
UntrimmedNets for weakly supervised action recognition and detection概述
0.前言
1.针对的问题
这篇论文之前的行为识别方法严重依赖于修剪过的视频数据来训练模型,然而,获取一个大规模的修剪过的视频数据集需要花费大量人力和时间。
2.主要贡献
从未修剪的视频中引入一种更有效的直接学习动作识别模型的机制。
3.方法
框架流程图如下:
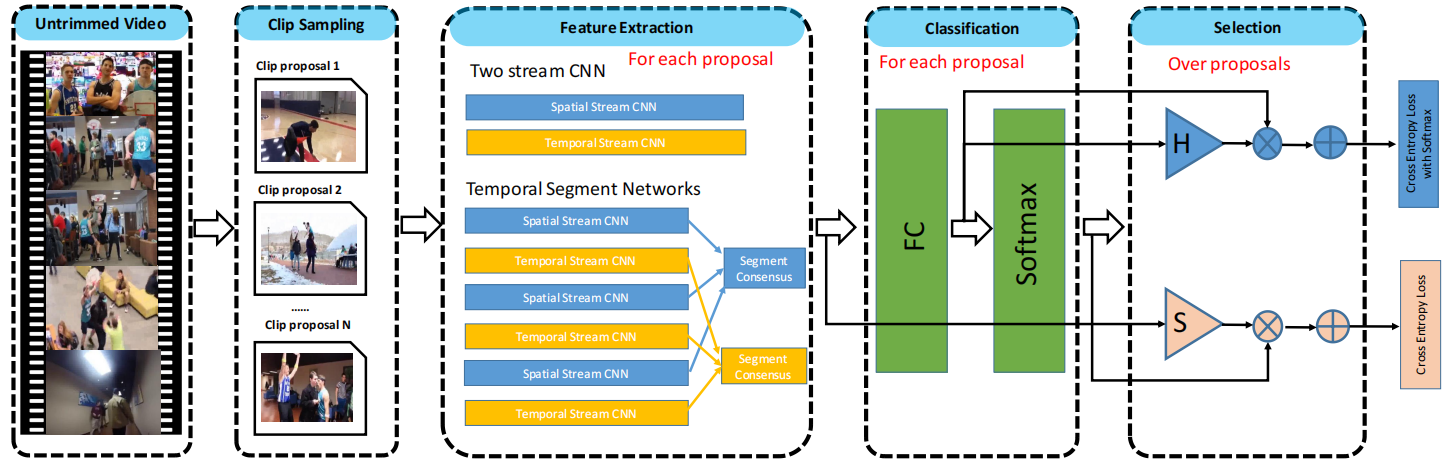
1.生成clip proposal,首先从完整的untrimmed视频中生成shot clip action proposal,论文中使用了两种生成proposal的方法:1、平均采样(Uniform sampling),即把视频均匀分成N段,没有利用到动作信息的连续性,生成proposal不准确。2、Shot-based 采样,先对每帧提取HOG特征,计算每一个当前帧与相邻帧之间的特征距离(绝对值),以此衡量视觉信息变化的程度。如果超过一定阈值,则视为检测到一个shot change,并划分出不同的shot(即以shot为单位粗略划分为不同动作段)。对每个shot内部再采样固定长度为K(设为300)帧的多个shot clips。假设有一个shot(用si=(sbi,sei)表示),根据![]() 从这个shot生成proposals。将这些proposal合并起来,作为UntrimmedNet的训练输入。
从这个shot生成proposals。将这些proposal合并起来,作为UntrimmedNet的训练输入。
2.特征提取模块,将生成的clip propsals分别经过特征提取网络(双流网络,或TSN)提取特征表示。给定一个包含一组clip proposals C={ci}Ni=1的视频V,我们为每个clip proposal c提取表示φ(V;c)∈RD。
3.分类模块,将proposal的特征输入FC层得到原始分类分数xc(c),c表示动作类别数,将原始分类分数输入softmax层得到softmax分类分数![]() 。
。
4.选择模块,图中selection块中的三角形部分,选出最有可能包含动作的clip proposal。分为基于MIL的hard selection和基于attention的soft selection。hard selection使用原始分类分数,选择原始分类得分最高的前k个实例,然后对这些被选择的实例进行平均得到hard selection score xsi(cj),表示对分类i,clip cj被选择的概率。soft selection使用softmax分类分数,利用注意力机制,对所有proposal学习一个用来排序的注意力权重,具体来说,对每个proposal的特征用一个线性层φ(c)进行变换,然后通过softmax层求得注意力分数,即soft selection score![]() 。
。
5.预测,结合classification score和selection score,生成untrimmed视频V的分类预测分数。对于hard selection,对每个分类的top-k个proposal的原始classification score,根据hard selection score取加权平均,再通过softmax得到预测分数,对于soft selection,利用学习的注意力权重,对soft classification score取加权平均得到预测分数。得到的预测分数使用交叉熵损失进行优化。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律