
代码随笔
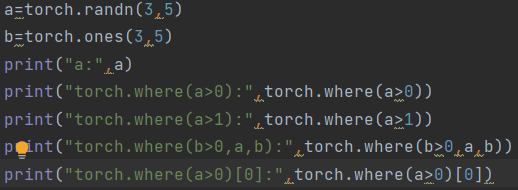
1.torch.where(condition,x,y)
有两种情况:
1.包含三个参数,如果condition为true,则 value值为x; 如果condition为false,则 value值为y;
2.若只包含condition参数,若进行判断的是一个n维张量,则返回一个元组,包括n个tensor,第x个tensor为满足条件的元素在第x维度上的位置,可以通过下标的方式获取到特定tensor。
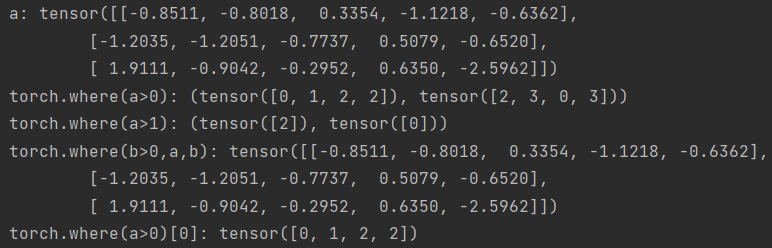
2.numpy.array.size, numpy.array.shape和torch.tensor.size(),torch.tensor.shape
numpy中,size计算数组和矩阵中所有元素的个数,shape计算矩阵每维的大小
torch中,torch.size()和torch.shape结果是一样的,通过torch.size(0)与torch.shape[0]获取第0维大小。

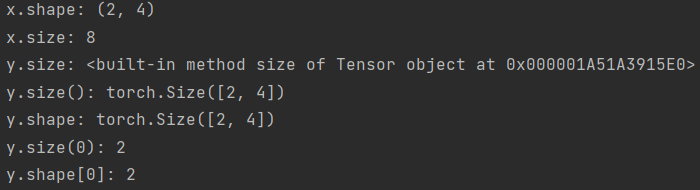
3.切片相关
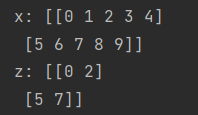
x[a:b:c]:从a取到b,步长为c,另外x[b]不会被取到,在下图中,要取到全部5列。应为0:5。
4.torch:transpose(),permute(),view(),reshape(),contiguous(),squeeze(),unsqueeze(),repeat()
torch.permute可以对任意高维矩阵进行转置,类似给每个维度设置一个索引,如(2,3,5)经过permute(2,0,1)后变为(5,2,3)
torch.transpose只能操作2D矩阵的转置(就是每次transpose()只能在两个维度之间转换,其他维度保持不变),连续使用transpose()也可实现permute()的效果。如(2,3,4,,5)经过transpose(3,0)后变为(5,3,4,2),transpose(2,1)后变为(5,4,3,2),transpose(3,2)后变为(5,4,2,3)
torch.squeeze移除指定或所有维数为1的维度,得到维度减少的张量,torch.unsqueeze在张量的指定维度插入新的维度得到维度提升的张量(CSDN)
torch.view与reshape、resize类似,重新调整Tensor的形状为参数,有一个特殊用法是传入参数某一个维度为-1,代表自动调整该维度上的元素个数,以保证元素的总数不变。
repeat():参数个数与tensor维数一致时,repeat的参数是对应维度的复制个数,不一致时,先在第0维扩展一个维度,维数为1,然后按照参数指定的次数进行复制(参考CSDN)
5.torch:eye(),empty(),empty_like(),scatter(),scatter()_,clamp(),flatten(),gather(),nonzero(),numel(),meshgrid(),cdist(),diagonal()
clamp(input,min,max,out=None)函数的功能将输入input张量每个元素的值压缩到区间 [min,max],并返回结果到一个新张量。
scatter(output, dim, index, src)函数就是把src数组中的数据重新分配到output数组当中,index数组中表示了要把src数组中的数据分配到output数组中的位置,若未指定,则填充0,dim=1表示数据位置发生的变化都是在第1维上,第0维不变。若dim=0,则同理变换input第一维的下标。(参考CSDN)
flatten()把指定维度及其后面的维度合并到一起,例如


若输入为两个维度,即flatten(start_dim, end_dimension),则是将从start_dim到end_dim之间的所有维度值乘起来,其他的维度保持不变。
gather(input, dim, index=):将index的坐标用index的对应值取代,dim=0则取代行,dim=1取代列,得到对应坐标,如index=[a,b,c]的坐标index1为(0,0),(0,1),(0,2),按行取代之后为index2:(a,0),(b,0),(c,0),得到这个index2后,将input的index2的对应值填到index1对应坐标的位置。(参考知乎,CSDN)
nonzero():返回一个包含输入input中非零元素索引的张量.输出张量中的每行包含input中非零元素的索引。如果输 input有n维,则输出的索引张量out的 size 为z×n, 这里z是输入张量input中所有非零元素的个数(参考CSDN)
numel():获取tensor中一共包含多少个元素。
meshgrid():功能是生成网格,可以用于生成坐标。函数输入两个数据类型相同的一维张量,两个输出张量的行数为第一个输入张量的元素个数,列数为第二个输入张量的元素个数。其中第一个输出张量填充第一个输入张量中的元素,各行元素相同;第二个输出张量填充第二个输入张量中的元素各列元素相同。(参考CSDN)
cdist(x1,x2,p):批量计算两个向量集合的距离,如果x1的shape是 [B,P,M], x2的shape是[B,R,M],则cdist的结果shape是 [B,P,R],p=1代表L1距离,默认为2,为欧几里德距离。(参考CSDN)
diagonal():获取tensor的对角线元素,offset参数,用来控制提取哪一条对角线。如果offset=0,就是主对角线;如果offset>0,就是主对角线上方的对角线;如果offset<0,就是主对角线下方的对角线。如果是超过两维的tensor,可以通过dim1和dim2参数来表示想要提取对角线的那两个维度
6.torch.utils.data.DataLoader
需要有一个类,假如为dataset,继承data.Dataset,然后实现__len__()和__getitem__()两个方法,若loader = data.DataLoader(...),第一个参数传入dataset(),则data.DataLoader(...)返回值与__getitem__()的返回值相同。在使用时,可以直接通过for 。。。 in data_loader获取数据,也可通过for i (。。。) in enumerate(data_loader)获取到step和数据,因此,如果要每step输出一次结果,应该在该循环下进行。
7.VScode
Ctrl+[和Ctrl+]实现文本的向左移动或者向右移动; Shift+Alt+F实现代码的对齐;Ctrl+Shift+P选择编译器。
8.nn.Softmax()与nn.LogSoftmax()
nn.Softmax()计算出来的值,其和为1,也就是输出的是概率分布,具体公式如下:
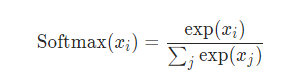
这保证输出值都大于0,在0,1范围内。而nn.LogSoftmax()公式如下:
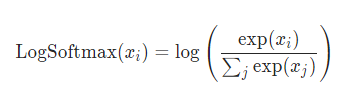
由于softmax输出都是0-1之间的,因此logsofmax输出的是小于0的数。
9.nn.Linear,nn.BatchNorm1d,torch.norm和F.normalize
在处理三维数据时,如动作检测中特征为(B,T,D),nn.Linear初始化时的第一个参数要与D相同,如果不同,则认为输入的是二维数据,默认将前两个维度相乘转换为二维数据,在使用时传入的x的最后一个维度为D。
nn.BatchNorm1d的参数要与T相同,在使用时传入的x的最后一个维度为T,所以在使用时,当两个模块连着的时候需要在中间转换维度,nn.BatchNorm1d可以处理二维或三维数据,二维时数据应为(B,D),输入参数与D相同,且输入特征与输出特征维度相同。
torch.norm第一个参数为输入的tensor,第二个参数为范数类型,默认为L2范数,第三个参数指定维度,nn.BatchNorm1d是对每个元素进行归一化,不会改变tensor的维度,torch.norm根据第四个参数keepdim判断是否改变tensor的维度,默认改变,指定的维度消失。
F.normalize参数与torch.norm类似,但不会改变维度。
10.广播机制(参考CSDN)
广播时将tensor向右对齐,并从右向左看,每个维度需满足以下任一:
a.这两个维度的大小相等
b.某个维度 一个张量有,一个张量没有
c.某个维度 一个张量有,一个张量也有但大小是1
11.nn.CrossEntropyLoss()
nn.CrossEntropyLoss()中两个参数,其中的第二个参数也就是label必须为long型(int64)的,不能是float32,且不能是one-hot格式,函数内部自己会处理成one-hot格式。
12.torch中的乘法:乘号(*),@,torch.mul(),torch.mm() ,torch.bmm(),rorch.matmul()(参考CSDN,CSDN)
*和torch.mul()为点乘,即对应元素相乘,可以广播,@为矩阵乘,是matmul的另一种写法,torch.mm(),torch.bmm()和torch.matmul()是矩阵乘法,第一个是针对二维矩阵,第二个专门进行batch形式的矩阵乘法,要求1.输入只能是3维矩阵(batch,d1,d2);2.第0维相同。最后一个是高维矩阵乘,支持广播,对于维数相同的张量,如3维,要求第一维度相同,后两个维度能满足矩阵相乘条件,如A.shape =(b,m,n);B.shape = (b,n,k),numpy.matmul(A,B) 结果shape为(b,m,k)。
13.ModuleList和Sequential(参考知乎)
1.nn.Sequential内部实现了forward函数,因此可以不用写forward函数。而nn.ModuleList则没有实现内部forward函数。
2.nn.Sequential可以使用OrderedDict对每层进行命名
3.nn.Sequential里面的模块按照顺序进行排列的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起,这些模块之间并没有什么先后顺序可言。
4.有的时候网络中有很多相似或者重复的层,一般会考虑在一个列表中用 for 循环来创建它们,然后再放入nn.ModuleList
此外nn.ModuleList不能用list代替,因为使用 Python 的 list 添加的卷积层和它们的 parameters 不会自动注册到网络中。
14.torch.einsum(参考知乎)
爱因斯坦求和约定:用于简洁的表示乘积、点积、转置等方法。
15.F.interpolate(参考CSDN)
利用插值方法,对输入的张量数组进行上\下采样操作,换句话说就是科学合理地改变数组的尺寸大小,尽量保持数据完整。
16.cumsum函数(参考CSDN):
cumsum(a, axis=None, dtype=None, out=None)
a.cumsum(axis=None, dtype=None, out=None)
返回:沿着指定轴的元素累加和所组成的数组,其形状应与输入数组a一致,第i 个输出元素值为 yi=x1+x2+x3+…+xi
17.softmax中常出现的温度系数T
随着T的减小,softmax输出各类别之间的概率差距越大(陡峭),从而导致loss变小;同样,当增大T,softmax输出的各类别概率差距会越来越小(平滑),导致loss变大。
18.tqdm
19.Pytorch nn.Parameter()(参考CSDN)
torch.nn.Parameter是继承自torch.Tensor的子类,其主要作用是作为nn.Module中的可训练参数使用。它与torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而module中非nn.Parameter()的普通tensor是不在parameter中的。
20.nn.Conv1d(参考CSDN,CSDN)
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
有多少个out_channels,就需要多少个1维卷积,卷积是在最后维度上扫的,in_channels要与输入特征的倒数第二个维度一致,如果用一个𝑓×𝑓的过滤器卷积一个𝑛×𝑛的图像,padding为𝑝,步幅为𝑠,输出为 ![]() 。
。
groups用于分组卷积,groups的值必须能整除in_channels和out_channels,group conv最早出现在AlexNet中,因为显卡显存不够,只好把网络分在两块卡里,于是产生了这种结构;Alex认为group conv的方式能够增加filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
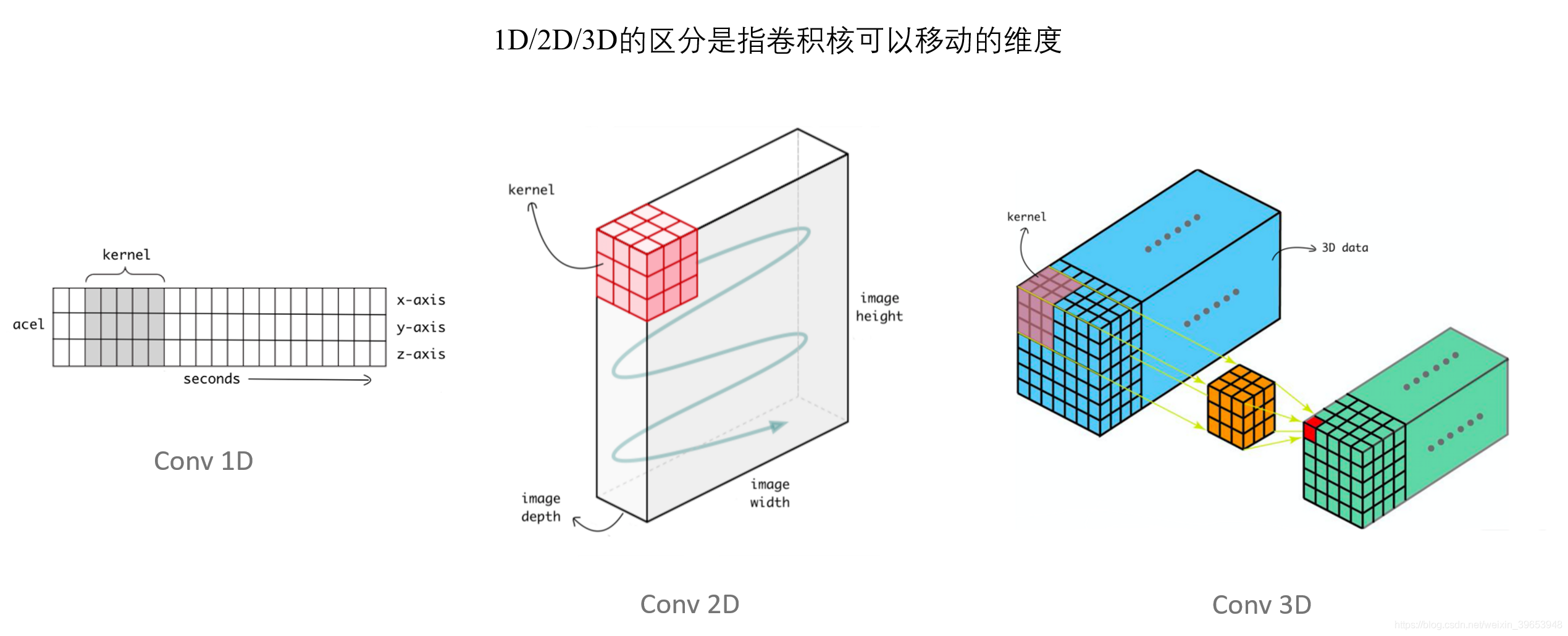
1D,2D,3D的区别在于卷积核可移动的维度(参考CSDN)
21.torch.nn.identity()(参考CSDN)
输出与输出相同,不做任何的改变。是不区分参数的占位符标识运算符。放到最后一层后面显得没有那么空虚,因为前面的层后面都有个激活函数,就最后一层后面啥都没有所以放个Identity占位
22.tar -zxvf
通过tar -zcvf打包为tar.gz文件,打包时同样最好进入要打包文件的上级目录进行打包,否则最后解压出来的文件会包含输入的所有目录,如
tar -zcvf xxx.tar.gz /home/xxx/project/xxx,解压出来是home/xxx/project/xxx。tar.gz文件通过tar -zxvf命令解压。
23.F.pad()(参考CSDN)
F.pad() 是pytorch内置的 tensor 扩充函数,便于对数据集图像或中间层特征进行维度扩充。包括四个参数:input--需要扩充的tensor,pad--扩充维度,mode--扩充方法,value--扩充的值。pad的参数个数需要是2的倍数。
扩充是从最后一个维度开始的,当参数pad只定义两个参数,表示只对输入矩阵的最后一个维度进行扩充,pad的第一个参数代表左边填充数,第一个参数代表右边填充数。四个参数时扩充后两个维度。
比如input维度为(1, 3,5 ,3),pad = (1, 2, 3, 4, 5, 6),则最后得到的tensor维度为(1, 14, 12, 6),
24.nn.AdaptiveAvgPool2d(output_size)(参考CSDN)
output_size:可以为tuple类型(H, W),也可以为一个数字H表示(H, H),H,W可以为int或者None类型,如果是None默认与输入相同大小,最终得到的结果最后两个维度与H,W相同。
25.装饰器(参考CSDN,CSDN)
装饰器本质上是一个Python函数(其实就是闭包),它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。用于以下场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
如果在now函数前加上@log,相当于执行了语句:now = log(now),原来的 now() 函数仍然存在,只是现在同名的 now 变量指向了新的函数,于是调用 now()将执行log()函数。
当有多个装饰器时,如在now函数前加上@log,再加上@mylog,相当于执行了语句:now =mylog(log(now))
26.argparse模块
可以把argparse的使用简化成下面四个步骤(参考博客园)
1:import argparse
2:parser = argparse.ArgumentParser()
3:parser.add_argument()
4:parser.parse_args()
首先导入该模块;然后创建一个解析对象;然后向该对象中添加要关注的命令行参数和选项,每一个add_argument方法对应一个要关注的参数或选项;最后调用parse_args()方法进行解析;解析成功之后即可使用。
parse_known_args()(参考CSDN):作用就是当仅获取到基本设置时,如果运行命令中传入了之后才会获取到的其他配置,不会报错;而是将多出来的部分保存起来,留到后面使用,如下:
import argparse def basic_options(): parser = argparse.ArgumentParser() parser.add_argument('--data_mode', type=str, default= 'unaligned', help='chooses how datasets are loaded') parser.add_argument('--mode', type=str, default='test', help='test mode') return parser def data_options(parser): parser.add_argument('--lr', type=str, default='0.0001', help='learning rate') return parser if __name__ == '__main__': parser = basic_options() opt, unparsed = parser.parse_known_args() print(opt) print(unparsed) parser = data_options(parser) opt = parser.parse_args() print(opt)
输出为:
(deeplearning) userdeMacBook-Pro:pytorch-CycleGAN user$ python test_data.py --data_mode aligned --lr 0.0002 Namespace(data_mode='aligned', mode='test') ['--lr', '0.0002'] Namespace(data_mode='aligned', lr='0.0002', mode='test')
parse_args()函数的返回值可以访问到每个参数值,除此之外,通过set_defaults()函数可以设置一些参数的默认值,get_defaults()方法可以获取add_argument()和set_defaults()中设置的默认值。(参考CSDN)
不以 - 或 -- 开头的,是必须配置的位置参数,这里需要注意的是,位置参数设置了default还是会报错,加上nargs='?'或改成可选参数后错误解决。
27.np.finfo(),np.diff()
np.finfo(type)生成type类型的float型,.eps取非负的最小值,常用于替换需要非负的变量,如除法的分母,或者log的变量。(参考CSDN,CSDN)
np.diff(arr,n):arr数组从第二个元素开始,每个元素减去前一个元素。n表示重复这个过程几次(参考CSDN)
28.scipy.signal.find_peaks(参考CSDN)
该函数用于寻找波峰,参数及使用案例在参考中有介绍,这里需要注意的是,height参数不能为tensor类型,当该参数为numpy时,需要输入一对参数,也就是上下边界,不过可以不输入值。
29.os.path.join()
如果不存在以'/'开始的参数,则函数会自动加上, 存在以'/'开始的参数,从最后一个以'/'开头的参数开始拼接,之前的参数全部丢弃,总的来说,要么都别加,参数结尾加不加没关系,但是开头要注意。参考(CSDN)
30.torch.zeros_like与torch.zeros
两个都是用来创建全0tensor,虽然zeros_like不用输入每个维度的值,但是速度似乎要慢一些。


31.python的joblib.Parallel(参考CSDN)
Joblib是一个可以将Python代码转换为并行计算模式的包,可以大大简化我们写并行计算代码的步骤。Parallel参数确定进程数,delay调用的函数及传入函数的参数,如下面这段代码
Parallel(n_jobs=3)(delayed(single)(i) for i in range(10))
创建三个进程,调用single函数,single函数的参数为0-9。运行时间相比顺序执行大大减小,但是由于进程切换等操作的时间开销,最终的执行时间并不是顺序执行时间/3。
