
ConvFormer: Closing the Gap Between CNN and Vision Transformers概述
0.前言
-
相关资料:
-
github
-
论文解读
-
论文基本信息:
-
发表时间:arxiv2022(2022.9.16)
1.针对的问题
CNN虽然效率更高,能够建模局部关系,易于训练,收敛速度快。然而,它们大多采用静态权重,限制了它们的表示能力和通用性。而全局注意力机制虽然提供了动态权重,能从每个实例预测,从而在大数据集中获得强大的性能和鲁棒性,但是计算代价太高。
2.主要贡献
•提出了一种新颖的注意力机制MCA,该机制具有动态性,针对不同的分辨率模式采用了不同大小的卷积核。
•基于MCA,设计了一个综合了ViT和CNN优点的通用CNN骨干网ConvFormer。
•对多个视觉任务进行了广泛的实验,包括图像分类、目标检测和语义分割,以评估ConvFormer。实验结果表明,ConvFormer实现了最先进的性能。
3.方法
本文提出的方法比较简单。MCA的两个关键组成部分是多级特征融合和门控机制。
多级特征融合能够捕捉不同分辨率下输入图像的不同模式,结合多尺度特征图。
门控机制进行特征重校准,学习选择性地强调含信息量大的特征,抑制非平凡特征。
MCA框架如下:
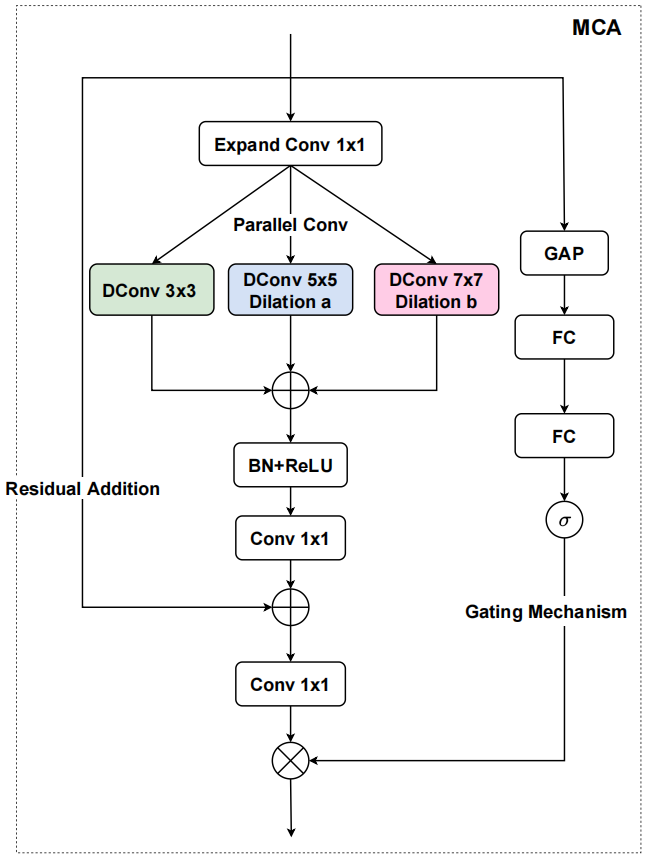
设输入为x,先用一个1×1卷积层,将通道数量扩展N倍。然后,通过3×3,5×5,7 ×7深度卷积并行学习多尺度特征,这里,5×5和7 ×7的是膨胀深度卷积,膨胀率分别为2和3,以获得更大的感受野。然后输入BatchNorm和ReLU来防止过拟合。接下来,为了应用残差连接进行更好的优化,通过1×1的卷积层来减少通道数量到与原始输入x一致,得到x'。
对于门控机制,首先使用全局平均池化层获取全局信息,然后是连续的两个全连接层。最后,利用sigmoid函数计算注意力向量Attn。
最后,将x通过1×1卷积的输出与Attn相乘得到最终输出。
ConvFormer总体框架如下:
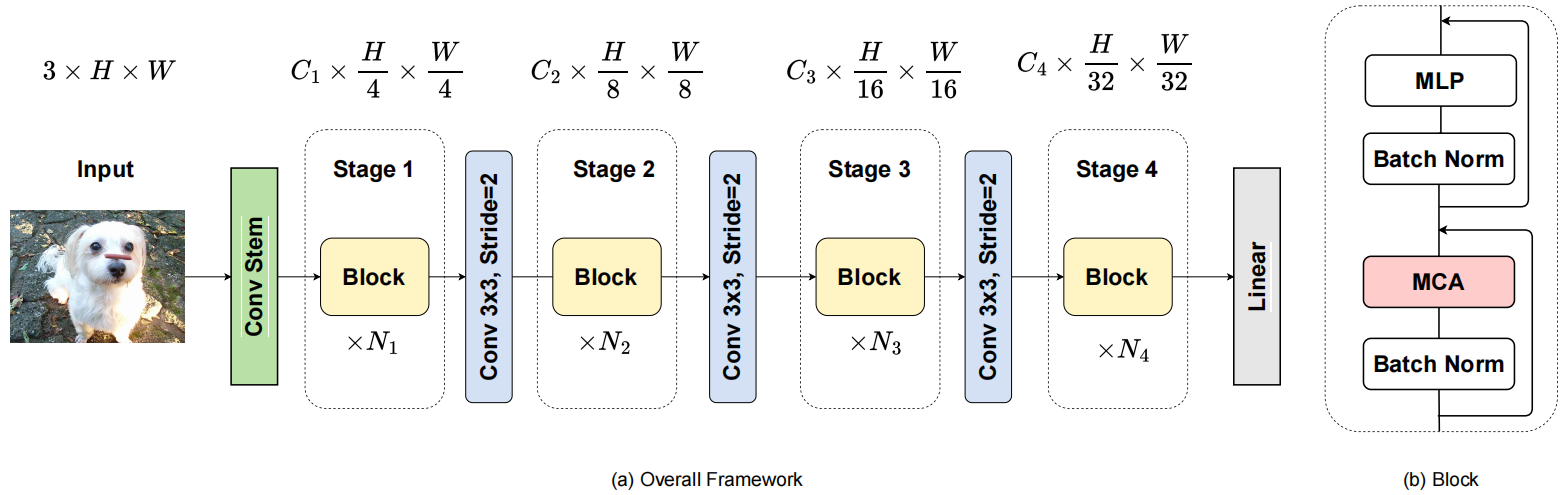
输入图片首先输入一个卷积stem,该模块由一个stride为2的7 × 7卷积层,一个stride为1的3×3卷积层和一个stride为2的不重叠的2×2卷积层组成。这样,生成的输入特征空间大小为 H/4×W/4。
表示X∈RN×C1× H/4× W/4为输入特征,N为batch大小,C1为通道数。然后,将输入的特征输入重复的ConvFormer,每个ConvFormer由两个子块组成。具体来说,第一个子块的主要组件包括MCA和BatchNorm模块,第二个子块由两个全连接的层和一个非线性激活GELU组成,也就是一个MLP。
4.补充
作者在论文中提到注意力可以分为四种基本类别:通道注意力,自适应地重新校准每个通道的权重,以关注不同的对象。时序注意力强调捕捉帧间的交互作用并决定何时进行注意力。分支注意力是一种动态的分支选择机制,使得信息可以在不同分支间流动。空间注意力产生注意力掩膜,自适应地选择重要的空间区域。而MCA就是采用通道注意力机制。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现