
CLIP 改进工作串讲(下)学习笔记
1.图像生成
1.1CLIPasso(semantically-aware object sketching)
将物体的照片变成简笔画的形式,希望即使有最少的线条,也能识别出来物体。
问题定义,在纸上画几条随机初始化的曲线(bezier curve),通过不断的训练,希望这些曲线最后变成简笔画,贝兹曲线是通过空间上2维的点控制的一条曲线,论文中通过四个点去控制曲线,也就是笔画,然后通过模型训练更改点的位置,通过贝兹曲线的计算,就能慢慢改变曲线的形状,最终变成想要的简笔画的形式。
具体曲线的控制涉及图形学领域,不过多介绍,假设已经定义了S1....Sn这n条曲线,也就是n个笔画,然后把这n个笔画输入一个光栅化器rasterizer,rasterizer就能把这些笔画画到二维的画布上,变成一个我们能看懂的图像,模型中间部分都是图形学中有的,论文的主要贡献都在前面和后面部分,就是前面如何去做一个更好的初始化,后面如何选择一个更合适的loss function。
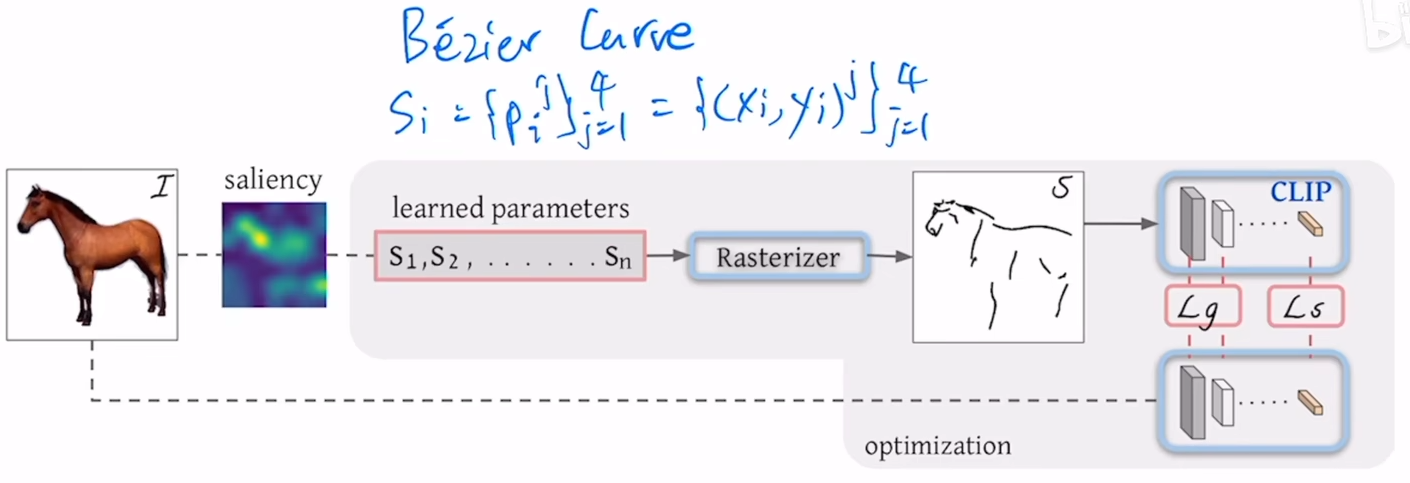
先讲一下目标函数,在得到马的简笔画图片后该怎么选择GT和目标函数呢?这里就是CLIP模型发挥作用的地方,这里借助了CLIP模型的稳健性,就是不论对原始的好的图像还是后面的简笔画图像,如果描述的都是同样的物体,比如说马,那通过CLIP模型得到的特征应该都是对马这个物体的描述,所以就应该让这两个特征尽可能地接近,也就是第一个loss,semantic loss。但是光有语义的一致性还不够,比如说如果得到的简笔画虽然是马,但是方向不对,那也不是想要的简笔画,所以应该还要再几何形状上对模型的输出进行一些限制,也就是第二个loss,Lg,具体来说,作者借鉴了之前一些low level视觉里的一些任务或者衡量指标,把模型前面几层的输出拿出来去算目标函数,因为前面的特征还有长,宽的概念,对几何的位置更加敏感,所以这里的Lg就是在CLIP预训练的模型前几层,去算简笔画图像和原始图像不同层之间特征的相似性。
这样虽然已经能够生成简笔画,但是作者发现点的初始化方式影响很大,所以作者想要一个比较稳定的初始化方式,让这个方法变得普适,所以在前面作者又提出了一个基于saliency的初始化方式,具体来说,就是用一个已经训练好的vision transformer,把原始图像输入这个vision transformer,然后把最后一层的多头自注意力取加权平均,得到一个saliency map,然后看map上哪些区域更显著,在这些显著的区域采点,最后的生成效果就能好很多。
虽然效果已经不错,但是作者还加了一个后处理的操作,自动地选择最后的那张final sketch,每次都是根据一张输入生成三张简笔画,然后根据之前提出的两个loss,去算这几张简笔画哪个能给出最低的loss,就选择那个简笔画作为最终的输出,
模型的两大卖点在于1.能对不常见的物体生成简笔画,之前的方法都只能对数据集里有的类别生成简笔画,现在可以对任意物体生成。2.可以控制抽象程度,也就是控制初始的贝兹曲线的数量。
局限性:1.当图像有背景的时候,模型的效果就会差很多,必须是一个物体处于纯白色的背景上,模型的效果才好。本文中是借助了automatic mask的方法,也就是U2Net,先把物体抠出来,生成前景是物体,背景是白色幕布的图片,再把图片输入CLIPasso。但是这种two-stage的方法不是最优结果,如果能把automatic mask的方式融合进模型,甚至提出一种新的loss函数或者模型的改进,去把带背景的图片也能解决地很好,那模型的适用范围就能广很多。2.初始化的笔画都是同时生成的,而不是序列生成的,这其实与人的习惯也不符,如果能先生成一个笔画,再根据这个笔画生成下一个,然后一步一步生成所有笔画,可能效果能更好。3.虽然能控制抽象程度,但是需要提前人为输入,而不同图片需要的抽象程度是不同的,即使想达到相同的抽象程度,需要的笔画数可能也是不同的。
2.视频领域
2.1CLIP4Clip(an empirical study of CLIP for end to end video clip retrieval)
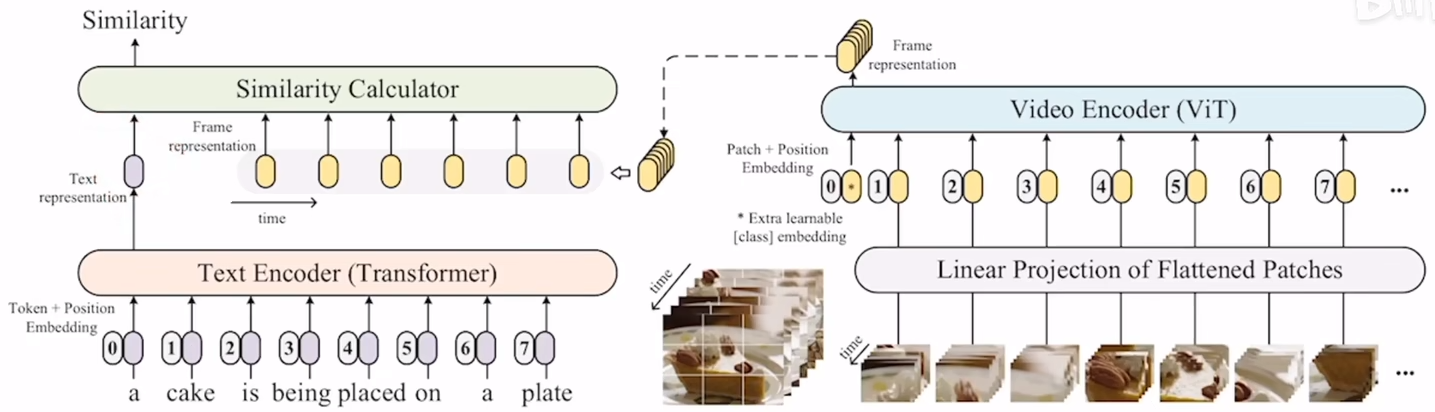
如果使用最简单的方法,直接把每一帧都单独地打成image patch,再把patch输入vit,然后去得到最后的cls token的话,得到的就不再是一个cls token,而是一系列的cls token,比如输入10帧,最后就会有10个cls token,也就是10张图片的整体特征,问题是之前是一个文本特征对应一个图像特征,现在是一个对十个,那么该怎么做相似性计算呢?这篇论文因为是empirical study,所以其实就是把已有的各种方式都尝试了一遍,看哪种方式的结果最好。论文中尝试了3种方式。
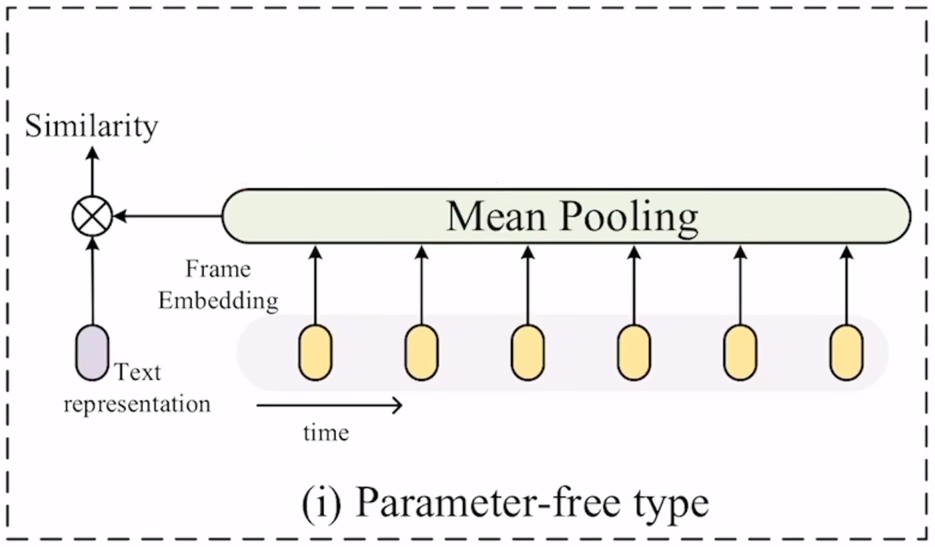
第一种是最简单的方式,而且是不带任何参数的,将10个图片特征直接取个平均就完事了,但是这种方式有个缺点,就是去平均的时候没有考虑时序的特性,比如最终得到的特征是无法区分一个人是在坐下还是站起。不过这种方式是目前最被广泛接收的方式。
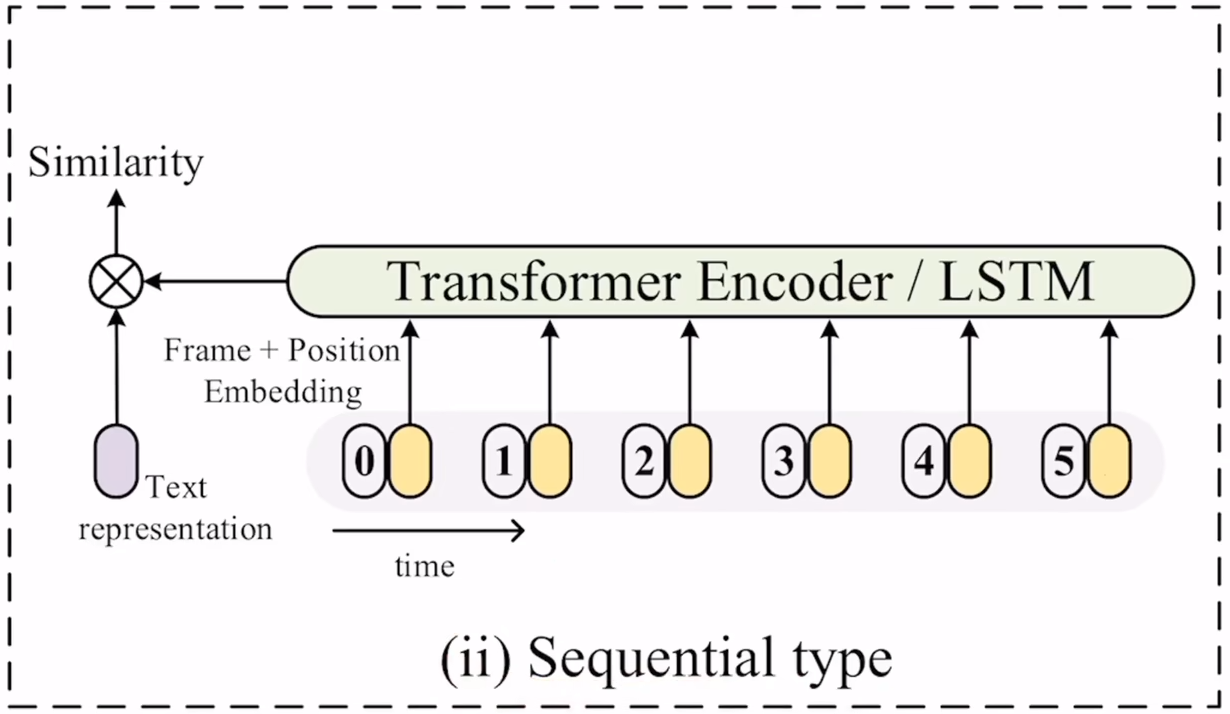
第二种方式作者把它叫做sequential type,就是考虑目前的目的其实就是两个,一个是把10个特征变成一个,另一个是加上时序特性,那想到时序建模,最原始的肯定就是lstm,把10个特征输入lstm,最后得到的就是一个特征,而且融合了时序信息,现在都用transformer去取代了lstm,只需要加上position embedding,就也能对时序进行建模。
第三种方式作者把它叫做tight type,其实就是在做early fusion,因为上一步在做sequential type的时候,其实做的是late fusion,就是其实已经把图像和文本的特征抽完了,只是在考虑最后怎么融合,但在该方式里,在最开始就进行融合,具体来说,就是文本带上文本的位置编码也输入到一个transformer,视频帧得到的特征加上位置特征也输入到这个transformer,把文本和图像的特征一起学习,然后通过一个MLP得到一个特征,再去算相似度。
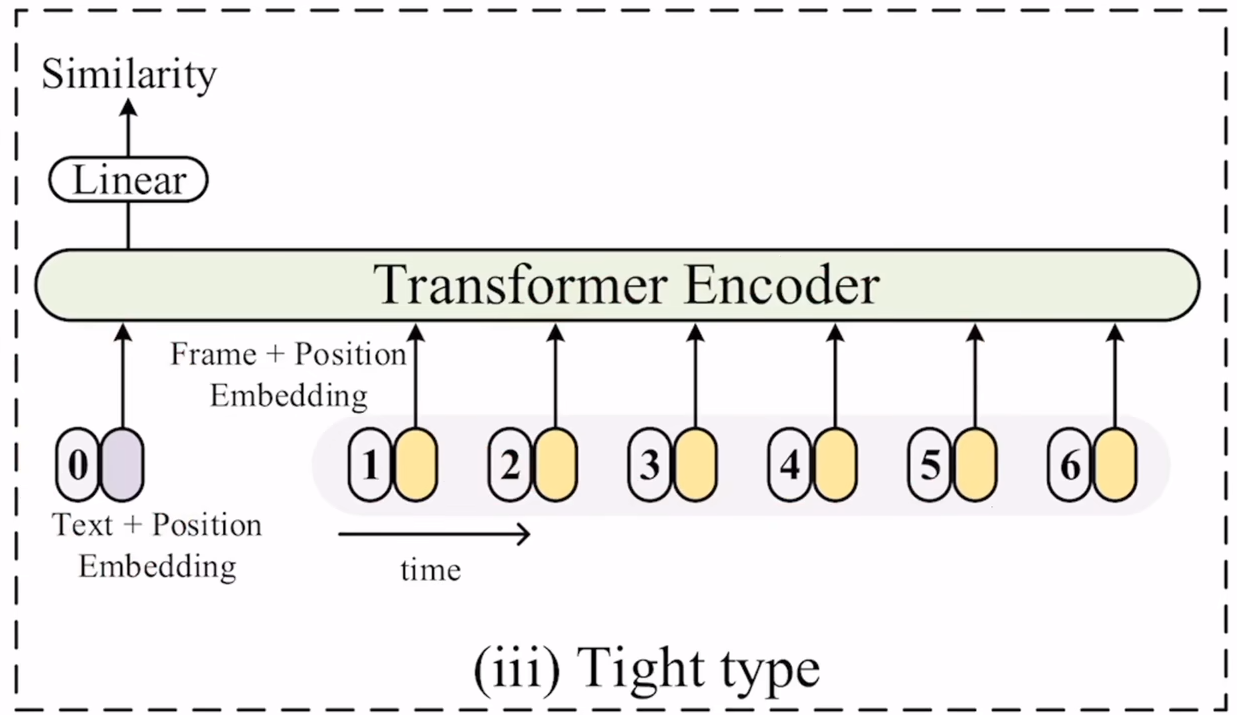
在实验部分可以看出,在数据量较少的时候,直接取平均的效果是最好的,因为CLIP的训练数据集很大,训练出来的效果已经很好了,这时候如果下游任务的数据集不大,做微调效果可能反而不好。但是当下游数据集不断增大之后,微调的效果就慢慢体现出来了,模型也就不那么容易过拟合了,所以后面的带参数的训练方式可能就会好一些,因为它更适合下游任务,但是差距并不显著,对比三种方式,第一种效果最好,第二种有时候效果也不错,第三种是完全不行。
insights:1.用CLIP的图像特征也是能够提升视频任务的。2.由于存在domain gap,如果能在视频这边找到足够多的训练数据再post pretrain一下,也就是说CLIP预训练完之后再在视频这边预训练一次,迁移效果就能好不少,但是这样计算代价也会高不少。3.对视频来说,也可以用2D的patch linear projection或者3D的patch linear projection,从实验来看,3D的patch linear projection会好一些,因为在一开始就融合了时序的信息,然后sequential type similarity也会好一些。4.对学习率非常敏感,现在在训练transformer的时候也发现,学习率基本上是最重要的超参数。
2.2ActionCLIP(a new paradigm for video action recognition)
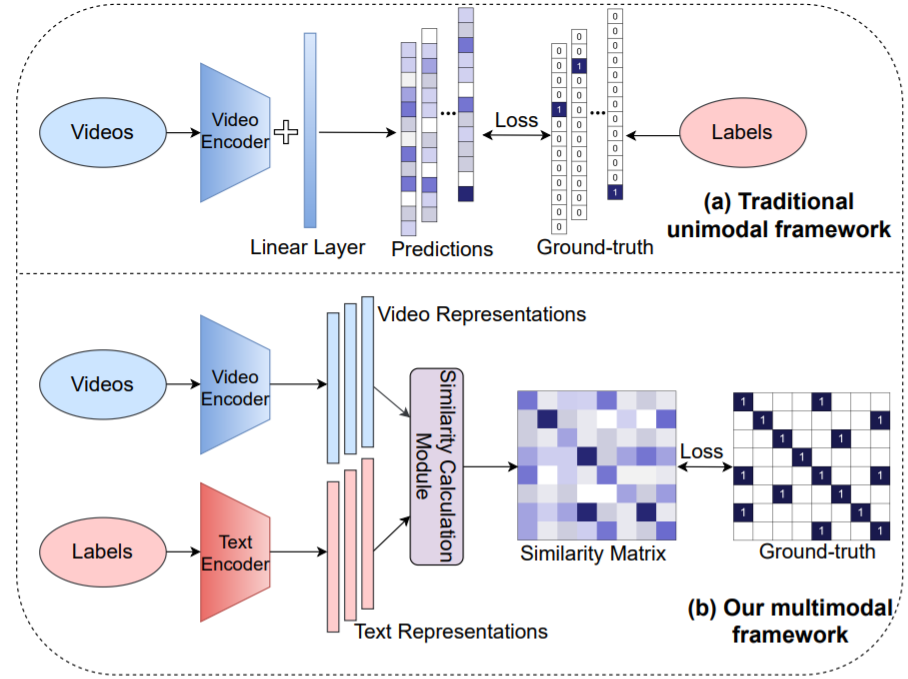
先看一下之前的方法视频理解领域动作识别是怎么做的,一般都是有一些视频,然后输入一个视频编码器,得到一个向量,然后输入一个分类头,得到输出,然后把输出与GT进行对比,算一个交叉熵损失,但是这里存在一个巨大的局限性,就是对于有监督学习来说,是需要标签的,但是对于动作识别来说,怎么定义这些标签,怎么去标记更多带标签的数据,这些都是非常困难的问题,因为对于目标识别来说,要标记的物体概念都是非常清晰的,桌子就是桌子,所以用one-hot标签是没什么问题的,但是对于动作识别来说就完全不一样,比如开门,开瓶盖这种变成一个短语了,而且开这个词能用来描述很多动作,潜在的label space是接近于无穷的,这就需要进行权衡,如果标记很多类的话,费用是很高的,而且softmax可能就不工作了,很难用常见的分类算法去做一个很好的模型,如果只标常见的类,那不常见或者细粒度的类又该如何处理,所以摆脱标签的束缚就是本文的研究动机,那用CLIP就很合理了。
图中下半部分就是作者提出的多模态框架,其实跟CLIP是非常像的,首先过一个视频的编码器得到一些特征,然后把标签当成文本,输入文本编码器得到一些文本的特征,然后算视频特征和文本特征的相似度,得到相似矩阵,然后与提前定义好的GT算一个loss就好了。
主要改进:1.如何把图像变成视频,也就是上半分支,这其实跟CLIP4Clip非常接近。2.CLIP是一个无监督的方法,它的GT是来自于网络上的匹配的图像文本对,每个图像文本对都是独立的,CLIP就是对角线上才是正样本,其他都是负样本,但是本文中就不一样了,因为这里的文本就是标好的标签,这就会出现一个问题,就是当batch比较大的时候,同一行或者同一列就会出现多个正样本,这个问题把交叉熵损失换成KL divergence就好了,利用两个分布的相似度去算loss。
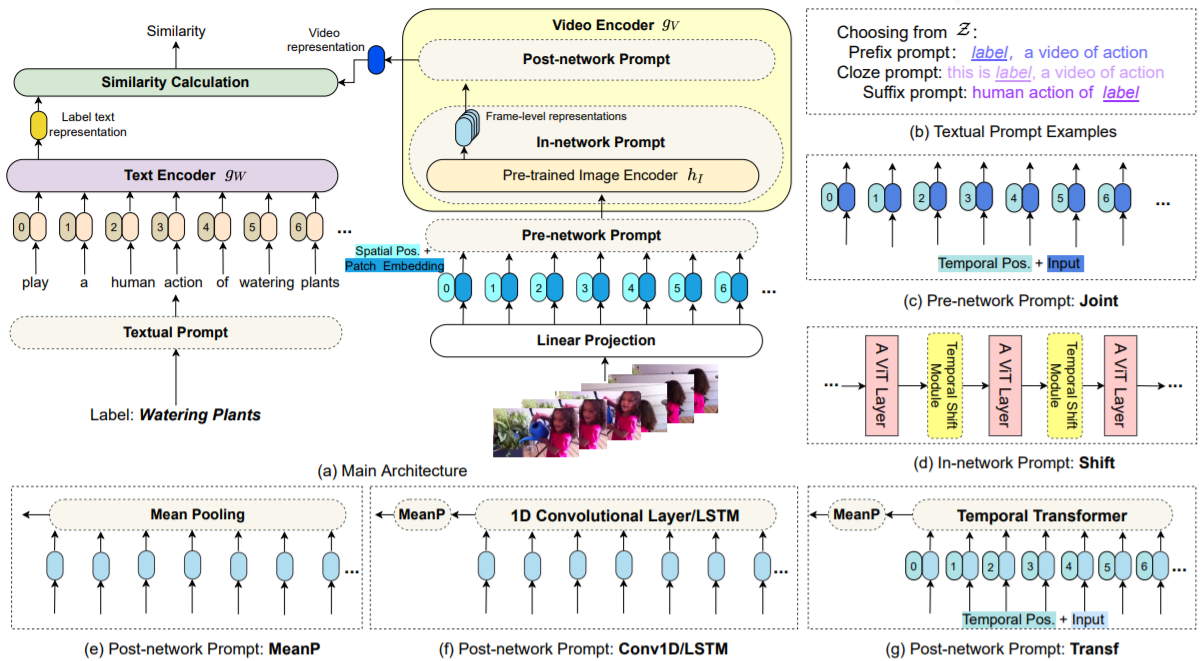
然后看主体方法部分,见下图,其实就是另一个改进,如何把CLIP迁移到视频领域来说动作识别。从整体的输入输出来看,跟CLIP或者CLIP4Clip都很像,文本标签先输入一个Textual Prompt,然后句子变成token输入一个文本编码器,得到一个单一的文本表示。视频这边也是视频的帧一个一个输入linear projection,得到一些vision token,然后输入一个pre-network prompt,然后输入视频的编码器,得到一个输出,然后视频输出和文本输出去算相似度就好了。
这里文本的prompt其实就是原始的prompt,但是视频这边已经不是原始prompt的意思了,这里这样写可能就是为了整体写作的连贯性,其实这里加的东西更像是加了adapter,不过prompt tuning,adapter,lora这些最近的efficient fine tuning的方法都非常接近了,这些方法的目的都是在原来已经训练好的预训练参数之上,加一些小的模块,然后通过训练这些小模块,能够然后已经训练好的模型参数能尽快迁移到下游任务上去。
为了与视频对应起来,文本这边也做了三种prompt,也就是右边这三种,主要看看视觉这边是怎么做的,首先最开始的这个pre-network prompt叫Joint,这个其实很简单,就是把时间和空间上的token都放在一起,直接输入网络进行学习,这里一开始也会把时序上的position embedding也加进去一起学,第二个in-network prompt其实就是利用了之前shift这个概念,这个概念最先在图像领域被提出,就是在特征图上做各种各样的移动,达到更强的建模能力,但是并不引入更多的参数,也不增加运行复杂度,19年tsm就把这个概念用到了时序领域,其实swin transformer也是利用了这个shift的概念,提出了shift window,这篇论文就把shift的操作拿过来,放到每一个ViT block的中间,也就是TSM模块,提高了时序建模的能力,但是不引入更高的计算量。最后是post-network prompt,其实这里跟CLIP4Clip是一模一样的,现在得到了很多的帧级表示,这里要跟文本特征做相似度计算,最好是先融合成一个视频级表示比较好。这里也用了三种方法,与CLIP4Clip都一样。
实验比较有意思的是文本这边的初始化没有什么关系,所以基本现在所有多模态的工作都把注意力放到了视觉这边,而且模型的初始化都是用vision ransformer去初始化而不是bert,另外文本段的prompt其实也没有什么影响,在视频这边,前两个prompt基本也没什么用,in-network prompt甚至可能拖了CLIP模型的后腿,唯一比较有用的就是post-network prompt。不过与CLIP4Clip中不同的是,平均池化的方法不太行,因为动作识别的训练数据集还是相当大的
3.总结
大家对于CLIP模型的使用可以分为三点:1.改动最小的情形,把图像或者文本通过CLIP得预训练模型的到一个特征,然后把这个特征跟原来的特征做一下融合,点乘或者拼接之类的,然后之前那个训练框架保持不动,只是用这个得到的更好的特征去加强之前的模型的训练。2.把CLIP模型当成一个teacher,把CLIP得到的特征来做蒸馏,无论是前面的特征还是最后的特征都可以蒸馏,这样无论是做什么任务,都可以拿2D的模型来蒸馏一些预训练好的知识,来帮助现有的模型收敛得更快。3.不太借助CLIP的预训练参数,只是借鉴这种多模态对比学习的思想,应用到自己的任务中来,定义自己的正样本对和负样本对,然后去算多模态的对比学习loss,从而实现多模态的分割或者识别。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话