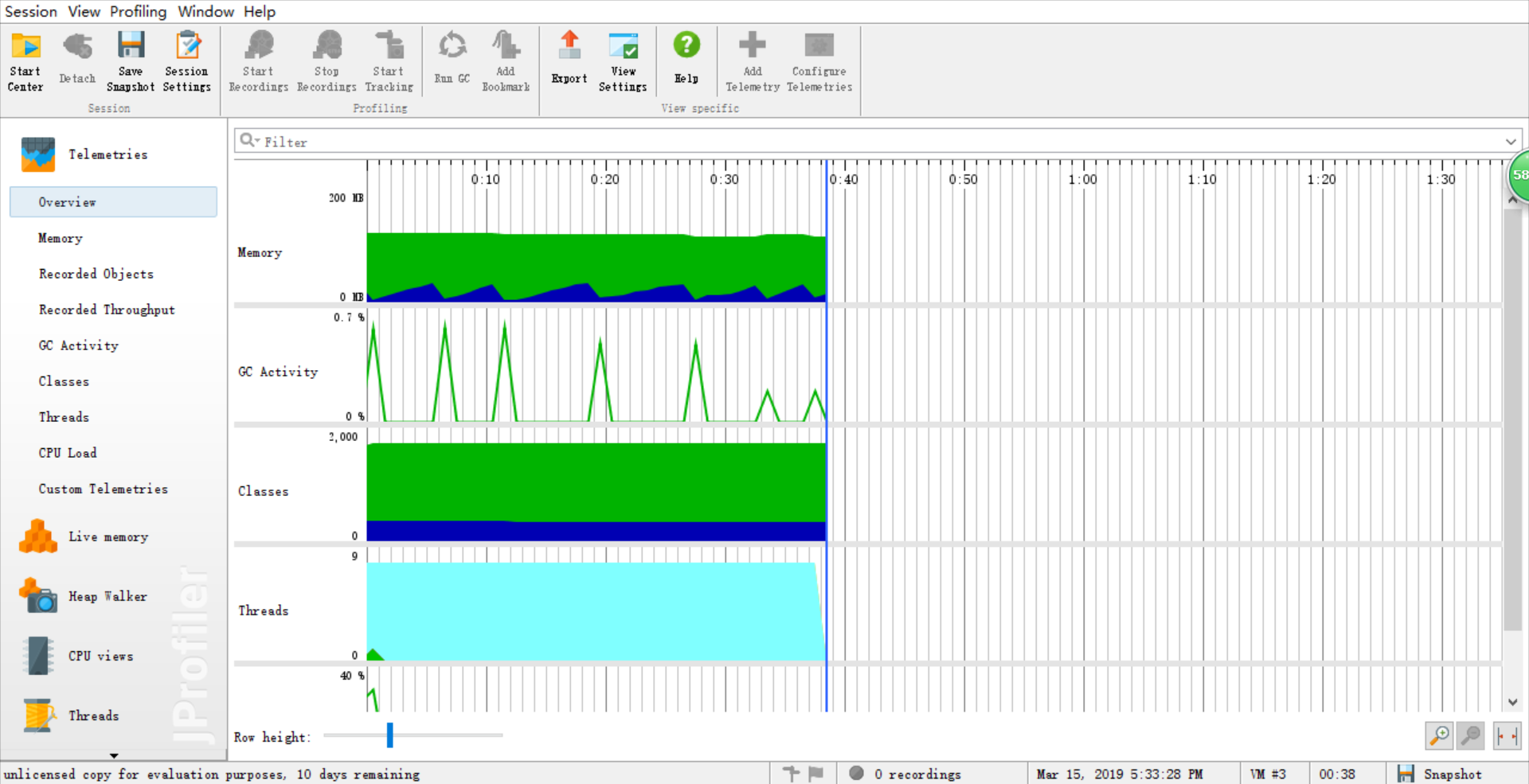 优化前各方法耗时 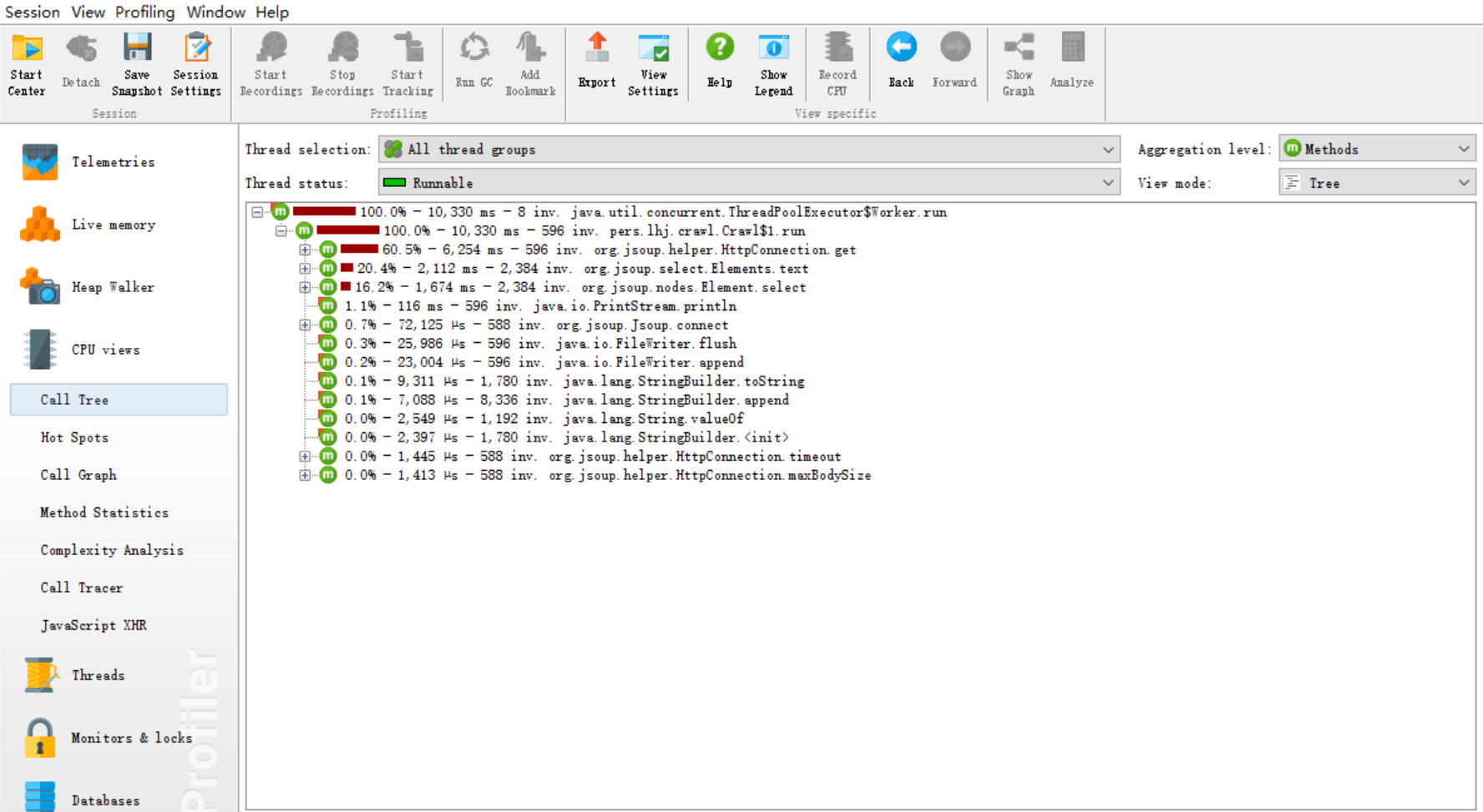 优化后 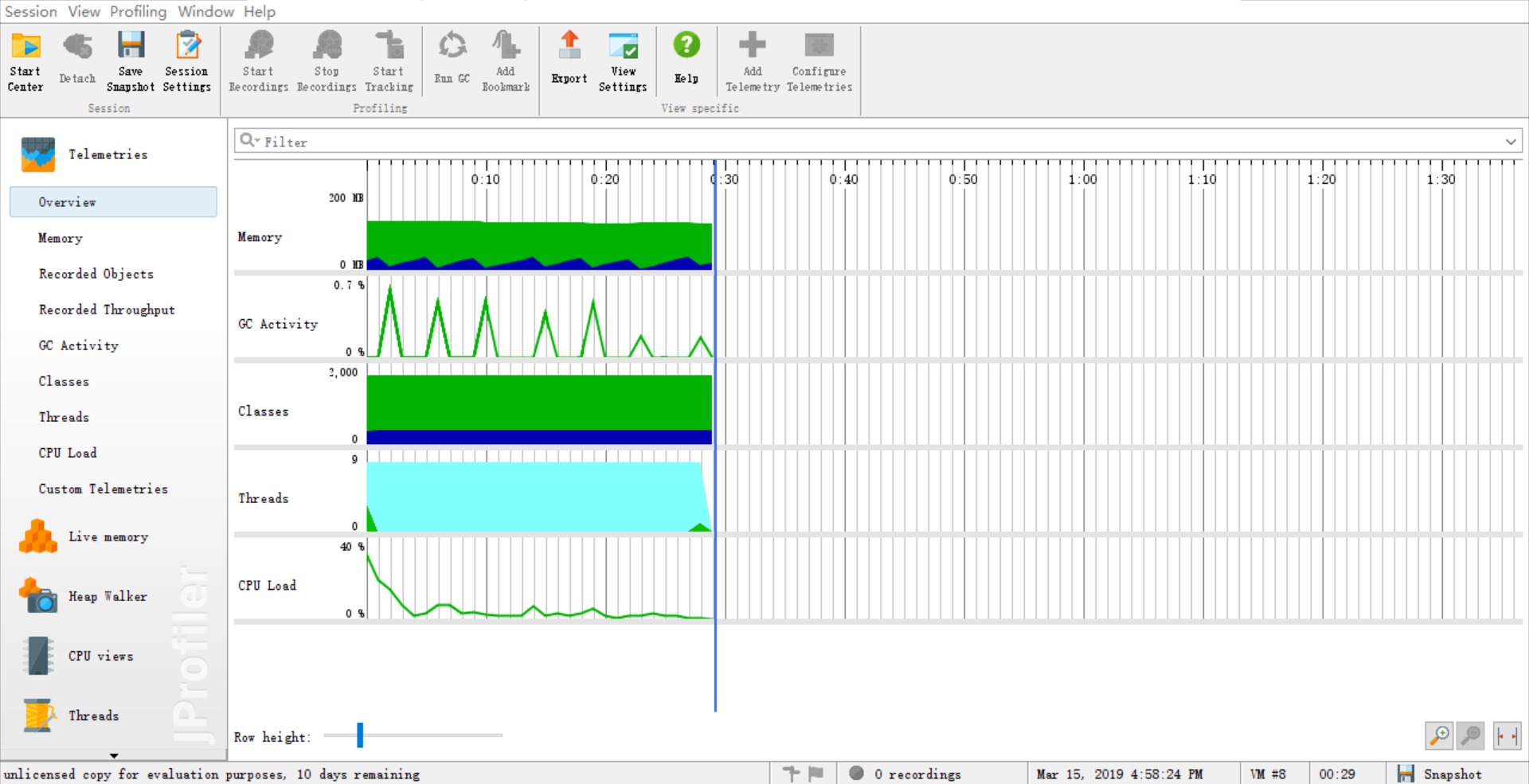 线程 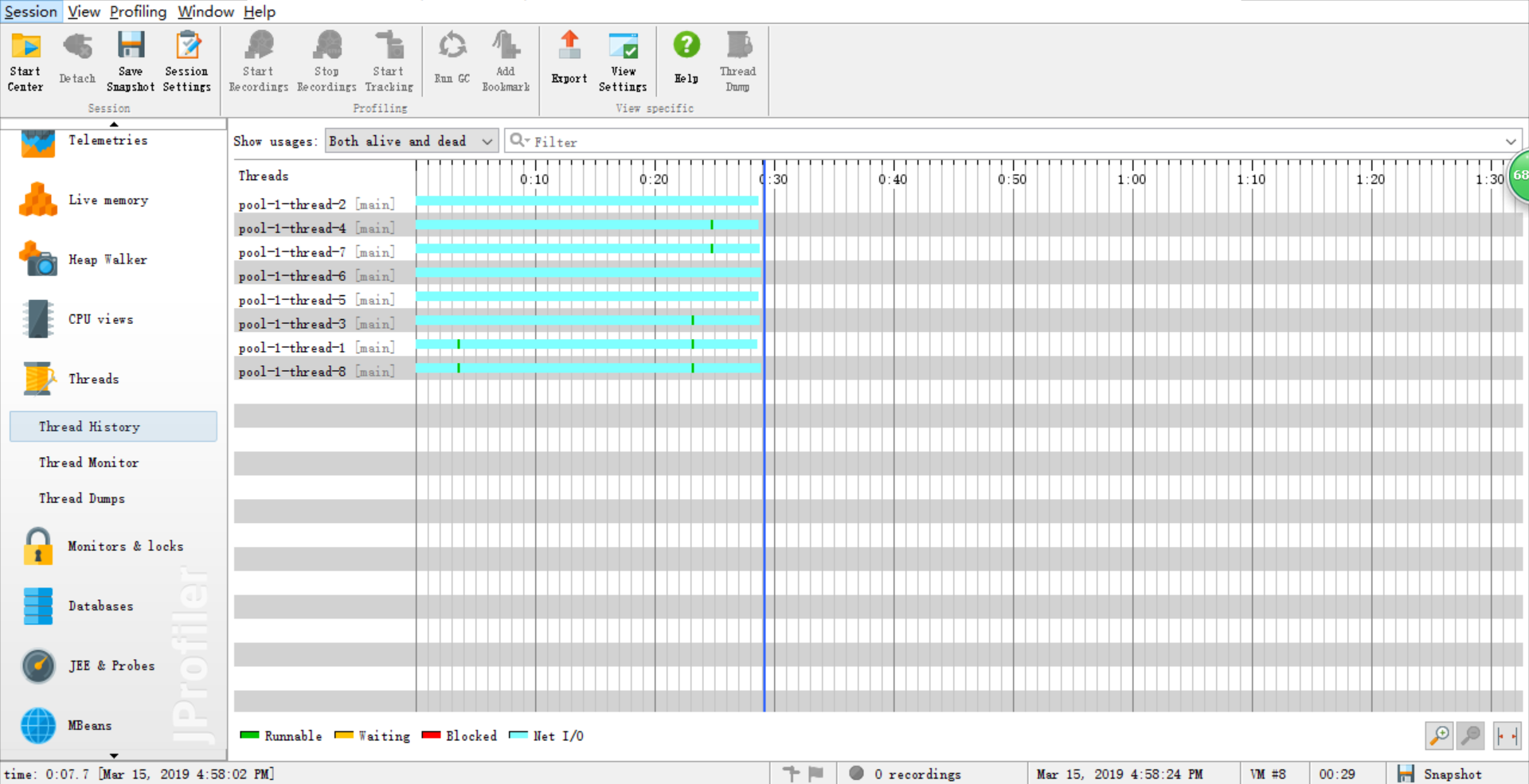 优化后各方法耗时 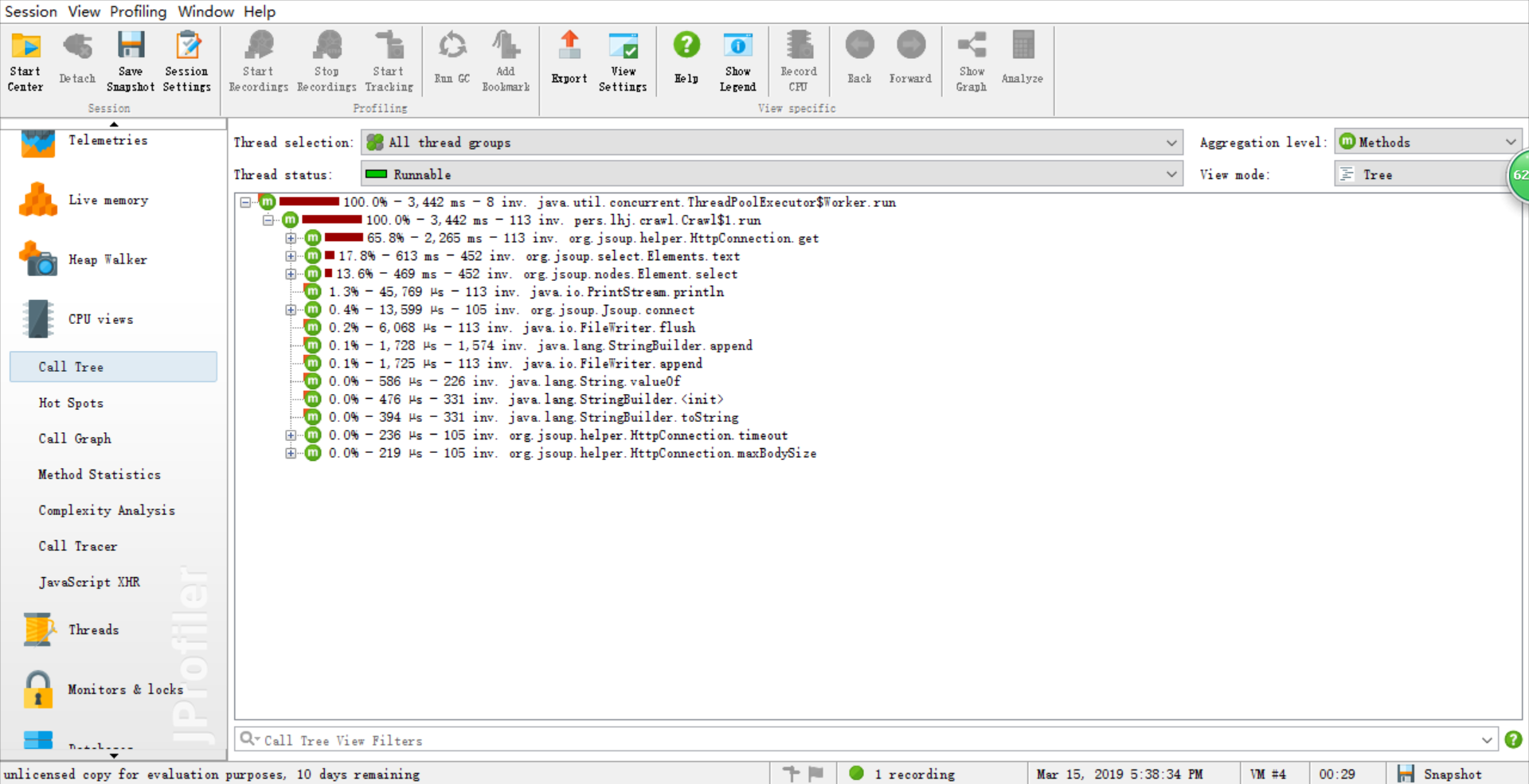
消耗最大的函数
for (Element elem : elems) {
String url=elem.attr("href");
threadPool.submit(new Runnable() {
@Override
public void run() {
try {
Document doc = Jsoup.connect("http://openaccess.thecvf.com/" + url)
.maxBodySize(0)
.timeout(5000*60) // 设置连接超时时间
.get();
System.out.println(i+"\n"+doc.select("#papertitle").text() + "\n" + doc.select("#abstract").text() + "\n");
synchronized (fw) {
fw.append(
(i++)+"\r\n"+
"Title: "+
doc.select("#papertitle").text() + "\r\n" +
"Abstract: " +
doc.select("#abstract").text() + "\r\n"
+"\r\n\r\n");
fw.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
关键代码说明
基本需求关键代码
getWordAndCount(String fileName,List
public static void getWordAndCount(String fileName,List<String> list,List<Integer> list1) {
Map<String,Integer> map = new HashMap();
String regex="[^a-zA-Z0-9]";
File srcFile=new File(fileName);
try {
FileReader fileReader=new FileReader(srcFile);
BufferedReader bufferedReader=new BufferedReader(fileReader);
String lineText=null;
while((lineText=bufferedReader.readLine())!=null) {
String[] strs=lineText.split(regex);
for(int i=0;i<strs.length;i++) {
if(isLetter(strs[i])) {
strs[i]=strs[i].toLowerCase();
if(map.containsKey(strs[i])) {
map.put(strs[i], map.get(strs[i])+1);
}
else {
map.put(strs[i], 1);
}
}
}
}
String[] words=new String[map.size()];
Integer[] counts=new Integer[map.size()];
map.keySet().toArray(words);
map.values().toArray(counts);
for(int i=0;i<map.size();i++) {
if(i<=9) {
for(int j=i;j<map.size();j++) {
if(counts[i]<counts[j]) {
Integer temp=null;
temp=counts[i];
counts[i]=counts[j];
counts[j]=temp;
String temp1=null;
temp1=words[i];
words[i]=words[j];
words[j]=temp1;
}
else if(counts[i]==counts[j]) {
if(words[i].compareTo(words[j])<0) {
Integer temp=null;
temp=counts[i];
counts[i]=counts[j];
counts[j]=temp;
String temp1=null;
temp1=words[i];
words[i]=words[j];
words[j]=temp1;
}
}
}
}
}
for(int i=0;i<words.length;i++) {
if(i>9) {
break;
}
else {
list.add(words[i]);
}
}
for(int i=0;i<counts.length;i++) {
if(i>9) {
break;
}
else {
list1.add(counts[i]);
}
}
fileReader.close();
bufferedReader.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
爬虫程序关键代码
fw=new FileWriter(new File("result.txt"));
Document doc = Jsoup.connect("http://openaccess.thecvf.com/CVPR2018.py")
.maxBodySize(0)
.timeout(1000*60)
.get();
Elements elems = doc.select(".ptitle a");
System.out.println(elems.size());
ExecutorService threadPool = Executors.newScheduledThreadPool(8);
爬虫程序采用Jsoup进行html文档的解析,首先连接到2018年的论文列表页面,并通过设置连接时间和返回所测得的数据条数来保证爬取的初步成功。然后开设线程池,利用多线程来保证爬取的速度。
for (Element elem : elems) {
String url=elem.attr("href");
threadPool.submit(new Runnable() {
@Override
public void run() {
try {
Document doc = Jsoup.connect("http://openaccess.thecvf.com/" + url)
.maxBodySize(0)
.timeout(5000*60) // 设置连接超时时间
.get();
System.out.println(i+"\n"+doc.select("#papertitle").text() + "\n" + doc.select("#abstract").text() + "\n");
synchronized (fw) {
fw.append(
(i++)+"\r\n"+
"Title: "+
doc.select("#papertitle").text() + "\r\n" +
"Abstract: " +
doc.select("#abstract").text() + "\r\n"
+"\r\n\r\n");
fw.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
以上代码通过初步爬取的信息进行深层次的爬取,主要原理是通过爬取论文列表的a标签的href属性进行进一步爬取,链接到href属性的论文链接中,同样设置连接时间以防链接超时而报错,然后对爬取的html进行操作,主要是查找#papertitle和#abstract的内容并进行返回存入result.txt文件中。由于使用多线程会导致出现脏数据和重复数据,因此在代码中我们使用了锁来防止这一情况。
进阶需求关键代码
进阶部分的关键代码中同样有基本需求中的返回字符数、返回行数、判断是否为单词、返回单词数等的函数,因此不再展示,仅展示统计词频的函数
public static void getWordFrequency(String fileName,List<String> list,List<Integer> list1,int Weightflag,int numFlag) {
int value=0;
if(Weightflag==0) {
value=1;
}
else {
value=10;
}
Map<String,Integer> map = new HashMap();
String regex="[^a-zA-Z0-9]+";
File srcFile=new File(fileName);
try {
FileReader fileReader=new FileReader(srcFile);
BufferedReader bufferedReader=new BufferedReader(fileReader);
String lineText=null;
while((lineText=bufferedReader.readLine())!=null) {
if(lineText.contains("Title: ")) {
String temp=lineText.replaceFirst("Title: ", "");
//System.out.println(temp);
String[] strs=temp.split(regex);
for(int i=0;i<strs.length;i++) {
if(isLetter(strs[i])) {
strs[i]=strs[i].toLowerCase();
if(map.containsKey(strs[i])) {
map.put(strs[i], map.get(strs[i])+value);
}
else {
map.put(strs[i], value);
}
}
}
}
else if(lineText.contains("Abstract: ")){
String temp=lineText.replaceFirst("Abstract: ", "");
//System.out.println(temp);
String[] strs=temp.split(regex);
for(int i=0;i<strs.length;i++) {
if(isLetter(strs[i])) {
strs[i]=strs[i].toLowerCase();
if(map.containsKey(strs[i])) {
map.put(strs[i], map.get(strs[i])+1);
}
else {
map.put(strs[i], 1);
}
}
}
}
else {
continue;
}
}
String[] words=new String[map.size()];
Integer[] counts=new Integer[map.size()];
map.keySet().toArray(words);
map.values().toArray(counts);
for(int i=0;i<map.size();i++) {
if(i<numFlag) {
for(int j=i;j<map.size();j++) {
if(counts[i]<counts[j]) {
Integer temp=null;
temp=counts[i];
counts[i]=counts[j];
counts[j]=temp;
String temp1=null;
temp1=words[i];
words[i]=words[j];
words[j]=temp1;
}
else if(counts[i]==counts[j]) {
if(words[i].compareTo(words[j])<0) {
Integer temp=null;
temp=counts[i];
counts[i]=counts[j];
counts[j]=temp;
String temp1=null;
temp1=words[i];
words[i]=words[j];
words[j]=temp1;
}
}
}
}
}
for(int i=0;i<words.length;i++) {
if(i>numFlag-1) {
break;
}
else {
list.add(words[i]);
}
}
for(int i=0;i<counts.length;i++) {
if(i>numFlag-1) {
break;
}
else {
list1.add(counts[i]);
}
}
fileReader.close();
bufferedReader.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
部分单元测试代码
测试是检查应用程序是否是工作按照要求,并确保在开发者水平,单元测试进入功能性的处理。单元测试是单一实体(类或方法)的测试。 单元测试在每一个软件公司开发高品质的产品给他们的客户是十分必要的。Eclipse是直接对junit进行了集成的,我们可以直接用,这也是我们选择Java的一个原因。
代码
class charNumTest {
@Test
void test1() {
System.out.println(new Lib().charNum("input1.txt"));
}
@Test
void test2() {
System.out.println(new Lib().letterNum("input1.txt"));
}
@Test
void test3() {
System.out.println(new Lib().lineNum("input1.txt"));
}
}
以上代码中charNum方法为Lib类中的方法,可以换成其他方法,用以测试Lib中的各个单元方法。
包括:
Lib.charNum(String)//返回字符数
lineNum(String fileName)//返回行数
isLetter(String letter)//判断是否为单词
letterNum(String fileName)//返回单词数
getWordAndCount(String fileName,List<String> list,List<Integer> list1)//统计词频
总结
###问题及解决 在本次经过近一个星期的实践中,我们遇到了各种各样的问题。第一个是正则表达式的编写问题,利用Java的正则表达式可以很方便地匹配输入,同时这个问题也较为简单,通过百度可以很容易地解决这个问题。第二个问题便是文献统计的编写。进行文献的信息统计,需要想到各种可能性,漏算一种结果就会出错,同时在这个情况下也不容易查找出来,因此这个问题的难度就在于需要保证程序可以处理所有的可能性。通过小队两个人的配合,以及和其他小队的合作,我们也顺利地解决这个问题。第三个问题便是爬虫。在编写爬虫程序中,我们出现了各种问题,其中主要有"connect time out"连接超时,爬取速度过慢,爬取出现脏数据等。针对第一个问题,我们通过代码增大了链接时间,第二个问题我们采用了多线程来提高速度,但第二个问题引发了第三个问题,最后我们采用加锁的方式解决了脏数据。 ###评价 在本次实践中,我和我的队友各司其职,分工明确。我的队友在实践过程中遇到问题不放弃,认真钻研,通过努力解决了许多问题,在此过程中没有任何抱怨,十分刻苦,这正是我需要向他学习的地方。我们本次合作在我看来虽有瑕疵但算成功,这自然和我队友的努力是分不开的,在我看来他做的已经十分完美,并没有需要改进的地方。

