Boosting Weakly-Supervised Temporal Action Localization with Text Information概述
0.前言
1.针对的问题
由于缺乏时间标注,当前的弱监督时间动作定位方法通常陷入over-complete或不完全定位。本文旨在从两个方面来利用文本信息来提升WTAL,即:(a)判别目标,扩大类间差异,从而减少over-complete;(b)生成目标,增强类内完整性,从而找到更完整的时间边界。
2.主要贡献
(a)第一个利用文本信息来提高WTAL。且该方法可以很容易地扩展到现有的最先进的方法,并提高它们的性能。
(b)为了充分利用文本信息,设计了两个目标:判别目标力图扩大类间差异,从而减少over-complete;而生成目标则是增强类间的完整性,从而找到更完整的时间边界。
(c)大量实验表明,该方法在两个公共数据集上优于现有方法,全面的消融研究揭示了所提出目标的有效性。
3.方法
针对判别目标,提出了文本段挖掘(TSM)机制,该机制基于动作类标签构建文本描述,并将文本作为查询挖掘所有与类相关的片段。具体来说,首先使用提示模板将类标签信息合并到文本查询中。在没有时间标注的情况下,TSM需要将文本查询与整个数据集中不同视频的所有片段进行比较,在比较过程中,将挖掘与文本查询最匹配的片段,而忽略其他不相关的片段。这样,所有视频中具有相同类的片段和文本查询就会被拉得很近,而把其他的推得很远,从而增强了类间的差异。
由于视频的不同类别动作存在共享子动作,单纯应用TSM过于严格,忽略了与语义相关的片段,导致定位不完全。作者进一步引入了一个名为视频文本语言补全(VLC)的生成目标,它专注于视频中所有与语义相关的片段来补全文本句子。具体来说,首先,为视频的动作标签构建一个描述句子,并屏蔽句子中的关键动作词,如图2所示。然后设计注意力机制,尽可能完整地收集语义相关片段,通过语言重构器预测被屏蔽的动作文本,增强类内完整性。
模型框架如下:
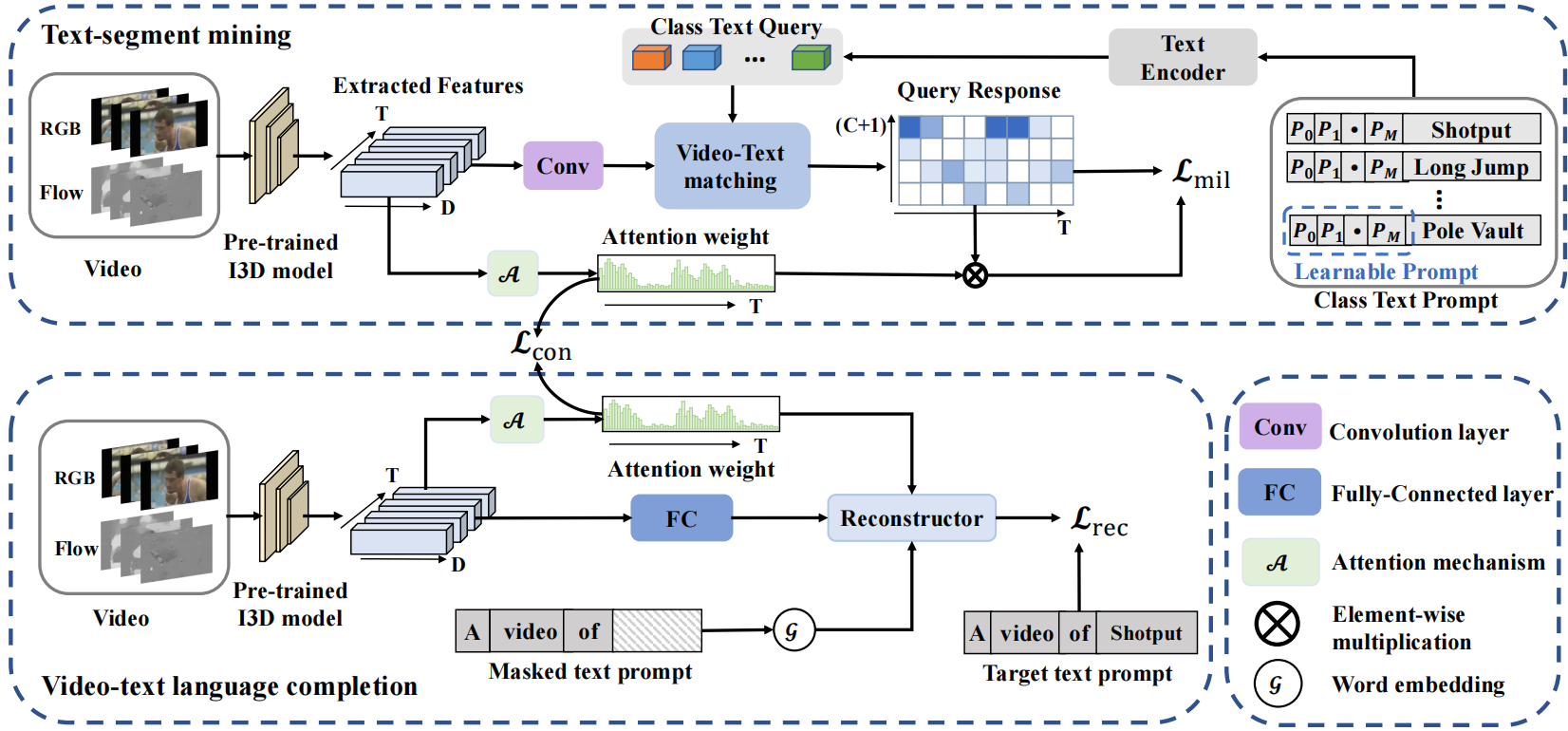
上半部分为TSM,下半部分为VLC。
TSM由视频嵌入模块、文本嵌入模块和视频文本特征匹配模块组成。
视频嵌入模块。视频嵌入模块由两个1D卷积组成,然后是ReLU和Dropout层。将RGB和Flow特征融合,得到视频特征X∈RT ×2048作为视频嵌入模块的输入。则可以由X = emb(X)得到相应的视频特征嵌入Xe∈RT×2048,其中emb(·)表示视频嵌入模块。此外,利用注意力机制(多个卷积层加sigmoid)对每个视频片段Vj产生注意力权重attm∈RT ×1
文本嵌入模块。文本嵌入模块旨在使用动作标签文本生成一系列查询,用于挖掘视频中与类别文本相关的片段。对C类动作标签文本采用category-specific可学习提示,形成文本嵌入模块Lq的输入:
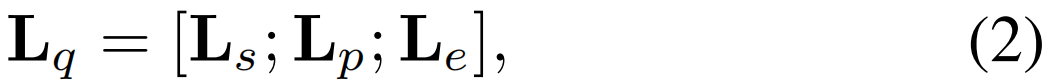
其中Ls表示随机初始化的[START]token,Lp表示长度为Np的可学习文本上下文,Le表示GloVe生成的动作标签文本特征嵌入。此外,第C + 1个额外的背景类嵌入被初始化为0。然后使用Transformer编码器作为文本嵌入模块来生成文本查询得到类文本查询Xq∈R(C+1)×2048。
视频文本特征匹配。用于匹配与语义相关的文本查询和视频片段特征。具体来说,对视频嵌入特征Xe与文本查询Xq进行内积运算,生成段级视频文本相似矩阵S∈RTx(C+1)。此外,使用注意力权重attm来抑制背景片段对动作文本的响应。背景抑制的段级匹配结果![]() ∈RT ×C+1通过
∈RT ×C+1通过![]() = attm * S得到,“*”表示元素级乘法。最后,使用top-k多示例学习来计算匹配损失。具体来说,计算特定类别文本查询对应的时间维度上top-k相似度的平均值作为视频级视频-文本相似度。
= attm * S得到,“*”表示元素级乘法。最后,使用top-k多示例学习来计算匹配损失。具体来说,计算特定类别文本查询对应的时间维度上top-k相似度的平均值作为视频级视频-文本相似度。
对于第j个动作类别,视频级相似度vj 和![]() 分别由S和
分别由S和![]() 生成:
生成:
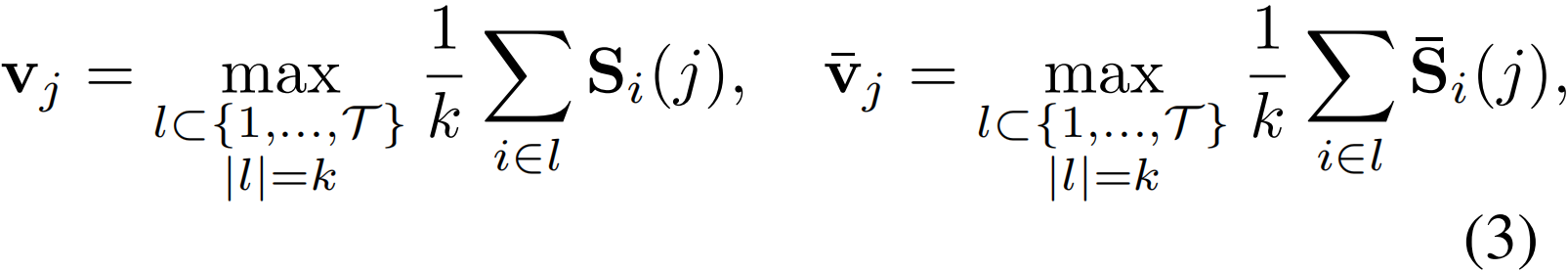
其中l是包含与第j个文本查询相似度最高的top-k片段索引的集合,k是选中的片段个数。然后,将softmax应用于vj 和![]() 来生成视频级相似度分数pj和
来生成视频级相似度分数pj和![]() 。鼓励视频文本类别的positive得分匹配接近1,negative得分接近0,训练TSM目标;
。鼓励视频文本类别的positive得分匹配接近1,negative得分接近0,训练TSM目标;
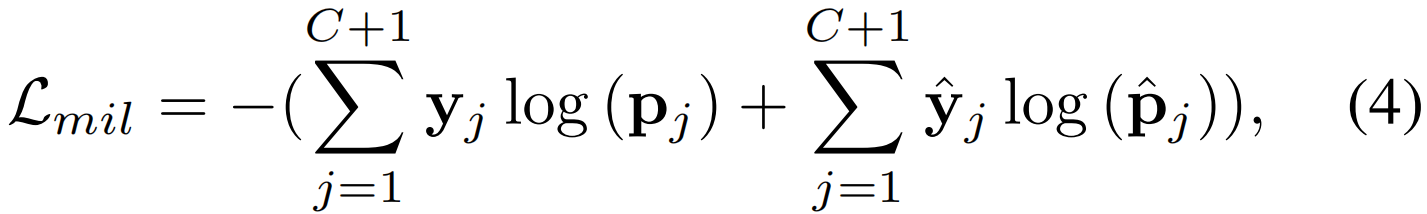
其中yj 和![]() 是视频文本匹配的标签。此外,额外的第C + 1背景类在
是视频文本匹配的标签。此外,额外的第C + 1背景类在![]() 中为0,在yj 中为1。
中为0,在yj 中为1。
VLC的目标是通过尽可能全面地关注与文本相关的视频片段,补全视频描述中的被屏蔽关键词。提出的VLC也包含一个视频嵌入模块和一个文本嵌入模块。利用transformer重构器实现多模态交互,补全原始文本描述。
视频嵌入模块。给定原始视频特征X∈RT ×2048 ,通过全连接层得到相应视频特征嵌入Xv∈RT ×512,使用于TSM中相同的注意力机制以掘文本语义相关视频的positive区域,得到注意力权重attr ∈T ×1。
文本嵌入模块。WTAL任务的数据集只提供动作视频及其动作标签,不包含描述相应视频的任何句子。因此,首先使用提示模板“a video of [CLS]”和动作标签文本来构建视频的描述句。然后,对描述句的关键动作词进行掩码,用GloVe和一个全连接层对掩码句进行嵌入,得到句子特征嵌入![]() ∈RM×512,其中M为句子长度。
∈RM×512,其中M为句子长度。
Transformer重构器。在视频文本语言补全模型中,使用transformer重构器来补全被屏蔽的描述句子。首先,随机屏蔽句子中1/3的单词作为替代描述句子,从而产生动作标签文本高概率掩码。然后,利用transformer的编码器得到前景视频特征F∈RT×512。
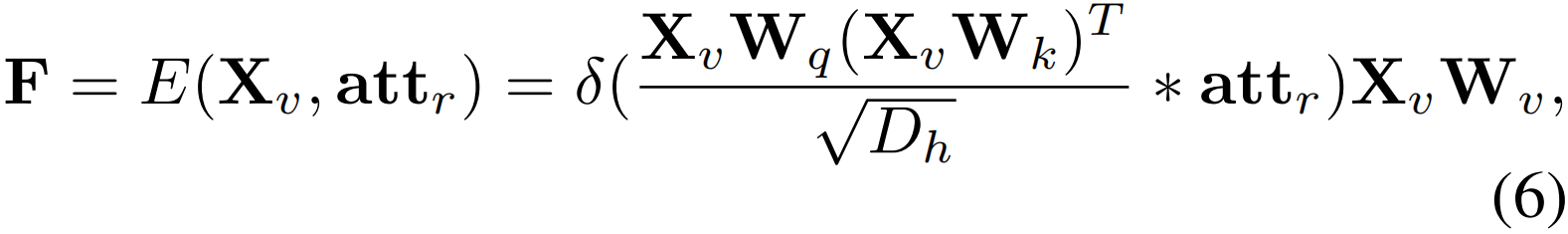
其中E(·,·)为transformer编码器,δ(·)为softmax函数,Wq、Wk、Wv∈R512×512为可学习参数,Dh = 512为Xv的特征维度
利用transformer的解码器获得多模态表示H∈RM×512来重构被掩码句子:
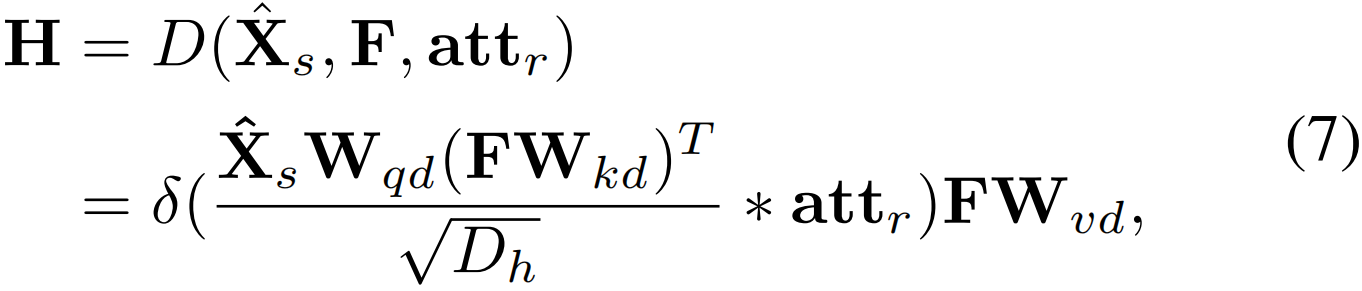
其中D(·,·,·)为transformer解码器,Wqd,Wkd,Wvd∈R512×512为可学习参数。
最后,词汇表中第i个单词wi的概率分布P∈RM×Nv可以通过以下方式得到:
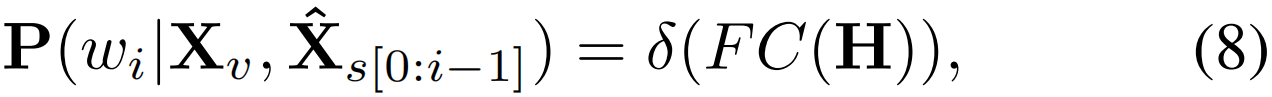
其中FC(·)为全连接层,δ(·)为softmax函数,Nv 为词汇表大小。
最终的VLC损失函数可表示为:
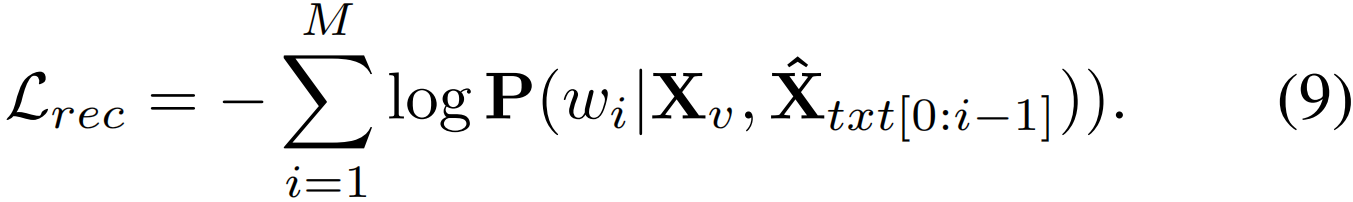
此外,作者还在判别目标TSM和生成性目标VLC这两个目标的关注之间施加自监督约束,鼓励TSM训练的attm和VLC训练的attr专注于视频中的同一动作区域,以缓解TSM对与语义最相关的片段的过度注意。
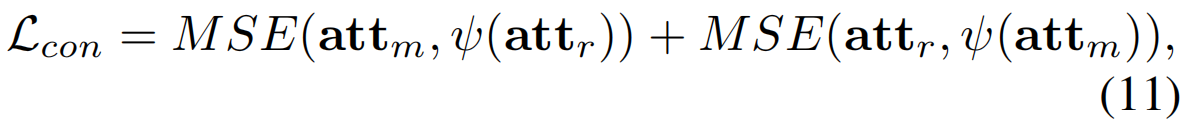
其中ψ(·)表示截断输入梯度的函数,MSE(·,·)表示均方误差损失。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号