
遇到的问题
1.ImportError: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.22' not found
具体问题如下:
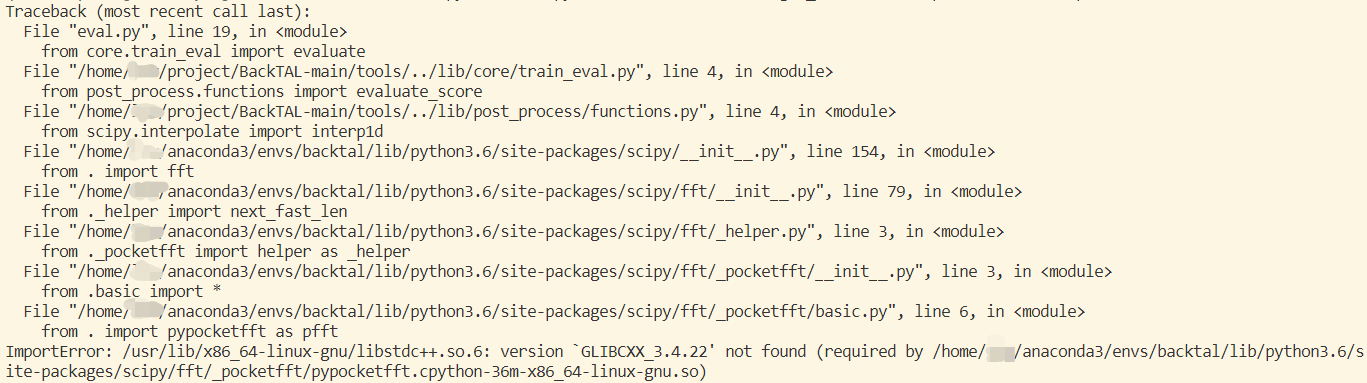
这个问题网上有解决的教程,见CSDN,不过由于我是在服务器上运行,除了我自己的文件外都没有操作权限,网上的教程基本上都要复制文件,所以无法解决,仔细看了下问题,缺的是GLIBCXX_3.4.22文件,这个文件是scipy需要的,所以我就将scipy修改了下版本,从1.5.0升到1.5.4,成功解决,我估计是两个版本找的GLIBCXX_3.4.22路径不同,我的anaconda3文件中是有GLIBCXX_3.4.22的,不过为何会有这种差别我也不太清楚。。。
2.ERROR: Cannot uninstall ‘certifi‘. It is a distutils installed project and thus we cannot accurately
pip install wandb -i https://pypi.tuna.tsinghua.edu.cn/simple/报错,修改为pip install wandb -i https://pypi.tuna.tsinghua.edu.cn/simple/ --ignore-installed安装成功。不过后来又报错f'{self.__class__.__name__} object does not support item assignment'),是代码中抛出的错误,先注释掉抛出错误的代码,成功运行。
3.VSCode运行python项目没有错误提示
网上方法大部分都是搜索“errorSquiggles”,选择 enable或者按下 ctrl+shift+p ,搜索“启用错误下划线”并点击即可。不过我发现根本没有这两个选项,后来发现是没有安装python这个插件,之前好像都是自动安装的,就没怎么注意。
4.VSCode解释器问题
之前被这个问题折磨了挺久,我是在服务器上跑,每次打开一个python项目之后就自动进到另一个同学的环境里,需要把他的deactivate掉再激活我的,而且有的时候下载包也莫名其妙用了他的cache,导致我已经下过了,但是还是提示没有,结果重新下载的时候又在我的cache里可以找到,就下不了,而且相关路径的配置文件好像也在别人的文件里,没有修改权限,后来发现在VSCode里按ctrl+shift+P,搜索Select Interpreter(这里需要安装python扩展,不然没有这个选项,另外VS Code在右下角可以直接进入选择环境界面),可以自己选择环境,如果找不到目标环境,可以点击enter Interpreter path直接进入对应环境文件夹,选择bin目录下的对应python,这样虽然多了一步选择的过程,但是不需要输入命令激活环境了。这里有的时候会碰见选择无效的问题,可以先选别的环境,有效之后再选目标环境。
5.wandb
wandb可以创建sweep自动搜索超参数,以确定各超参数的重要性及找到性能最好的一组超参数,配置过程也比较简单,但是如果代码中使用了argparse,可能会出现无法识别参数的错误,需要通过parser.add_argument()函数把这些参数都加上,这一点在其他需要通过命令设置参数时一致,另外建议在变量名中使用下划线而不是连字符,否则可能会报unrecognized arguments的错误。此外,可以在wandb agent xxxx之前,加上CUDA_VISIBLE_DEVICES=x来设置在哪张卡上运行sweep。对于一个项目,参数可能都已经设置好了,如果配置是一个多层的字典,在编写sweep脚本的时候就会比较麻烦,这种情况下,一个搜索学习率的简单做法如下:
1.看是否使用了argparse,如果能删则删,否则将要搜索的参数通过parser.add_argument()函数加上。
2.通过一个字典保存要搜索的参数
hyperparameter_defaults = edict( lr = cfg.lr )
3.在初始化wandb时将参数传入
wandb.init( config=hyperparameter_defaults )
4.将原来的参数替换掉或者赋值为wandb.config对应的参数
cfg.lr = wandb.config.lr
另外需要搜索的超参数需要由wandb.config进行控制。但是后来我发现,即使自己设置参数与搜索的某个实例完全一致,结果居然不同,虽然两种方式跑的命令不同,但是应该还是存在问题。
wandb在运行之后会在本地保存一个文件,位置在运行的脚本同级目录中的wandb文件夹下,可以通过wandb offline取消实时同步,在运行完毕之后通过该文件上传数据到网页。
6.pytorch单机多卡训练
虽然DataParallel方式相比DistributedDataParallel方式有效率低,速度慢等缺点,但是如果没有这方面的需要的话,DataParallel方式也够用了,而且DataParallel方式配置简单,并且DistributedDataParallel可能还需要调整学习率,同步BN等(我还出现了性能下降很多的问题)。
DataParallel方式(参考知乎):
原理:采用单进程,多线程,在前向过程中:1. 分发mini-batch到每个GPU上,2. 将模型复制到每一个GPU上,3. 模型对mini-batch进行forward计算结果,4. 将每个GPU上的计算结果汇总到第一个GPU上。反向传播过程:1. 在第一个GPU上根据计算的loss计算梯度。2. 将第一个GPU上计算的梯度值分发到每个GPU上。3. 每个GPU上进行梯度更新。4. 将每个GPU上更新的梯度值汇总到第一个GPU上。其中foward过程都会把第一个GPU上的模型重新分发到每个GPU上。
操作:通过.cuda(),将模型,参数都放到GPU上,然后通过model = torch.nn.DataParallel(model)初始化一下,最后命令行执行CUDA_VISIBLE_DEVICES=0,1,2,3 python xxx.py就行了。
另外batch size需要是卡数的整数倍,否则会报TypeError: Caught TypeError in replica 1 on device 1和TypeError: forward() missing 1 required positional argument: 'x'的错误。有的代码在测试的时候batch size大小是1,这个时候直接跑就会报错,可以在使用DataParallel包装模型之后加上model_module = model.module,在测试的时候传入model_module。
DistributedDataParallel方式(参考博客):
原理:采用多进程,多线程。1.(缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。2.(Ring-Reduce加速)在模型训练时,各个进程通过一种叫Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度;3.(实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
操作:
1.导入包
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
2.添加local_rank可选参数。parser.add_argument("--local_rank", default=-1, type=int),这里的local_rank虽然可以自动识别当前进程的序号,但是需要注意的是,当前进程序号是按照可见的GPU排序的,也就是说当CUDA_VISIBLE_DEVICES=2时,local_rank为0就表示在使用卡2。(参考CSDN)
3.通过torch.cuda.set_device(args.local_rank),dist.init_process_group(backend='nccl', init_method='env://')初始化。
4.修改数据集读取,就是把本来直接传给DataLoader函数的数据读取类dataset单独拿出来,先传入DistributedSampler中,得到sampler,再将dataset传入DataLoader函数,并加上sampler=sampler。这里要将shuffle设置为false。
5.通过以下几条语句设置模型
local_rank = args.local_rank
model = model.to(local_rank)
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model ).to(local_rank)
model = DDP(model , device_ids=[local_rank],output_device=local_rank, find_unused_parameters=True)
6.通过trainloader.sampler.set_epoch(epoch)设置sampler的epoch
7.终端运行这条语句: CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node 2 main.py
需要注意的是几个节点都会运行程序,所以一些打印或者删除的操作需要考虑进程间互斥的问题,另外所有的forward的函数的所有输出都要用于计算损失函数RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one的错误(有时加上find_unused_parameters能直接解决这个错误)。
7.python导入同一目录下的文件夹或者同一目录下的py文件报错(参考CSDN)
1.在要导入包所在文件夹创建__init__.py文件
2.当前文件中加入以下代码
import sys
sys.path.append('根目录路径')
from TestDIR import file_utils
8.anaconda迁移
有时候我们需要把anaconda从一台机器迁移到另一台机器,或者迁移其中的某个虚拟环境,如果直接将anaconda3文件或者虚拟环境的文件夹打包再上传会报错,因为anaconda涉及到许多路径问题,可参考简书,而虚拟环境这样迁移也会需要更改bin目录下pip和pip3的路径。
但是这样还存在一个问题,在打开这些文件夹的时候,如果用记事本或者别的打开,可能在修改路径后会在路径最后加上一个^M,可能是改变了文本格式的问题,不过我照着网上的方法修改格式或者删除^M都没有作用(可能是我操作不对),所以个人认为anaconda直接重装,环境迁移可以参考CSDN的第二种方法,通过conda-pack进行打包迁移,或者参考CSDN,不过这种方法我还没有尝试过。另外如果只是装某个包,别的虚拟环境有的话可以直接复制过来,一般在lib/pythonx.x/site-packages文件下,把那个包和info全部复制就行。
9.vscode——matplotlib绘图不显示问题
1.shell 中检查echo $DISPLAY,如果显示为空,说明当前窗口没有获得 $DISPLAY 环境变量 导致无法画图。解决方案:在shell中运行以下脚本给变量赋值即可。export DISPLAY=:0.0(解决了我的问题,参考CSDN)
2.在设置中搜索plots,勾选Theme matplotlib plots(参考知乎)
10.RuntimeError: Expected object of device type cuda but got device type cpu for argument #2 'mat2' in call to _th_mm
这个问题比较常见,就是模型或者变量的设备问题,但是需要注意的是,虽然在开始都会通过model.cuda()等代码将模型放到GPU上,但是不在net中的变量或者模型,如utils文件中的线性层,是不会初始化在GPU上的,所以在初始化时还需要再设置一次。
