Zero-Shot Temporal Action Detection via Vision-Language Prompting概述
0.前言
1.针对的问题
现有的方法在推断时只能识别之前见过的类别,即训练时出现过的类别,而为每个感兴趣的类收集和注释大型训练集是昂贵的。
2.主要贡献
(1)研究了如何利用大量预训练的ViL模型进行未修剪视频中的zero-shot时序动作定位(ZS-TAD)的问题。
(2)提出了一种新的one-stage分类定位模型STALE,该模型在并行分类和定位设计的同时引入了一个可学习的class-agnostic掩码组件,以实现zero-shot迁移到未见过的类。为了增强跨模态任务的自适应能力,在Transformer框架中引入了流间对齐正则化。
(3)在标准ZS-TAD视频基准上的大量实验表明,STALE优于最先进的类似方法,通常有很大的优势。此外,模型也可以应用于全监督TAD设置,并取得比最近的其他工作更优越的性能。
3.方法
主要特点是采用并行定位(掩码生成)和分类结构,以解决传统ZS-TAD模型的定位误差传播问题
模型结构如下:
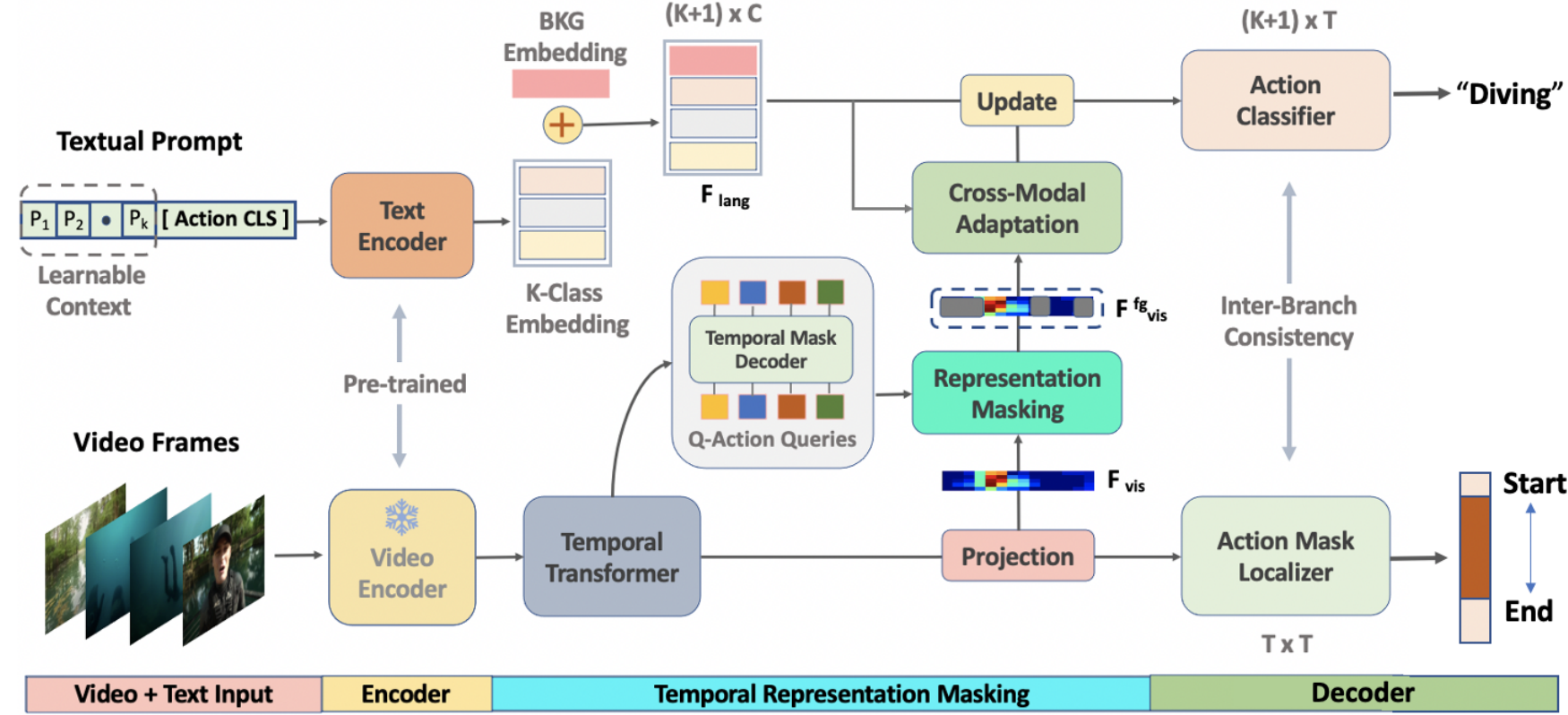
给定一个未裁剪的视频V,首先通过预训练的冻结视频编码器提取一组T个片段特征序列,包括RGB Xr ∈Rd×T和光流特征Xo ∈Rd×T,然后将它们连接为E = [Xr;Xo]∈R2d×T。虽然E(论文中是F,但是个人感觉这里应该是E)包含局部时空信息,但它缺乏对TAD至关重要的全局上下文,作者利用自注意力机制来学习全局上下文,将多头注意力编码器Τ()的输入(查询,键,值)设置为特征(E,E,E)得到最终的视频片段嵌入Fvis。
对于文本上下文,将其输入文本编码器,即带有可学习的提示的标准CLIP预训练的Transformer,得到嵌入Gke∈RC',由于背景类的文本嵌入不能直接从CLIP词汇表中获得,所以学习一个特定的背景嵌入,表示为Gbge∈RC',将其附加到嵌入的动作类Gke,得到包含K+1类的嵌入Flan。以上组成了输入和编码部分。
然后是时序表示掩码部分。将Fvis(代码中这里是E)输入一个transformer解码器来生成Nz潜在嵌入,然后将每个潜在嵌入通过一个掩码投影层(从代码中看是一个MLP),得到每个片段的掩码嵌入Bq ∈Rq×C,其中q代表query,将Bq与Fvis(图中的投影层论文中似乎并没有介绍)相乘再通过sigmoid函数得到关于每个查询的一个二进制预测Lq,将Lq输入一个线性层和sigmoid函数得到![]() (代码中好像没有这个线性层),在阈值θbin处对这个掩码进行二值化,并选择前景掩码,用
(代码中好像没有这个线性层),在阈值θbin处对这个掩码进行二值化,并选择前景掩码,用![]() 表示,使用
表示,使用![]() 检索嵌入Fvis的片段,获得前景特征Ffgvis。
检索嵌入Fvis的片段,获得前景特征Ffgvis。
将Ffgvis和Flan输入跨模态自适应模块,该模块由自注意层,co-attention层和前馈网络组成,公式为:![]() ,其中Tc为transformer层,以Flan为查询,Fvisfg为键和值。该模块鼓励文本特征在前景片段中找到最相关的视觉线索。然后,通过残差连接Flan和
,其中Tc为transformer层,以Flan为查询,Fvisfg为键和值。该模块鼓励文本特征在前景片段中找到最相关的视觉线索。然后,通过残差连接Flan和![]() 更新文本特征得到
更新文本特征得到![]() 。
。
最后是解码部分,该部分包括并行的分类流和定位流,定位流将Fvis输入动作掩码定位器,即3个(代码中是2个)1-D动态卷积层Hm的叠加,得到M,M的第t列是通过第t个片段进行的时序掩码预测。分类流的动作分类为器将更新后的文本特征![]() 和掩码前景特征Fvisfg相乘得到分类输出P∈R(K+1)×T,其中每个片段定位t∈T被赋予一个概率分布pt∈R(K+1)×1。
和掩码前景特征Fvisfg相乘得到分类输出P∈R(K+1)×T,其中每个片段定位t∈T被赋予一个概率分布pt∈R(K+1)×1。
类标签和掩码标签在前景方面有结构上的一致性,通过一致性损失来利用这种一致性,表示为 ,
,![]() = topk(argmax((Pbin∗Ep)[: K,:]))是从阈值分类得到的得分最高的前景片段中获得的特征,输出Pbin := η(p−θc)与θc 阈值,将嵌入E传递到一个1D conv层得到Ep,用于匹配p的维度。从掩码输出M中获得的最高评分特征类似于:
= topk(argmax((Pbin∗Ep)[: K,:]))是从阈值分类得到的得分最高的前景片段中获得的特征,输出Pbin := η(p−θc)与θc 阈值,将嵌入E传递到一个1D conv层得到Ep,用于匹配p的维度。从掩码输出M中获得的最高评分特征类似于:![]() = topk(σ(1DPool(Em * Mbin))),其中Mbin:= η(M−θm)是掩码预测M的二值化,Em通过将嵌入E传递到一维conv层以匹配维数M得到,σ为sigmoid激活函数。
= topk(σ(1DPool(Em * Mbin))),其中Mbin:= η(M−θm)是掩码预测M的二值化,Em通过将嵌入E传递到一维conv层以匹配维数M得到,σ为sigmoid激活函数。
