
Action Shuffling for Weakly Supervised Temporal Localization概述
1.针对的问题
目前的弱监督动作定位方法表现出两个显著的趋势:
(1) 动作背景建模。通过分别学习视频级别的动作和视频的背景表示,可以提高动作定位性能,然而,视频级建模只能捕获粗粒度的描述。对动作的内在特征进行深入分析的研究较少。
(2) 探索外部资源。为了弥补弱监督带来的有限信息,借助外部资源已成为另一种趋势。通常,公开可用的视频或生成的带有视频级别或帧级别标签的伪视频被用作补充训练数据。不过这种方法也存在两个缺点:(1)原始数据集和辅助数据集之间的源-目标自适应对于稳健的知识转移至关重要,但很难实现。(2)新训练视频的特征提取给计算消耗带来了额外负担。
2.主要贡献
•设计了动作内/动作间重组机制,以充分利用动作的顺序敏感和位置不敏感特征,并提高模型的表示能力。该模型以自增强的方式工作,不需要外部资源。
•设计了全局-局部对抗训练方案,以增强模型在视频级预测和片段级动作背景识别方面对无关噪声的鲁棒性。
•设计了网络架构,将不同的模块集成到一个统一的框架中,该框架以端到端的方式进行优化。在具有挑战性的未经剪辑的视频数据集上进行的大量实验表明,ActShufNet在技术水平上取得了令人鼓舞的结果。
3.方法
作者发现动作具有两个关键特征:
•一方面,动作对顺序敏感。视频的动态运动特征通过有序帧内的时间相关性来反映。改变动作的内部顺序可能会显著改变其语义。例如发射子弹在相反的时序下就变成了捕捉子弹,这是一种完全不同的行为。
•另一方面,动作对位置不敏感。与对内部顺序的依赖相比,一个行为相对独立于它发生的时间。在不同的时间点采取同一类别的行动不太可能影响底层语义,只要保持原有的内部顺序。
由此,作者提出了一种新的具有动作内/动作间重组的弱监督动作定位网络结构,称为ActShufNet。在传统的基于注意力的动作识别和定位范式的基础上,作者构建了一个自增强的学习模型,以实现在不依赖任何外部资源的情况下提高表示能力。模型从基于class-agnostic注意力的初步分割动作开始,经过两条分支,即动作内和动作间的重组。动作内重组随机改变动作的内部顺序,旨在通过自我监督任务恢复其原始顺序。通过这种方式,优化的表示被强制捕获动作的潜在内在相关性,这有助于随后的语义推断。动作间动作重组随机选取同一类别的动作,这些动作共同创建新的未剪辑视频,这些视频自然附加了共享视频级标签。这样,训练数据集可以任意扩展,同时在每个创建的视频中包含更多种类。为了进一步增强模型对动作和背景的区分能力,提出了全局局部对抗训练方案,以获得抗干扰的鲁棒学习性能。
模型流程图如下:
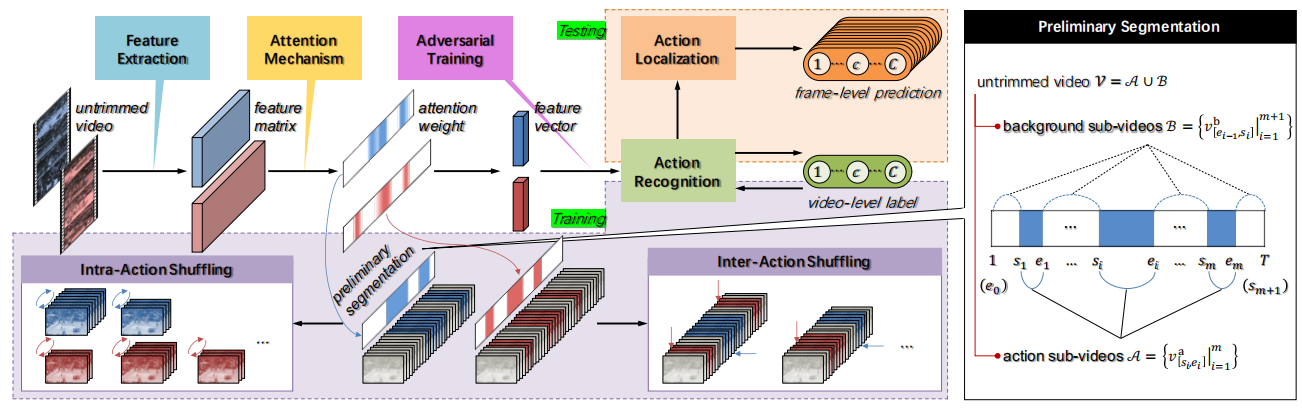
对于一个有T帧/片段的视频V,通过预训练的特征提取模型提取RGB或光流视频特征,由于可变长度T的未裁剪视频会带来可变特征矩阵,处理非常不方便。因此,利用注意力机制来集成帧级描述,并获得固定大小的紧凑表示。
每个视频会包含多个动作子视频,对每个动作子视频均匀采样N个固定大小的片段,采样的N个片段被随机打乱并组织成一个元组来形成输入数据,以它们的原始顺序作为目标。将顺序预测作为一个分类任务,它输出输入clip特征在不同顺序上的概率估计。
从同一类的视频中随机选择几个动作片段,并将它们连接到一个新视频中。新视频具有与原视频相同的标签,从而可以扩充训练集。
