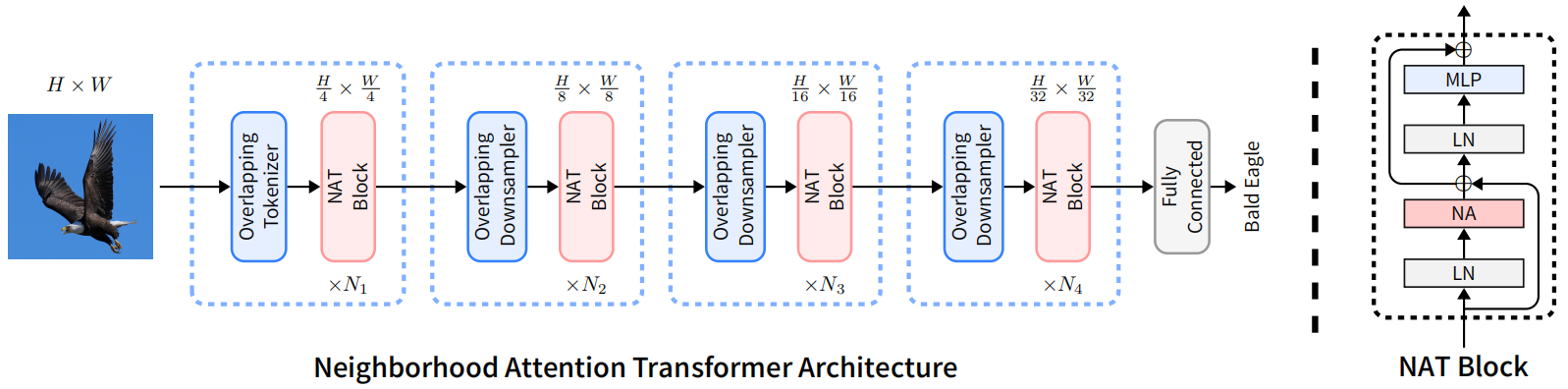
Neighborhood Attention Transformer概述
0.前言
1.针对的问题
1.之前的视觉Transformer关于嵌入维数(不包括线性投影)是线性的,但相对于token的数量是二次的,而在视觉范围内,token的数量通常与图像分辨率呈线性相关。因此,在严格使用自注意力的模型(如ViT)中,较高的图像分辨率会导致复杂度和内存使用量的二次增长。
2.卷积受益于一些归纳偏置,如局部性,平移不变性和二维邻域结构,而点积自注意力操作是一维全局操作,虽然视觉转换器中的MLP层是局部的和平移等变的,但其余的归纳偏差必须通过大量数据或高级训练技术和增强来学习。
2.主要贡献
1.提出邻域注意(NA):一种简单而灵活的视觉注意机制,它将每个标记的接受域定位到其邻域。将该模块的复杂性和内存使用与自注意、窗口自注意和卷积进行了比较。
2.引入了邻域注意Transformer(NAT),这是一种新型的高效、准确、可扩展的分层Transformer。每一层之后都有一个下采样操作,将空间大小减少了一半。类似的设计也可以在最近许多基于注意力的模型中看到,比如Swin。与这些模型不同,NAT利用小核重叠卷积进行嵌入和下采样,而不是非重叠卷积。与Swin等现有技术相比,NAT还引入了一套更有效的架构配置。
3.证明了NAT在分类和下游视觉任务上的有效性,包括目标检测和语义分割。我们观察到,NAT不仅可以超越Swin,而且还可以超越新的卷积竞争者。NAT-Tiny仅使用4.3个GFLOPs和28M参数,在NmageNet上的准确率达到83.2%,在MS-COCO上的边界框mAP为51.4%,在ADE20k上的mIoU为48.4%
4.开放一个新的CUDA支持的PyTorch扩展,用于快速和高效地计算基于窗口的注意机制。除了支持2D邻域注意模块外,该扩展还将允许定制的padding值,strides和dilated neighborhoods,以及1D和3D数据。
3.方法
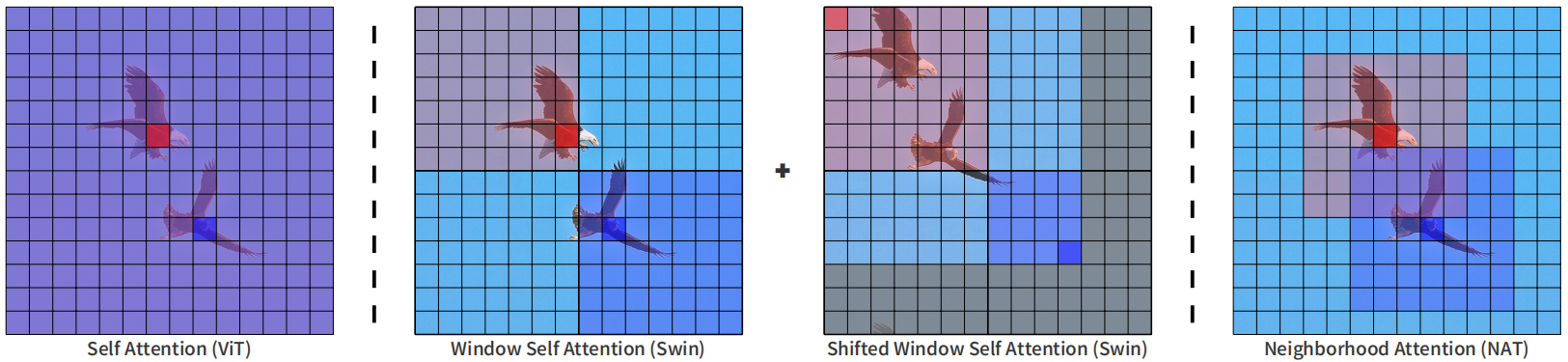
下面这个图展示了ViT,Swin和NAT的区别,标准VIT的attention计算是全局的,像第一图中红色的 token 和蓝色的 token 会全局的和所有的 token 进行计算。swin 是中间的两个图,第一步 token 的特征交互限制在局部窗口内。第二步窗口有shift,但 token 的特征交互仍然在局部的窗口内。最后一个图就是这个论文提出的 neighborhood attention transformer,NAT,所有 attention 的计算在7X7的邻域里进行。看起来和convolution一样,只是在一个 kernel 里面的范围内去做操作。但是和 convolution 不同的是,NAT里面是计算 attention,所以每一个 value 出来的权重是根据输入的这个值来决定的,而不是像卷积核里面那样训练好就固定的一个值。
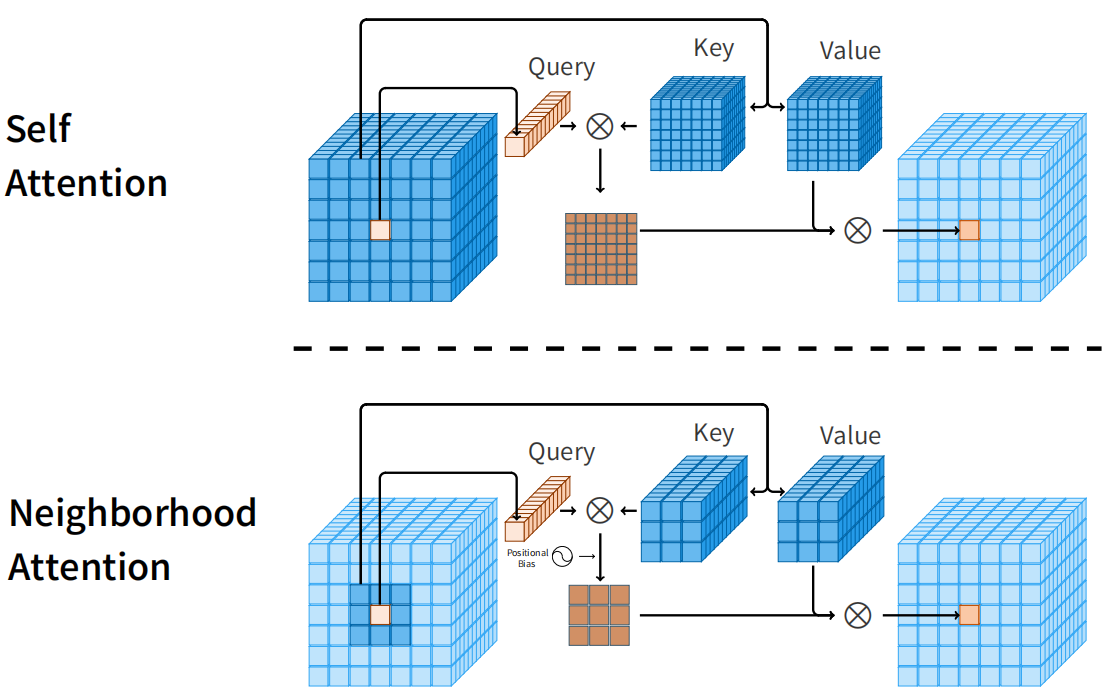
下面是自注意力与邻域注意力的比较,自注意力允许每个tokens关注所有其他tokens,而邻域注意力将每个tokens的接受域定位到其周围的邻域。对于CHW的输入矩阵,Query 是某个位置一个 1XC的向量, key 是一个 3x3xC 的矩阵,两个矩阵逐元素相乘(尺寸不同进行 broadcast ),结果是 3x3xC,最后在 C 这个维度求和,得到3X3的相似度矩阵。用这个矩阵给 value 分配权重 ,最后合并为一个 1x1xC 的向量,就是 attention 的计算结果。
将(i,j)像素位置的邻域定义为ρ(i,j),每个像素的NA计算公式为
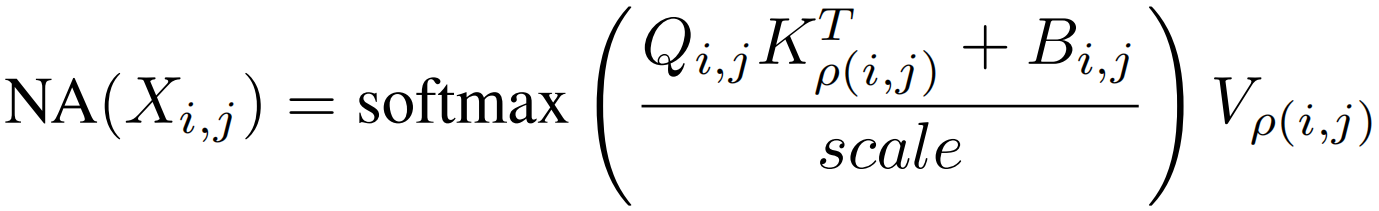
Q,K,V是X的线性投影,Bi,j表示相对位置偏差,当邻域超过输入大小时,就成了带额外位置偏差的自注意力。
网络的整体架构和当前方法一样,都是4阶段。每个阶段分辨率降低一半。不过,降分辨率使用的是 步长为2的 3X3 卷积。第一步 overlapping tokenizer 使用的是2个3x3卷积,每个卷积的步长为2。