

Hide-and-Seek: Forcing a Network to be Meticulous for Weakly-Supervised Object and Action Localization概述
0.前言
1.针对的问题
大多数网络只识别图像最具有鉴别力的部分,不是所有相关的部分,导致性能不佳。
2.主要贡献
1)引入了弱监督定位的Hide-and-Seek思想,并在ILSVRC数据集上产生了最先进的目标定位结果。
2)证明了该方法在不同网络和层上的泛化性。
3)将这一思想扩展到相对未被探索的弱监督时序动作定位任务。
3.方法
关键思想是在训练图像中随机隐藏patch,当隐藏最具判别性的部分时,迫使网络去寻找其他相关的部分。
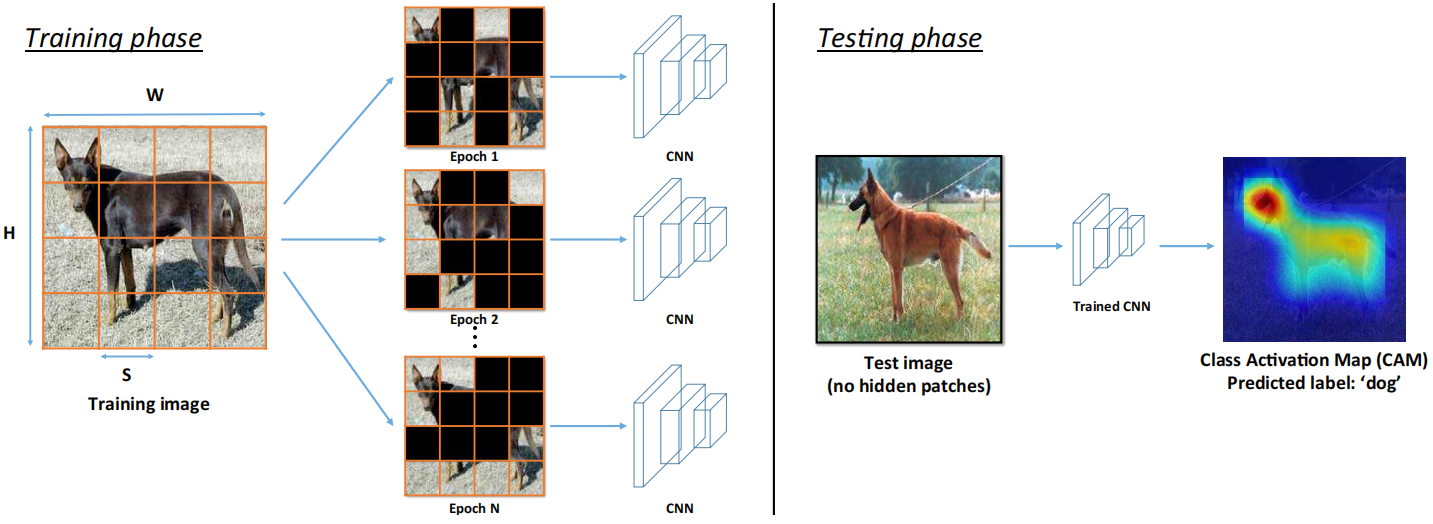
方法概述。左:给定一个训练图片I,大小为W×H×3,用一个固定大小的网格S×S×3划分图片。然后将每个patch以概率phide随机隐藏,并作为输入给CNN。对于同一张图片,在每个训练epoch,随机隐藏一组不同的块。右:在测试过程中,将没有任何隐藏补丁的完整图像作为训练网络的输入。
问题:由于训练时隐藏块与测试时不隐藏块的差异,第一个卷积层的激活在训练和测试时会有不同的分布。要使训练好的网路能够很好地泛化新的测试数据,其激活的分布要大致相等。也就是说,对于神经网络中的任何一个单元,只要它连接到x个单元,并且输出的权值为w,它的分布wTx在训练和测试期间要大致相同。然而,在文章的设置中,情况不一定是这样的,因为每个训练图像中的一些块将被隐藏,而每个测试图像中的块将不会被隐藏。
具体:
在文章的设置中,假设有一个卷积过滤器F,其内核大小为K×K。还有一个3维的权重W = {w1,w2,...,wk×k},其应用在图片I'的一个RGB块X = {x1,x2,...,xk×k}。向量v表示每个隐藏像素的RGB值。则有以下三种激活方式:
1.F完全在可见的块中(如下图中的蓝色方块),其对应输出为![]()
2.F完全在隐藏的块中(如下图中的红色方块),其对应输出为![]()
3.F部分在隐藏的块中(如下图中的绿色方块),其对应输出为![]()

在测试时,F永远在可见的块中,则输出为![]() ,这仅与第一种情况匹配。对于剩下两种情况,激活分布会与测试的不同。
,这仅与第一种情况匹配。对于剩下两种情况,激活分布会与测试的不同。
解决:通过设置隐藏像素的RGB值v等于整个数据集上图像的平均RGB向量来解决这个问题,公式如下:
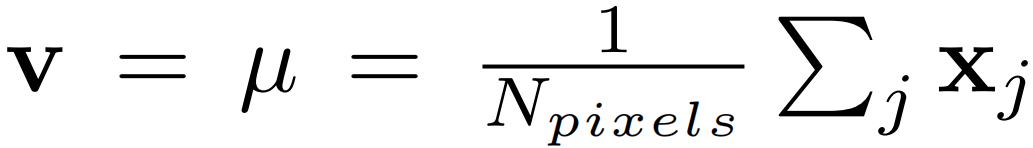
j表示整个训练集中所有的像素索引,Npixels表示总像素数。这样有效的原因是作者假设![]() ,在这种情况下,3种情况的输出近似。
,在这种情况下,3种情况的输出近似。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)