
Two-Stream Consensus Network for Weakly-Supervised Temporal Action Localization概述
1.针对的问题
在没有帧级注释的情况下,W-TAL方法很难识别假阳性的动作建议,并生成具有精确时间边界的动作建议。具体来说,之前的W-TAL方法所面临的最关键的问题之一是缺乏排除假阳性动作建议的能力。如果没有帧级注释,它们会定位不一定与视频级标签对应的动作示例。例如,模型可能仅通过检查场景中是否存在水来错误定位动作“游泳”。因此,有必要利用更细粒度的监督来指导学习过程。另一个问题在于动作建议的制定。在以前的方法中,动作建议是通过使用一个固定的阈值对激活序列进行阈值化来生成的,该阈值是根据经验预设的。它对动作建议的质量有重大影响:高阈值可能会导致动作建议不完整,而低阈值可能会带来更多误报。但如何走出这一困境却鲜有研究。
2.主要贡献
-为W-TAL引入了双流共识网络(TSCN)。所提出的TSCN使用迭代细化训练方法,其中由前一迭代中的late fusion注意力序列生成的伪ground-truth可以为当前迭代提供更精确的帧级监督。
–提出了一个注意力归一化损失函数,它迫使注意力像二进制选择一样,从而提高了阈值方法生成的动作建议的质量。
–在两个标准baseline(即THUMOS14和ActivityNet)上进行了大量实验,以证明所提出方法的有效性。TSCN显著优于之前最先进的W-TAL方法,甚至与最近一些完全监督的TAL方法取得了相当的结果。
3.方法
提出的TSCN具有一种迭代优化训练方法,其中帧级伪ground-truth被迭代更新,并用于为改进的模型训练和误报动作建议消除提供帧级监督。此外,提出了一种新的注意力归一化损失,以鼓励预测的注意力权重接近二进制选择,并促进动作实例边界的精确定位。
模型流程如下:
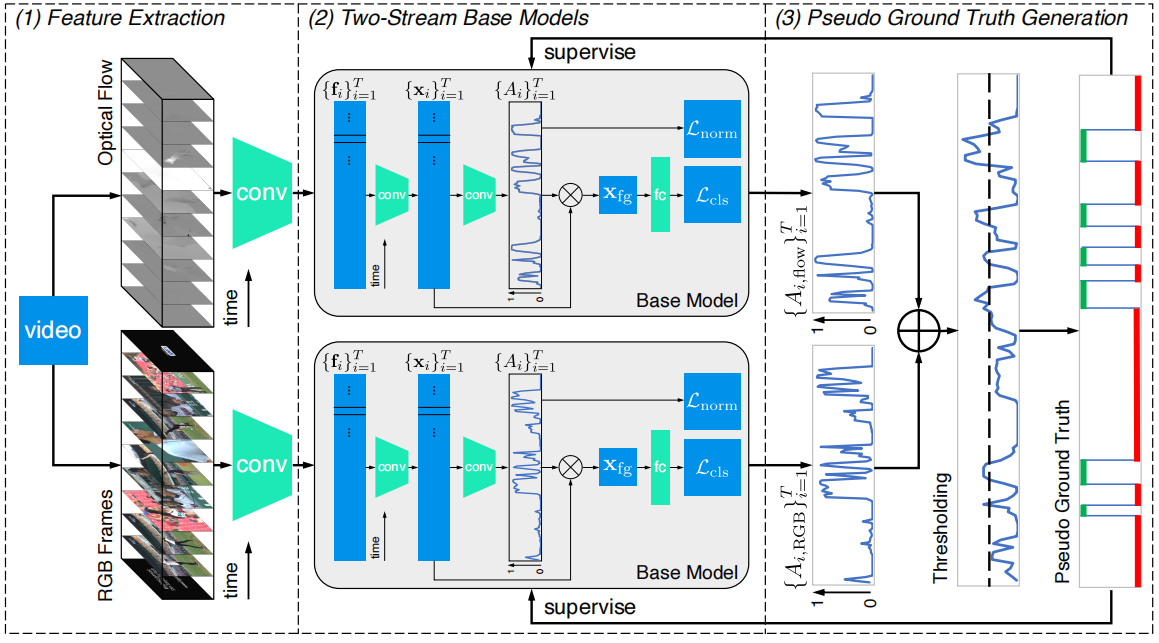
(1)给定一个分为T个非重叠片段的视频,特征提取模块使用预训练好的网络提取RGB和光流特征{fRGB,i}Ti=1和{fflow,i}Ti=1
(2)双流base模型执行视频级动作分类,然后使用帧级伪ground-truth迭代地细化base模型。将两种模式的特征分别输入到两个独立的base模型中,两个base模型使用相同的体系结构,但不共享参数。由于这些特征最初不是针对W-TAL任务进行训练的,首先连接T个输入特征{fi}Ti=1,并使用一组时间卷积层生成一组新特征{xi}}Ti=1,再输入conv层+FC层得到注意力值Ai∈(0,1)以测量第i个片段包含一个动作的可能性,引入了一个注意力归一化项来强制注意力接近极值,然后,对特征序列进行注意力加权池化,生成单个前景特征xfg,并将其输入FC softmax层,得到视频级预测。分类损失函数Lcls被定义为标准的交叉熵损失。
(3)伪ground-truth生成,用一个帧级伪ground-truth对双流base模型进行迭代优化,具体来说,将整个训练过程划分为几个迭代。在迭代0中,只有视频级别的标签用于训练。在迭代n+1时,在迭代n生成帧级伪ground-truth,并为当前迭代提供帧级监督。作者介绍了两种伪ground-truth生成方法:(1)soft伪ground-truth,直接使用融合注意力值作为伪标签,它包含了一个片段是前景动作的概率,但也增加了模型的不确定性。(2)hard伪ground-truth,在注意力序列上施加阈值以生成一个二进制序列,它消除了不确定性,提供了更强的监督,但引入了超参数。
