
SF-Net:Single-Frame Supervision for Temporal Action Localization流程概述
1.针对的问题
在动作定位领域,全监督标注困难,成本较高,而弱监督性能较差,特别是难度比较大的数据集上几乎失效,在之前已经有人在动作识别领域使用了单帧监督,作者进行了拓展,利用单帧监督进行动作定位。
2.主要贡献
(1) 第一次使用单帧监督来解决动作时间边界定位问题。与完全监督标注相比,单帧标注显著节省了标注时间。
(2) 提出了两种新的方法来挖掘可能的背景帧和动作帧。这些可能的背景和动作时间戳被进一步用作训练的伪ground-truth。
(3) 在三个基准上进行了大量实验,在分段定位和单帧定位任务上的性能都得到了很大提高。
3.方法
框架流程如下:
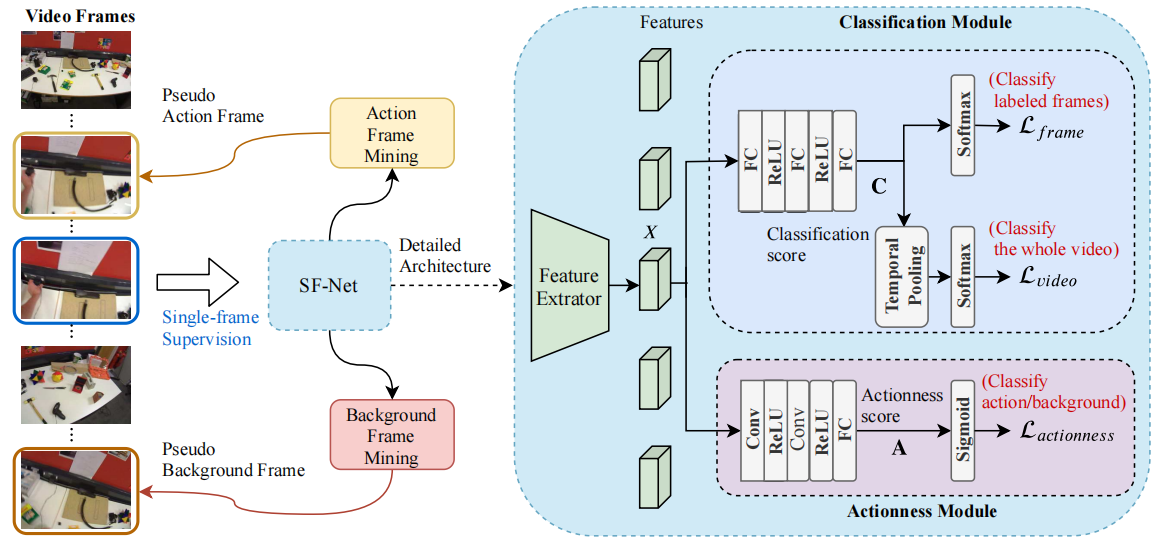
对于N个视频的训练batch,将所有帧的特征提取并存储在特征张量X∈RN×T×D中,其中D为特征维数,T为帧数。由于不同的视频时间长度不同,当视频的帧数小于T时,简单地填充零。
得到的X一方面进入分类模块,该模块输出输入视频中所有帧的每个动作类的分数,同时聚合C来计算视频级分类损失
X另一方面进入动作性模块,该模块为每个帧生成一个标量,以表示该帧包含在动作片段中的概率,这个模块感觉是一个辅助模块,它使模型关注与目标动作相关的帧。
由于每个动作实例只有一个标签,正例的总数非常少,可能很难从中学习。所以在获得分数之后,利用该分数挖掘动作帧和背景帧,从而在训练过程中引入更多的帧。具体来说:
(a) 动作帧挖掘:将每个有标签的动作帧视为每个动作实例的锚帧。首先设置扩展半径r,以限制到锚帧t的最大扩展距离。然后从t-1帧扩展到过去,从t+1帧扩展到未来。假设锚框架的动作类由yi表示。如果当前扩展帧与锚定帧具有相同的预测标签,并且yi类的分类分数高于锚定帧乘以预定义值ξ的分数,那么用标签yi标注该帧,并将其放入训练池。否则,我们将停止当前锚帧的扩展过程。
(b) 背景帧挖掘:背景帧在定位方法[19,26]中也很重要并被广泛使用,以提高模型性能。由于在单帧监督下没有背景标签,作者提出的模型能够从N个视频中的所有未标记帧中定位背景帧。一开始,没有监督背景帧的位置。但是,显式引入一个背景类可以避免将一个帧被强制分类为一个动作类。作者提出的背景帧挖掘算法可以提供训练此类背景类所需的监督,从而提高分类器的可分辨性。假设试图挖掘ηK个背景帧,首先从C中收集所有未标记帧的分类分数。η是背景帧与标记帧的比率。然后,这些分数沿背景类排序,以选择最高的ηK个分数pb∈RηK作为背景帧的得分向量。
