
PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points概述
0.前言
1.针对的问题
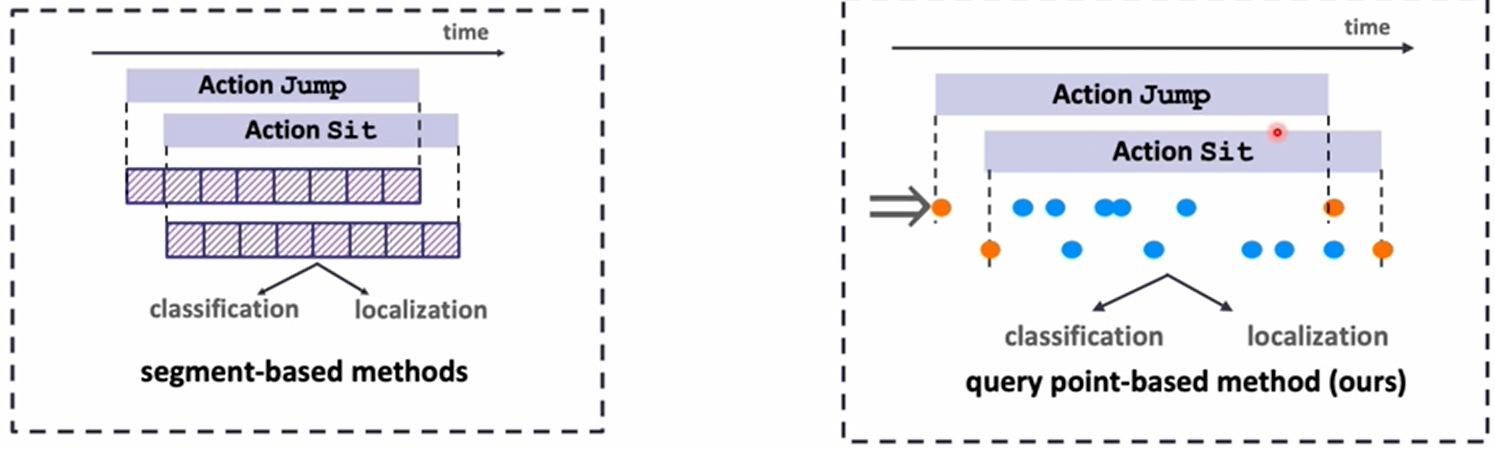
传统的动作检测方法一般都是针对单类别粗粒度的视频,而现实世界中的视频一般都存在多个类别,动作密集甚至存在重叠,虽然已经有针对多标签密集标注的方法(如MS-TCT和PDAN),但是这种方法生成一个T×C的预测矩阵,也就是为每一帧密集地预测一个C维向量,这种方法的问题是动作定位的能力比较差,容易产生大量不完整的动作预测框。
2.主要方法
作者效仿经典TAD,将多标签TAD重新定义为一个instance-level的检测任务,每个动作预测用开始结束时间和动作类别来表示,从而提高定位能力,形成更加完整的动作预测框。
但是直接将TAD的方法迁移到多标签的场景下是不够的,因为TAD方法大多依赖于基于segment的表示,并且通过均匀采样来形成动作表征,这样会导致生成的动作表征往往比较粗糙,没有办法兼顾定位和动作语义信息,因此作者提出了一种可学习的query点来代替segment表示动作,这种query点可以同时捕捉动作边界帧和动作内部的语义关键帧,同时编码定位和分类信息。
模型结构如下:
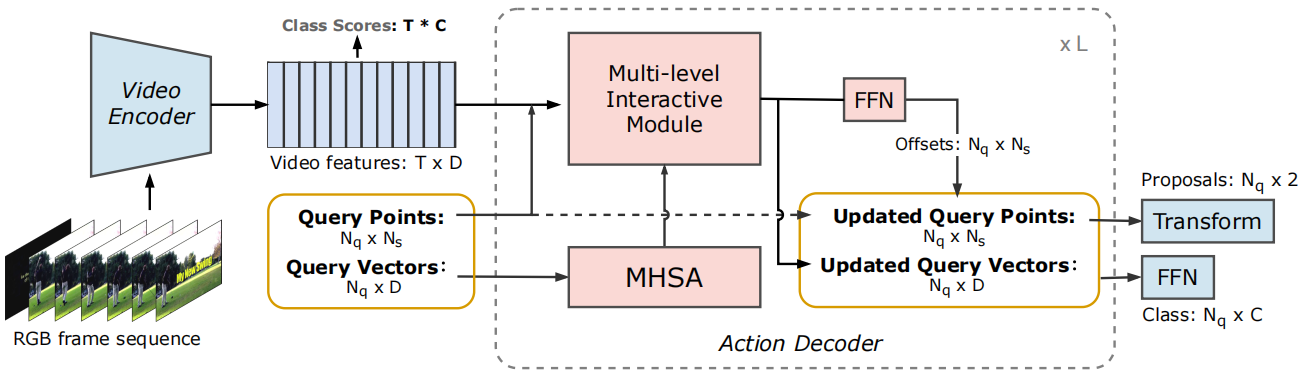
模型由两个部分组成,左边的视频编码器通过I3D网络将一系列视频帧编码为视频特征,另一部分是动作解码器,输入视频特征和动作query后,解码出动作预测。
整个模型是一个端到端的框架,query是由一组query point和query vector组成的,每个query都对应一个动作预测,query points主要编码位置信息,query vector是动作特征。
在训练过程中,query points和query vector互相更新,通过L层解码层的迭代得到好的动作预测,query points从视频特征中会采样关键帧特征来更新query vector,query vector通过self-attention之后在multi-level interactive module中被query point更新,更新后的动作特征对每个点预测偏移量,然后更新query points,最后,更新后的query points和query vector作为输出进入下一个循环。
具体更新策略:
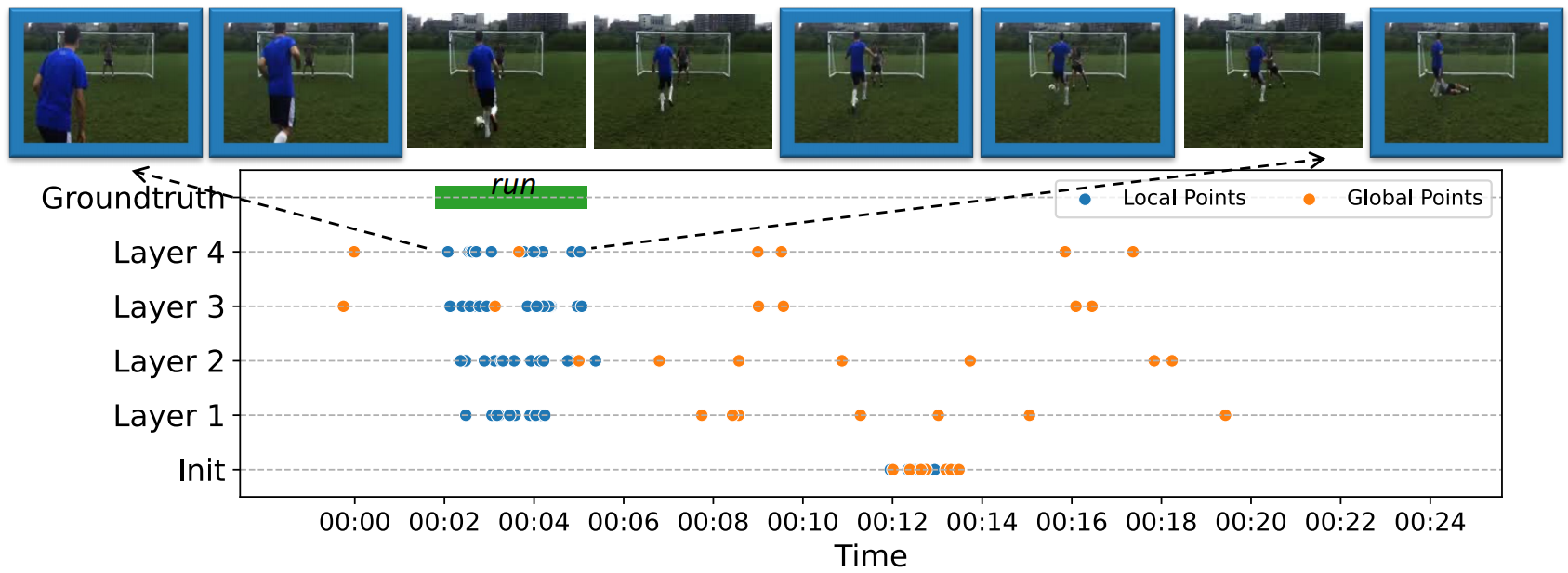
query points初始化在输入视频的中间位置,也就是图中的init部分,经过层层迭代之后会逐渐逼近GT位置。
具体来说,点的更新是由下面这条公式定义的。
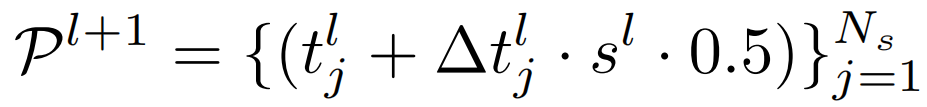
pl代表第L层的query point点集,tlj代表第j个点,每个这样的点在更新的时候加上Δtlj,也就是query vector为这一层的query point所预测的偏移量,Δtlj还要乘以一个缩放因子sl,sl表示当前层query point点集铺开的时间长度。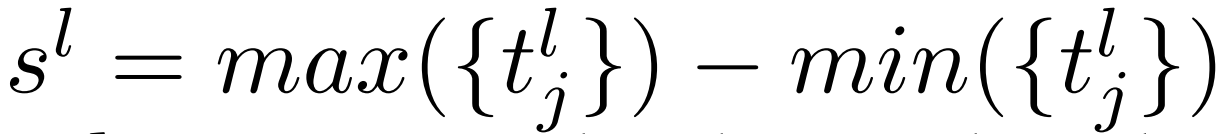
由最大的点的位置减去最小的点的位置得到。好处是可以自适应的调整偏移步长,方便短动作的精细调整。在训练中,为了规约点的位置,query points会直接收到regression loss的监督,为了实现这一点,作者将query points转换为伪框(pseudo segments),也就是图中的Transfomer部分,用伪框加入loss计算,而将poins转换为segments的函数就会很影响point的学习效果,论文中用了两种方式。
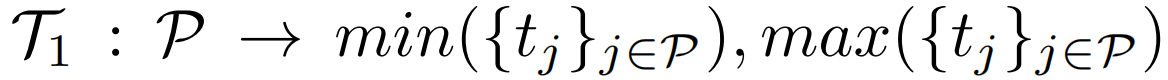
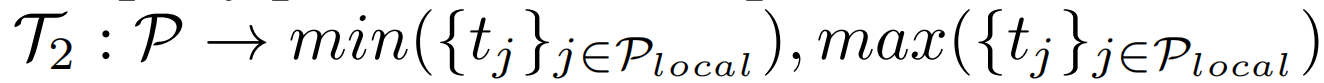
第一种为Min-max方法,取点集 P 中的时序位置最小值和时序位置最大值作为pseudo segment的开始和结束帧。第二种为Partial Min-max方法,首先从点集P中取子集Plocal,而后在 Plocal中取时序最小最大位置形成伪框。论文中选择Partial Min-max作为默认转换函数。
多尺度交互模块,除了动作的segment表示带来的问题,之前的时序动作检测器在对采样帧的解码过程中也缺乏对帧之间多尺度语义信息的考察。配合稀疏点表示,作者在动作解码器设计了多尺度交互模块,从点层次结合局部时序信息生成query point特征、从实例层次对候选框内的时序点的关系建模。点层次和实例层次的可变形参数和动态卷积参数都由动作特征(query vector)通过线性变换得到,使得每个动作预测对其对应的时序点都有各自的变换,形成具有区分性的特征。模块的示意图如图
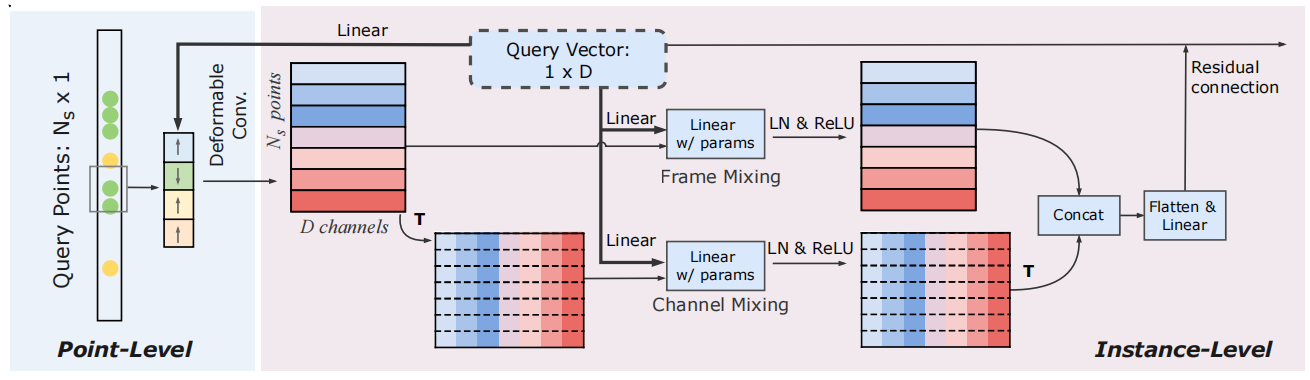
点层次的局部可变形算子 在point-level,作者利用局部可变形卷积为每个时序点建模邻域的时序结构。以每个query point为中心点,基于query vector预测4个偏移量和对应的权重,形成4个sub-point。用双线性插值采样sub-point之后,对权重归一化并加权相加sub-point特征,得到中心query point的特征。
实例层次的自适应动态卷积 在instance-level,作者不仅对每个query point的特征进行通道建模,也对描述同一个动作候选的所有query points之间的特征进行建模。采用Sparse R-CNN, AdaMixer中的动态一维卷积沿着通道和关键帧进行Mixing(混合)。区别于之前的检测器,作者发现顺序卷积对检测性能有较大的损害,因此采用并行结构对通道和帧进行mixing(Parallel Mixing)。对通道维度采用bottle-neck的两层动态卷积,对时序维度采用一层动态卷积。Mixing后的特征沿着通道拼合,通过linear变换到query vector的维度,通过残差结构更新query vector。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号