
I3D论文总结
最近看了李沐讲论文系列朱毅老师讲的I3D论文精读(视频,笔记),这里记录一下。
1.针对的问题
1.之前的视频数据集都太小,导致大多数流行的动作识别基准都很小,且即使不同模型效果有好有坏也难以区分。
2.在I3D提出之前,视频一直没有明确的前端运行架构,之前捕获时序信息的方法主要有三种。1.向模型中添加一个循环层,例如LSTM,但这种方法在之前这些数据集上,表现并不是非常好。2.3D卷积神经网络,输入是视频段,卷积核是三维的,再二维信息的基础上还要额外处理时间维度,这导致参数量变得很大,另外也没能使用到ImageNet预训练的好处。3.双流网络,时间信息通过计算出来的光流表示。还有一种结合了3D卷积和双流的方法,这种方法同样使用双流,不过在最后输出的时候不像3D卷积网络一样加权平均,而是使用了一个3D卷积。
2.主要贡献
这篇论文主要有两个贡献:1.一个inflated 3D network(I3D),把2D模型扩张到3D模型,这样就不用专门设计一个视频理解的网络了,可以使用2D里已经设计好的网络,比如VGG、ResNet直接把它扩张到3D就可以了,甚至利用一些巧妙的方式把预训练模型利用起来,这样不仅设计简单,而且可以省掉很多预训练的麻烦;2.提出了一个新的数据集——Kinetics数据集,刚开始提出的时候只有400类,后面又推出了kinetic 600/700,分别对应600类和700类,视频的数量也从最开始的30万涨到了50多万,最后60多万,类比均衡,难度适中,不算特别大。
3.方法
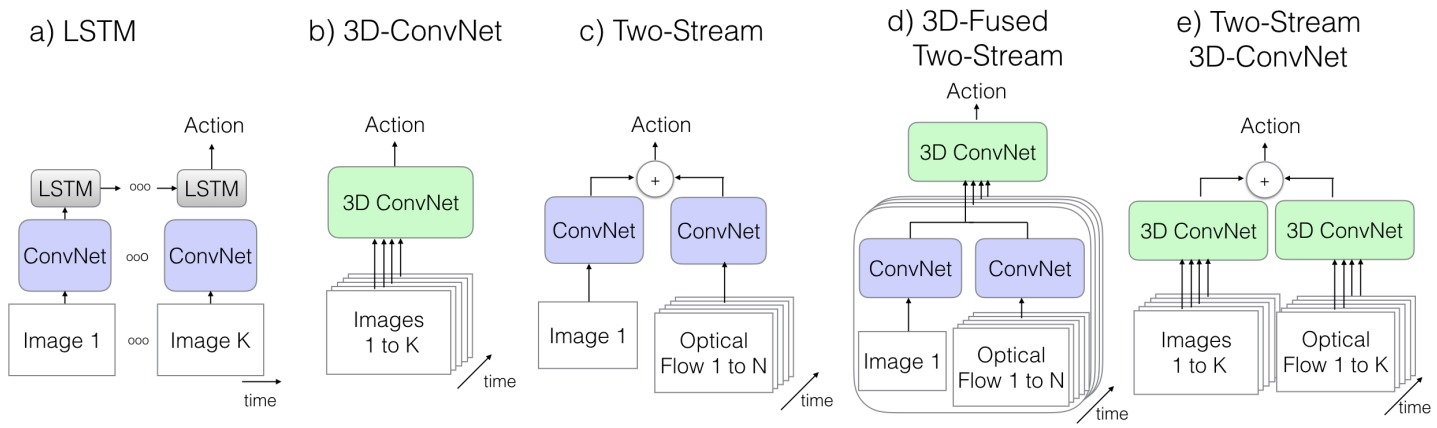
e为I3D模型,结构与3D卷积网络类似,不过结合了光流,最后进行加权平均,这里主要介绍一些细节部分。inflate和bootstrap操作是精华部分。
1.Inflate,其实就是把一个2D网络直接变成一个3D网络,对于一个2D网络,只要遇到一个2D的卷积kernel, 就把它变成一个3D的kernel,遇到一个2D的pooling层,就变成一个3D的pooling层,其他结构都不变,这样就不需要重新设计网络。
2.bootstrap,如果输入是一张图片x,2D网络是w,则输出是wx,将图片反复复制粘贴,变成一个视频则为nx,将所有的2Dfilter在时间维度也复制粘贴n次,变成nw,则输出变成nwx,所以需要做一些rescaling,也就是在所有的filter上除以n,则最终输出变成wx,也就与2D网络对应起来了(感兴趣的同学可以看一下老师实现的代码,具体实现在539行init_weights函数,先将2D网络的参数下载下来,然后通过collect_params这个函数就可以得到所有2D网络的参数,都存在weights2d这个变量里,然后将3D网络的所有参数也保存到weights3d变量,566行是一个assert操作,因为2D网络和3D网络的结构一样,也就是层数应该一样,从581行开始的for循环就是将2D网络的参数转移给3D网络,585行的就是bootstrap操作)
3.如何控制池化层,从而使得感受野处于一个合适的范围,在inflate inception-V1时,conv层直接从7×7变为7×7×7,在maxpooling操作时并不是简单的将3×3变为3×3×3,因为作者发现时间维度最好不要做下采样,因为本来时间维度可能就不是长,所以这里是把3×3变为1×3×3,stride从2×2变为1×2×2,不过只是对于前面两个maxpooling,后面的依旧做了下采样。inception module直接inflate。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现