
D2-Net: Weakly-Supervised Action Localization via Discriminative Embeddings and Denoised Activations概述
1.针对的问题
目前大多数弱监督动作定位方法通常依赖于分离前景和背景区域(前-背景分离)学习TCAMs,但是在弱监督设置下,学习到的TCAM会存在噪声,而这些方法并没有明确地处理其噪声输出。
2.主要贡献
•引入了一个判别损失项,它同时进行视频分类和增强的前背景分离。
•引入去噪损失项来提高TCAMs的鲁棒性。去噪损失通过最大化视频内(intra-video)和视频间(inter-video)激活和标签之间的MI,明确解决了TCAM中的噪声问题。第一个引入了一个损失项,同时捕获一个视频中的多个片段和一个batch中所有视频的MI,以进行弱监督动作定位。
•在多个基准上进行实验,包括THUMOS14[7]和ActivityNet1.2[3]。D2-Net在所有数据集上优于现有的弱监督方法,在THUMOS14上IoU=0.5获得高达2.3% mAP的增益。
3.方法
模型结构比较简单,主要创新点在于提出的损失函数。
提出了两个损失项:判别损失和去噪损失。判别损失通过使用从输出T-CAMs计算的自顶向下的注意力,寻求最大程度地分离前景和背景片段并解决类别平衡问题。去噪损失通过处理激活中的前背景噪声来改善T-CAMs。这种损失使用来自潜在嵌入的前景得分的自底向上的注意力。
判别损失LDis:
首先通过自顶向下注意力计算前景嵌入和背景嵌入,公式如下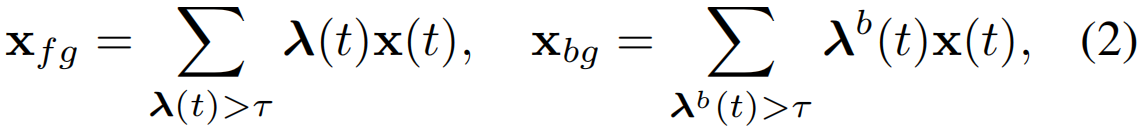
λb(t)=1−λ(t)是背景注意力。此外,引入了三个权重项wfb,wfg和wbg,分别针对分离前景和背景,聚合前景及聚合背景。
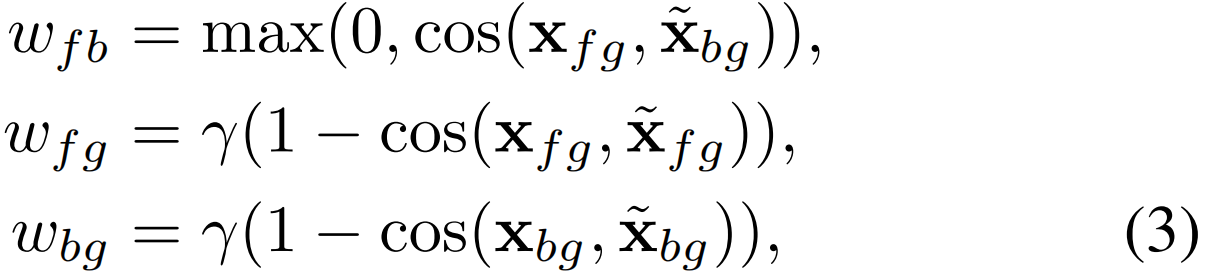
x和![]() 表示来自mini-batch中不同视频的嵌入,判别损失的另一个作用是解决类别平衡问题,即简单的背景片段的数量远远超过了困难的前景。受focal loss的启发,作者在判别损失中加入基于上面计算出来的权重的惩罚项。则判别损失定义如下:
表示来自mini-batch中不同视频的嵌入,判别损失的另一个作用是解决类别平衡问题,即简单的背景片段的数量远远超过了困难的前景。受focal loss的启发,作者在判别损失中加入基于上面计算出来的权重的惩罚项。则判别损失定义如下:
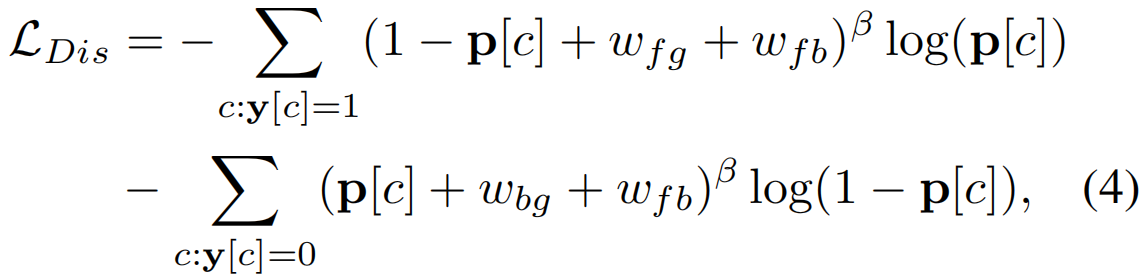
视频级预测p∈RC通过对T进行时序top-k池化获得,第一项表示只有当(i)其预测概率p[c]较高,以及(ii)对应视频的前景分组wfg和前景-背景分离wfb同时较低时,阳性动作类c造成的损失才较低。类似的观察也适用于第二项对负类的观察。因此,LDis通过鼓励前景-背景分离,同时实现分类,提高了嵌入x(t)的可辨别性。
去噪损失LD:
基于DMI(基于行列式的互信息)提出,用于提升对于噪声数据的鲁棒性,DMI是为多类分类提出的,计算为联合分布矩阵的行列式,即DMI(P, Y)=|det(U)|,U = 1/nPY是预测后验概率P和ground-truth (有噪声)标签Y的联合分布,DMI损失Ldmi被定义为
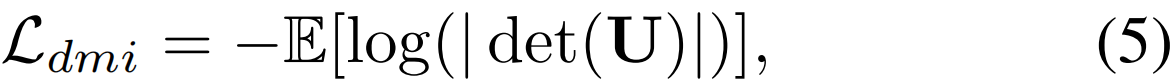
但是这种定义存在问题,Ldmi依赖于U的行列式,为了确保det(U)非零,标签矩阵Y必须是满秩的,即mini-batch必须包含所有类的实例。对于大量的类来说,这是不可行的。这种用于动作定位的mini-batch采样也会导致gpu中的内存问题。
根据公式,若要使Ldmi趋于0,则|det(U)|应趋于1,即U趋于单位矩阵,作者通过实验发现,若用ηU表示U的条件数,当|det(U)|越大,ηU越小,且当|det(U)|趋于1时,ηU也趋于1,因此作者对式5进行了修改,得到Lpdmi
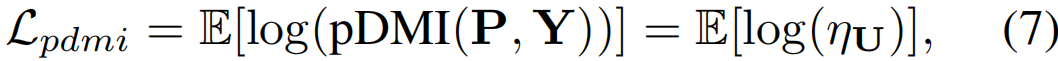
ηU计算为σ1/σr,其中{σ1,…,σr}为U的非零奇异值。
Lpdmi既用于一个视频的片段之间,也用于一个batch的所有视频之间,由于弱监督中得到的P和Y是视频级的,所以作者构造了片段的预测矩阵P1和伪标签矩阵Y1。先通过一种自底向上的注意力机制计算前景分数λ'(t)
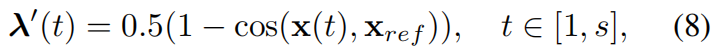
x[m]ref=0.9x[m−1]ref+0.1xµ,[m]bg逐步计算为xbg在m次迭代中的运行平均值。这里,xµ,[m]bg表示迭代m时一个MIni-batch中背景嵌入的平均值。令tf={t:λ'(t)>0.5}和tb={t:λ'(t)<0.5}。使用伪前景时序定位tf,一个宽度为nf=|tf|的行矩阵λf通过自顶向下注意力λ(t), t∈tf构造 。同样, 宽度为nb=|tb|的λb为伪背景片段构造。
则预测矩阵P1和伪标签矩阵Y1计算为
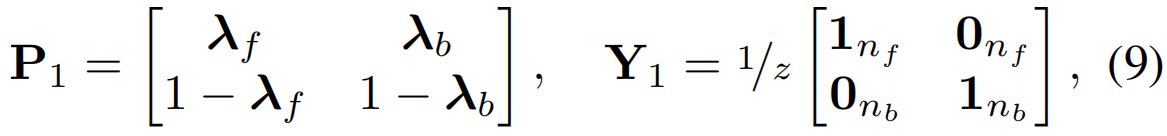
模型总体架构如下:
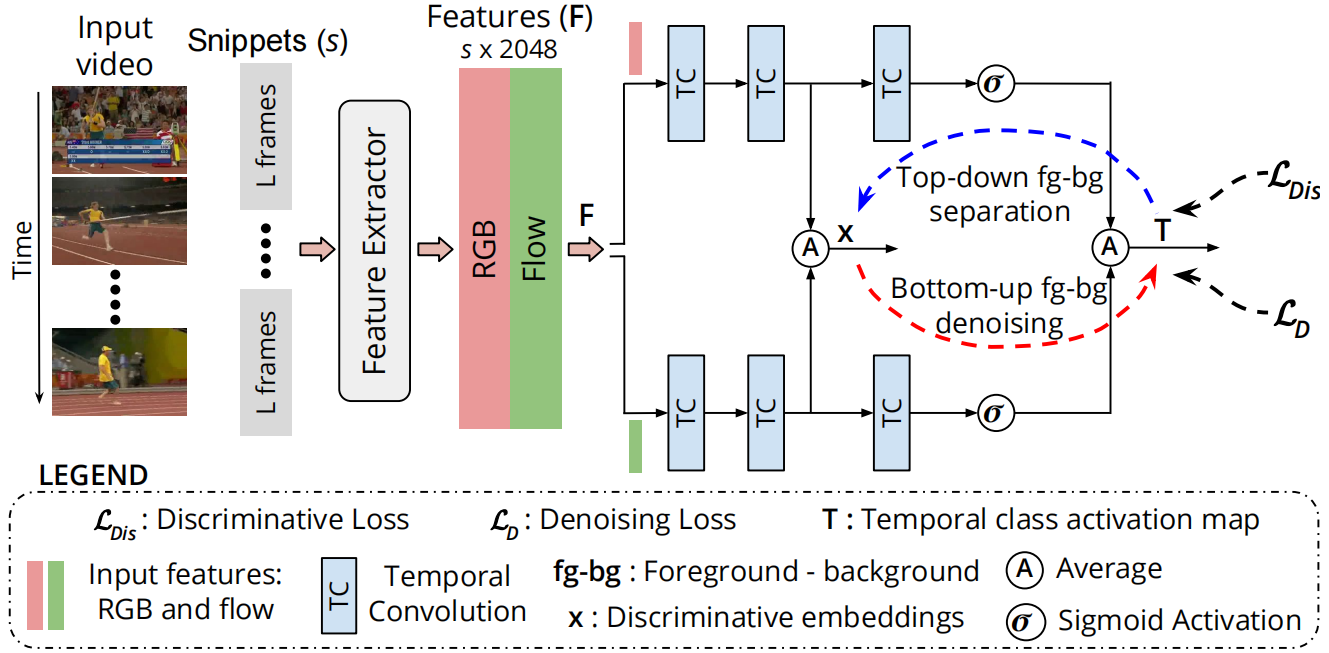
给定一个视频v,把它分成L = 16帧的互不重叠的片段。使用I3D获得每个16帧片段的d = 2048维特征F∈Rs×d,s为片段数,将特征输入D2-Net。
D2-Net由两个并行的RGB流和光流组成。每个流由三个时序卷积(TC)层组成。前两层从输入特征F学习潜在判别嵌入x(t)∈Rd/2(时间t∈[1,s]),最终TC层的输出通过sigmoid激活。随后,对两个流的输出进行平均,得到TCAMs T∈Rs×C 表示C个动作类随时间变化的class-specific得分序列。训练目标结合了判别(LDis)和去噪项(LD),并使用了一个平衡权重α。
