
ACM-Net: Action Context Modeling Network for Weakly-Supervised Temporal Action Localization概述
1.针对的问题
传统的方法主要侧重于前景和背景帧的分离,只有单一的注意力分支和类激活序列。然而,作者认为,除了独特的前景和背景帧外,还有大量语义模糊的动作语境帧。将这些上下文帧分组到同一个背景类是没有意义的,因为它们在语义上与特定的动作类别相关。
2.主要贡献
•与之前将视频帧仅划分为前景帧和背景帧的方法不同,作者认为存在一些语义模糊的动作上下文帧。本文研究了动作上下文建模对弱监督时间动作定位的影响,提出了一种动作上下文建模网络(ACM-Net)来实现动作上下文和动作示例的分离。
•提出的ACM网络集成了一个class-agnostic的三分支注意力模块,以测量同时包含动作示例、动作上下文和非动作背景帧的每个时间点的可能性。基于获得的注意力值,构建了三分支类激活序列,以实现动作示例、动作上下文和非动作背景的区分。
•在THUMOS-14和ActivityNet-1.3数据集上进行了大量实验。定性可视化结果证明了ACM网络在区分模糊动作示例和动作示例方面的有效性。定量结果表明,ACM网络优于当前最先进的方法,甚至可以实现与最近完全监督方法相当的性能。
3.方法
主要思想是对上下文进行建模,这里的上下文指的是语义模糊的帧,即在语义上与特定的动作示例相关,但又非明确动作的帧。
具体做法是通过集成一个三分支注意力模块,以同时测量每个时间点成为动作示例、上下文或非动作背景的可能性。然后,基于获得的三个分支注意力值,构建三个分支类激活序列,分别表示动作示例,上下文和非动作背景。
模型结构如下:
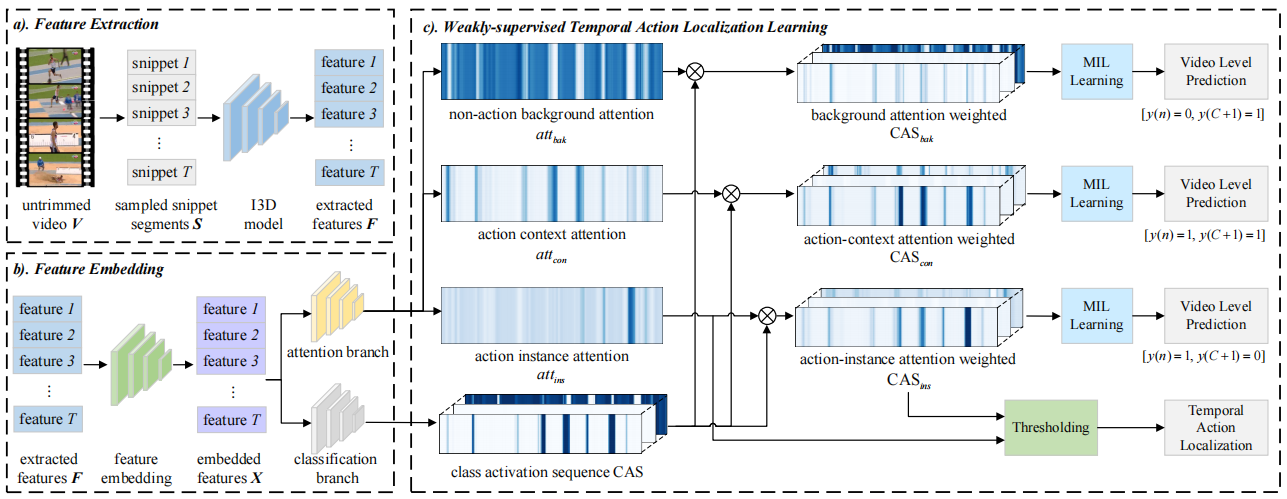
对给定的未修剪视频𝑉, 首先根据预定义的采样率将其划分为非重叠片段,然后应用预先训练好的网络来提取片段级特征。由于不同视频的时间长度不同,在训练过程中,使用插值操作来保持所有训练视频具有相同的时间维度𝑇, 即对于每个视频,将视频片段保持为𝑆={𝑠(𝑡)}𝑇𝑡=0。至于片段𝑠(𝑡)的特征提取,利用空间流(RGB)和时间流(光流)分别对静态场景特征𝐹𝑟𝑔𝑏(𝑡)∈R𝐷和动作特征𝐹𝑓𝑙𝑜𝑤(𝑡)∈R𝐷进行编码,之后,连接静态场景特征𝐹𝑟𝑔𝑏(𝑡)和动作特征𝐹𝑓𝑙𝑜𝑤(𝑡)形成片段特征𝐹(𝑡) = [𝐹𝑟𝑔𝑏(𝑡),𝐹𝑓𝑙𝑜𝑤(𝑡)] ∈R2𝐷。然后,将所有片段特征叠加,形成视频预训练特征𝐹∈R𝑇×2𝐷。
由于提取的特征𝐹没有为W-TAL任务从头开始训练,以便映射提取的视频特征𝐹到特定任务的特征空间,作者引入了一个特征嵌入模块。具体来说,使用一组卷积层和非线性激活函数来映射原始视频特征𝐹∈R𝑇×2𝐷到对应特定任务的视频特征𝑋∈R𝑇×2𝐷。
分类分支通过MLP获得类激活序列CAS,注意力分支通过一个三分支片段级动作注意力模块来检测class-agnostic动作示例,语义模糊上下文和非动作背景帧。具体来说,使用一个卷积层和softmax函数来测量每个片段包含动作示例,动作上下文或非动作背景的可能性,分别为𝑎𝑡𝑡𝑖𝑛𝑠(𝑡),𝑎𝑡𝑡𝑐𝑜𝑛(𝑡),𝑎𝑡𝑡𝑏𝑎𝑘(𝑡),将CAS分别乘以这三个值得到CAS𝑖𝑛𝑠,CAS𝑐𝑜𝑛和CAS𝑏𝑎𝑘,以区分动作示例,上下文和动作背景帧。
