
补充知识总结
1.SE不适定问题(ill-posed problem):
是数学领域的术语。在计算机视觉领域,Jaeyoung在CVPR的论文中这样描述CV中的不适定问题:这种不适定问题就是:一个输入图像会对应多个合理输出图像,而这个问题可以看作是从多个输出中选出最合适的那一个。
2.few-shot learning:
小样本学习,是元学习(Meta Learning)的一个实例。Meta Learning,又称为learning to learn,该算法旨在让模型学会“学习”,能够处理类型相似的任务,而不是只会单一的分类任务。
3.LXMERT:
从Transformers学习跨模态编码器表示(Learning Cross-Modality Encoder Representations from Transformers),用于学习视觉概念和语言语义之间的对齐和关系。
4.MIL:
多示例学习(multiple-instance learning)是1997年被提出的。其与监督学习、半监督学习和非监督学习有所不同,它是以多示例包(bag)为训练单元的学习问题。
在多示例学习中,训练集由一组具有分类标签的多示例包(bag)组成 ,每个多包(bag)含有若干个没有分类标签的示例(instance)。如果多示例包(bag)至少含有一个正示例(instance),则该包被标记为正类多示例包(正包)。如果多示例包的所有示例都是负示例,则该包被标记为负类多示例包(负包)。多示例学习的目的是,通过对具有分类标签的多示例包的学习,建立多示例分类器,并将该分类器应用于未知多示例包的预测。
5.logits(参考):
f(wx+b)之后的输出,没有归一化的输出值,作为logits。将logits进行softmax归一化,得到最后的结果。也可以这么理解:logits与 softmax都属于在输出层的内容,logits = tf.matmul(X, W) + bias 再对logits做归一化处理,就用到了softmax:Y_pred = tf.nn.softmax(logits,name='Y_pred'),可以理解logits ——【batchsize,class_num】是未进入softmax的概率,一般是全连接层的输出,softmax的输入。
6.时序池化:
对于视觉应用来说,池化的更正式名称为空间池化。时间序列应用通常将池化称为时序池化。按照不太正式的说法,池化通常称为下采样或降采样。
7.AutoLoc(参考知乎):
ECCV 2018上的一篇论文,提出一种新奇的视频时序行为检测方法:AutoLoc,它能直接预测每个行为的中心位置和持续时间从而预测出行为边界
8.稀疏化:
L1正则化产生稀疏的权值, L2正则化产生平滑的权值(参考CSDN)
9.slowfast
Facebook的AI研究团队新发表的一篇论文,提出了一种新颖的方法来分析视频片段的内容,可以在两个应用最广的视频理解基准测试中获得了当前最好的结果:Kinetics-400和AVA。该方法的核心是对同一个视频片段应用两个平行的卷积神经网络(CNN)—— 一个慢(Slow)通道,一个快(Fast)通道。详见CSDN。
10.I3D
Inflated 3D ConvNet,膨胀卷积网络,根据之前各个模型的优缺点,设计的一个基于3D卷积的双流(RGB图信息+光流)模型(Two-stream Inflated 3D ConvNets)(见CSDN,知乎)

11.Siamese network
这个是一个曾经用于签字认证识别的网络,也就是我们平时说笔迹识别。Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,左右两个神经网络的权重一模一样,在代码实现的时候,甚至可以是同一个网络,不用实现另外一个,因为权值都一样。对于siamese network,两边可以是lstm或者cnn,都可以。主要用途是衡量两个输入的相似程度。(见CSDN,知乎)
12.bag,instance
在时序行为检测中,bag指的就是一个clip视频,instance指的就是tubelet。
13.自上而下和自下而上的注意力
参考1:自下而上的机制(基于 Faster R-CNN)提出了图像区域,每个区域都具有关联的特征向量,而自上而下的机制决定了特征权重,个人理解自下而上注意力就是利用目标检测技术(Faster R-CNN)在物体层面从面到点attention, 而自上而下注意力就是从点到面的角度进行attention
参考2:
top-down这种自上而下的注意力是由系统本身主动驱动的,这种驱动力可能来自系统自发,也有可能是来自其他任务刺激下产生的高阶信号;而bottom-up这种自下而上的注意力是由外界驱动,驱动力来自外界事物的刺激下产生的被动触发。
具体到注意力池化,作者通过矩阵的低秩近似将二阶池化作分解:
score_{attention}(X) = (Xw_{ak})^T (Xw_b)
其中,第一项与类别相关,可以看作是top-down attention;第二项与类别无关,可以看作是bottom-up attention。这样一来,二阶池化就被分解为两种注意力的乘积(交集)
参考3:
1.the bottom-up mechanism(Faster R-CNN):提取图像区域,每个图像区域由池化的卷积特征向量表示
2.the top-down mechanism:决定图像上特征向量的注意力权值
14.hard negative(难例)(参考CSDN,博客)
15.CAS
每个类别的片段激活分数,即类激活序列(CAS)
16.注意力掩码
注意力机制大多数采用掩码实现。掩码往往指使用一层全新的注意力机制权重,将特征数据中每个部分的关键程度表示出来,并加以学习训练。从通俗的意义上解释,注意力机制的本质是利用相关特征图进行学习的权重,再将学习的权重施加在原特征图上进行加权求和,进而得到增强的特征。(参考CSDN)
17.判别式模型与生成式模型(参考CSDN,机器之心,CSDN)
判别式模型是完全根据数据得出结果,是直接对条件概率 P (Y∣X;θ)建模。是在给定观察结果的情况下计算潜在变量或潜在原因的概率的模型。判别式方法关心的是给定输入X,应该预测什么样的输出Y。代表判别一面的模型往往是前馈的、简单的和快速的。例如,深度前馈卷积神经网络就是判别处理的典范。这些模型通常以有监督的方式进行训练:它们学习将图像映射到标签,例如学习对猫和狗的图像进行分类。
生成式模型会有人为设定的条件建立模型,再通过利用假设建立的模型得出结果。是对X和Y的联合概率分布P(X,Y)建模,然后通过贝叶斯公式求得 P(y∣x),取 P(yi∣x)最大的yi。是计算潜在变量和观察结果的联合概率。生成方法关心的是给定输入x产生输出y的生成关系。相比之下,生成模型速度很慢,但它们也更灵活、严谨,且更具表现力。它们通常依赖于无监督的训练方法,目的是获得对世界统计数据和结构的基本了解,然后将其用于预测。例如,生成模型可能会使用爪子的视觉景象来预测长胡须也是存在的,并最终得出图像中有猫的结论。
18.快速梯度符号法(FGSM)详解(参考知乎)
FGSM用于对抗性攻击,将白盒法(知道模型参数及输入输出)和错误分类(在无需考虑预测分类的情况下诱导模型做出错误的预测)相结合,诱导神经网络模型做出错误的预测。它包括以下三个步骤:
1.计算出正向传播后的损失;
2.计算出图像像素的梯度;
3.沿着使损失最大化的梯度方向微移图像的像素。
19.知识蒸馏(Knowledge Distillation)(参考知乎,博客园)
知识蒸馏是 Hilton 于 2014 年在一篇论文里提出的概念。该论文提出一个方法主要思想是小模型(student)不仅能从给定的、已标签好的数据集中学习知识(训练模型),还能从一个大的深度网络(teacher)中提取知识进行学习。在训练过程中,损失函数(Loss function)由两部分损失(loss)加权组成,一部分是 soft loss,另一部分是 hard loss。Soft loss 是由学生网络预测的 soft predictions 与教师网络预测的 soft labels/targets 计算交叉熵(cross entropy),Hard loss 是由学生网络预测的 hard predictions 与数据真实标签(ground truth)计算交叉熵。
20.熵(信息熵)
低概率事件带来高的信息量,当概率小的时候,熵的值就会越大,所以说当不确定性越大的时候,熵越大。
22. 模型,Temporal Ensembling和MeanTeacher(参考知乎,百度文库(推荐)):
模型,Temporal Ensembling和MeanTeacher(参考知乎,百度文库(推荐)):
三者都是利用一致性正则(consistency regularization)来进行半监督学习(semi-supervised learning) 。一致性正则要求一个模型对相似的输入有相似的输出,即给输入数据注入噪声,模型的输出应该不变,模型是鲁棒的。
![]() 模型:可以说是最简单的一致性正则半监督学习方法了,基本思想是让模型对于未标记数据做两次预测,将两次预测的结果
模型:可以说是最简单的一致性正则半监督学习方法了,基本思想是让模型对于未标记数据做两次预测,将两次预测的结果 和
之间的均方误差作为无监督的loss。具体来说,训练过程的每一个epoch中,同一个无标签样本前向传播(forward)两次,通过data augmentation和 dropout注入扰动(或者说随机性、噪声),同一样本的两次forward 会得到不同的predictions,希望这两个predictions 尽可能一致,即模型对扰动鲁棒。

Temporal Ensembling:用多次结果的集成作为重构目标:
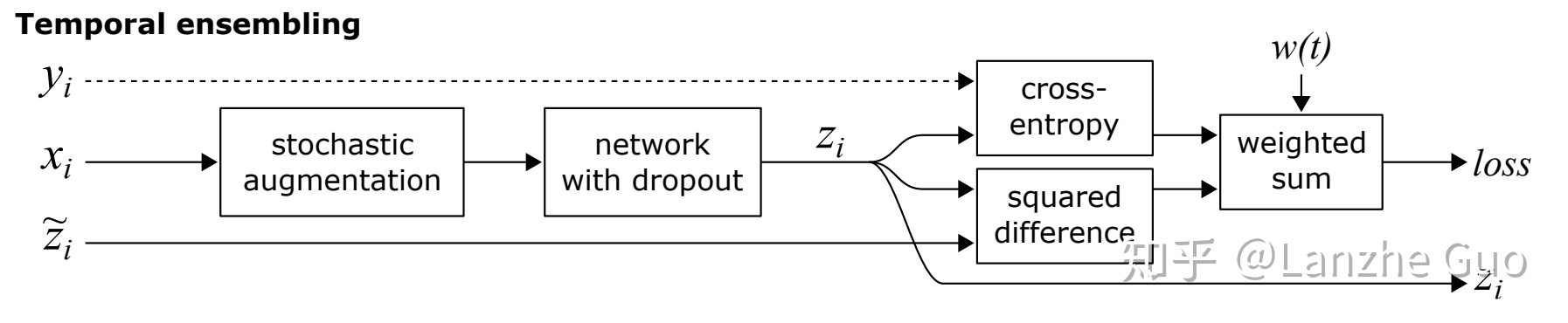
这里采用的 和前面方法不同,是训练过程中多轮
的预测值集成的结果,比如第t轮,就是1到t轮的预测值的一个集成,而不仅仅是第t轮的预测结果。
23.归一化(Normalization)和标准化(Standarlization)(参考知乎)
归一化和标准化的本质都是缩放和平移,常见的归一化方法:xi-min(xi)/(max(xi)-min(xi)),常见的标准化方法:xi-mean(xi)/sd(xi),从输出范围角度来看, 归一化的输出结果必须在 0-1 间。而标准化的输出范围不受限制,通常情况下比归一化更广。一般情况下,如果对输出结果范围有要求,用归一化。如果数据较为稳定,不存在极端的最大最小值,用归一化。如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
24.class-agnostic和class-specific区别(参考知乎)
class-specific方式,很多地方也称作class-aware的检测,是早期Faster RCNN等众多算法采用的方式。它利用每一个RoI特征回归出所有类别的bbox坐标,最后根据classification 结果索引到对应类别的box输出。
class-agnostic(类别无关)方式只回归2类bounding box,即前景和背景,结合每个box在classification 网络中对应着所有类别的得分,以及检测阈值条件,就可以得到图片中所有类别的检测结果。当然,这种方式最终不同类别的检测结果,可能包含同一个前景框,但实际对精度的影响不算很大,最重要的是大幅减少了bbox回归参数量。
25.稀疏权值与平滑权值
L1正则化产生稀疏的权值,所以稀疏损失中常用L1正则化,L2正则化产生平滑的权值(参考CSDN),激活分数通常需要与注意力权重一致
26.Uncertainty(参考知乎,CSDN)
不确定性可以分为两种,即偶然不确定性和认知不确定性。
偶然不确定性用来描述观测中固有的噪声,是样本本身比较难预测
认知不确定性则是用来描述模型中的不确定性,是模型本身造成预测不确定,所以一个常用的方法是使用dropout,即采样T次,每次输出前dropout模型,然后得到T次的预测概率后求交叉熵为认知不确定性,回归任务则是求方差即可。
27.凸组合(参考百度百科)
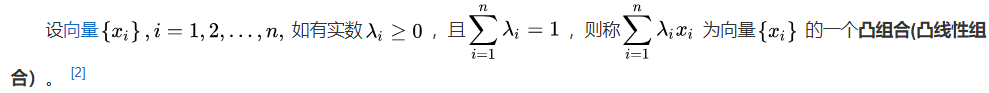
任意两个点的凸组合都在它们之间的线段上
28.狄拉克δ函数(参考百度百科)
如果考察质点的密度或点电荷的电荷密度,将得到无穷大,然而将其密度(电荷密度)在空间中积分却又能得到有限的质量与电荷.为了描述这样的密度(电荷密度)分布,引入了狄拉克 函数(Dirac delta function)。在概念上,它是这么一个“函数”:在除了零以外的点函数值都等于零,而其在整个定义域上的积分等于1。它不是数学中一个严格意义上的函数,而是在泛函分析中被称为广义函数,满足以上条件的函数是不存在的。一些函数可以认为是狄拉克δ函数的近似,但这些函数都是通过极限构造的。
29.Beta分布(参考CSDN)
描述概率的概率分布,可以将Beta分布记为Beta(a,b),其中a是成功的次数,b是失败的次数。在已知a,b的情况下关于成功概率p的分布为Beta分布。
30.focal loss(参考知乎,CSDN)
标准交叉熵损失函数在处理类不均衡问题时非常糟糕,会因为某类的冗余,而主导损失函数,使模型失去效果。如对于二分类问题,损失函数可以写为:
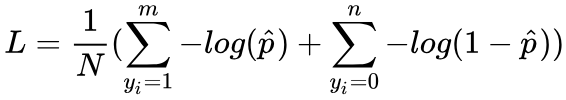
其中m为正样本个数,n为负样本个数,N为样本总数,m+n=N。
当样本分布失衡时,在损失函数L的分布也会发生倾斜,如m<<n时,负样本就会在损失函数占据主导地位。由于损失函数的倾斜,模型训练过程中会倾向于样本多的类别,造成模型对少样本类别的性能较差。
解决该问题的常见做法是添加权重因子,在αϵ[0,1]的前提下,对class 1添加α,对class-1添加1− α,得到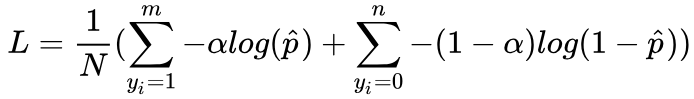
即平衡交叉熵。但是当不平衡程度很高时,这种做法无法完全解决问题。
作者通过实验发现,即使置信度很高的样本在标准交叉熵里也会存在损失。而且在实际中,置信度很高的负样本往往占总样本的绝大部分,如果将这部分损失去除或者减弱,那么损失函数的效率会更高。于是,作者想到减少置信度很高的样本损失在总损失中的比重,即在标准交叉熵前添加了权重因子(1−Pt)γ形成focal loss:
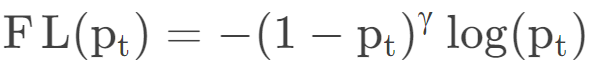
当γ等于0是为标准交叉熵损失,当γ大于0时,样本的置信度越高,pt越大,1-pt越小,指数之后更小,从而减轻置信度大的样本的影响。
31.互信息(参考CSDN)
它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性,表示为I(X,Y),当I(X,Y)=0时,X,Y相互独立,当I(X,Y)=1时,X确定则Y确定。
32.酉矩阵(参考CSDN)
若n阶复矩阵A满足AHA=AAH=E,则称A为酉矩阵,记之为A∈UN×N。其中,AH是A的共轭转置,E为n阶单位矩阵。
33.奇异值(参考百度百科)
奇异值是矩阵里的概念,一般通过奇异值分解定理求得。设A为m*n阶矩阵,q=min(m,n),A*A的q个非负特征值的算术平方根叫作A的奇异值。svd函数是Matlab中对矩阵进行奇异值分解的内置函数,[U,S,V] = svd(A)对A进行奇异值分解,其中U和V代表两个相互正交矩阵,而S代表一对角矩阵,S中的元素即为A的奇异值。
34.编辑距离(参考百度百科)
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。有几种不同的定义,差异在可以对字符串进行的处理。处理可以包括交换,插入,删除等多种。例如 Damerau-Levenshtein 距离中AB→BA 的距离是 1(交换)而非 2(先删除再插入、或者两次替换)。
35.Dilated Convolution(参考CSDN,简书)
Dilated convolution(空洞卷积,膨胀卷积或扩张卷积):在标准卷积的Convolution map的基础上注入空洞。之所以提出了Dilated Convolution,是因为Deep CNN存在一些主要的问题:
- 上采样和池化层存在一些知名的问题(Hinton在演讲中提出)
- 内部数据结构丢失,空间层级化信息丢失
- 小物体无法重建
Dilated convolution作用是在不增加参数量的情况下,增大感受野,获得更多的特征。其与标准卷积之间的区别如下:
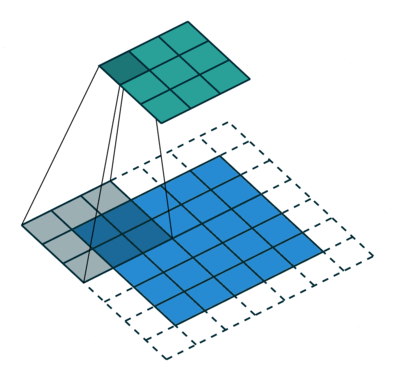
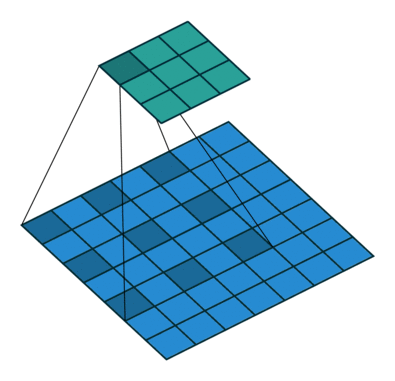
但是完全基于Dilated Convilution设计模型也会存在一些问题:1.kernel并不连续,也就是并不是所有的像素都用来计算了,会损失信息的连续性。(即栅格效应)2.Dilated Convolution对一些大物体有较好的分隔效果,而对于小物体来说可能是有弊无利了。可以采用HDC(混合膨胀卷积)来解决这个问题。
使用Dilated卷积的计算公式为:
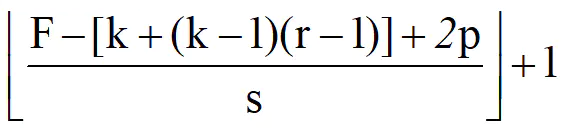
F为特征大小,k为卷积核大小,r为膨胀率,p为padding大小。pytorch实现直接设置nn.Conv1d的dilation参数即可,padding与dilation所使用的因子需要是相同的,否则可能会导致图像的尺寸会发生变化。如当k:3,r:3,p:3时可以保持输出尺寸。
36.SE模块(参考CSDN)
SENet是Squeeze-and-Excitation Networks的简称,主要是学习了channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果比较好。SE可以实现注意力机制最重要的两个地方一个是全连接层,另一个是相乘特征融合,通过global pooling+FC层,将输入图像拉伸成1×1×C,然后再与原图像相乘,将每个通道赋予权重。
37.标准自注意力为什么是token数的二次计算复杂度?(参考CSDN)
首先要知道矩阵乘法的复杂度计算方法,假设矩阵A是n*m,矩阵B是m*p,矩阵A和B相乘得到矩阵C是n*p,矩阵C中有n*p个元素,计算每个元素需要m次乘法运算 因此总共的时间复杂度为m*n*p。
首先是线性层,假设输入为x∈RN×d,d是嵌入大小,N=H/p×W/p是patch数量,p,H,W表示patch大小,图像高度和图像宽度。x先通过一个可选的嵌入层得到初步的embedding X,X通过三个权重为d×d矩阵WQ,WK,WV的线性层得到投影Q,K,V,维度都为(N×d),相当于x与WQ,WK,WV分别进行矩阵乘,也就是(N×d)×(d×d)=(N×d),计算复杂度为O(Nd2),
然后是计算层,self-attention计算公式![]() ,softmax里Q和KT做矩阵乘,也就是(N×d)×(d×N)=(N×N),计算复杂度为O(N2d),结果再乘V,也就是(N×N)×(N×d)=(N×d),计算复杂度为O(N2d),所以最终计算复杂度为O(N2d+Nd2),与N成二次关系。
,softmax里Q和KT做矩阵乘,也就是(N×d)×(d×N)=(N×N),计算复杂度为O(N2d),结果再乘V,也就是(N×N)×(N×d)=(N×d),计算复杂度为O(N2d),所以最终计算复杂度为O(N2d+Nd2),与N成二次关系。
38.depth-wise CNN(参考CSDN)
常规卷积操作每个卷积核对输入的每个通道都会进行卷积操作,如下图,N个Dk×Dk×M的卷积核对DF×DF×M的输入进行卷积得到Dg×Dg×N的输出。
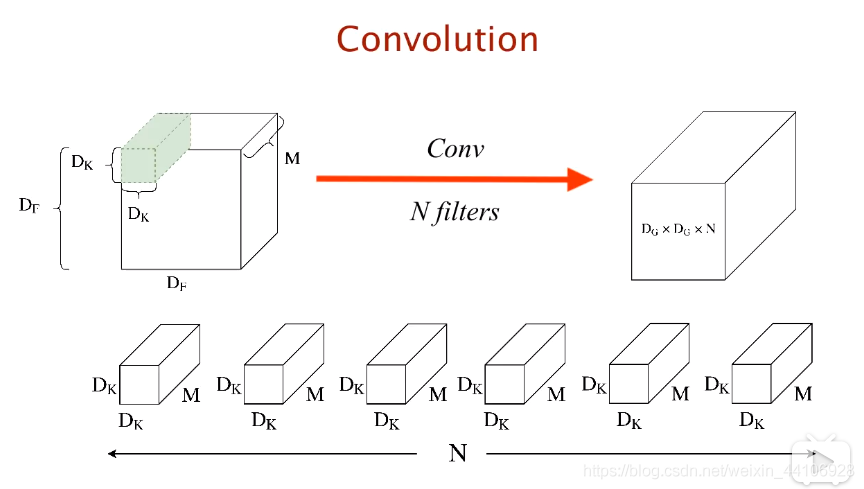
depth-wise卷积只让每个卷积核卷积一个通道,包括Separable Conv以及Point-wise Conv两个过程,以与上图类似的输入输出为例,Separable Conv过程中,通过M个Dk×Dk×1分别对M个通道进行卷积运算,得到Dg×Dg×M的输出,但是这样各个通道之间的信息并没有得到交换,从而在后续信息的流动会损失一些通道之间的信息,所以在Point-wise Conv过程中,通过N个1×1×M的卷积核对Separable Conv的Dg×Dg×M输入进行卷积得到Dg×Dg×N的输出。
depth-wise卷积虽然可以减少计算量和参数量,但是增加了IO的读取次数,所以速度不一定会更快。
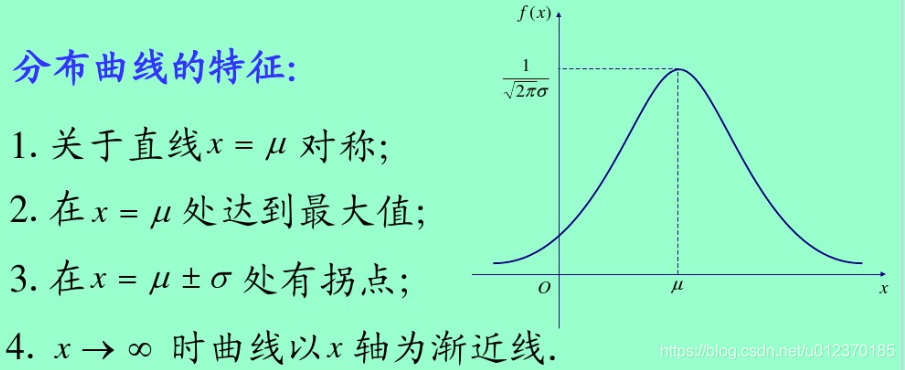
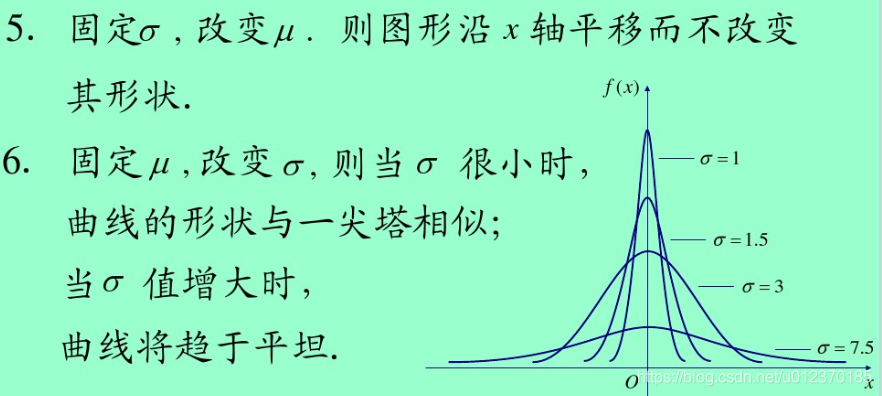
39.正态分布(参考CSDN)
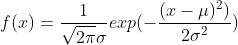
40.mAP(Mean Average Precision)
涉及概念:
TP(True Positives):预测为正,实际为正。TN(True Negatives):预测为负,实际为负。
FP(False Positives):预测为正,实际为负。FN(False Negatives):预测为负,实际为正。(后面的代表预测值,前面代表预测的对错,参考CSDN)
对于检测任务来说,若阈值为0.5,即mAP@0.5:
True Positive区域:与Ground truth区域的IoU>=0.5的
False Positive区域:IoU < 0.5的
False Negative区域:遗漏的Ground truth区域
True Negative区域:无法计算,因为没有标框的地方无法界定。参考CSDN
Precision(精度):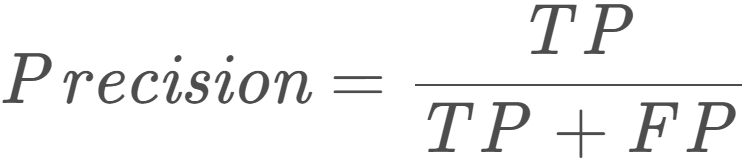 ,衡量预测有多准确。预测对的真实正例占所有预测正例的比例。又叫查准率。
,衡量预测有多准确。预测对的真实正例占所有预测正例的比例。又叫查准率。
Recall(召回率):![]() ,衡量发现所有正例的能力。预测对的真实正例占所有真实正例的比例。又叫查全率。
,衡量发现所有正例的能力。预测对的真实正例占所有真实正例的比例。又叫查全率。
mAP计算过程参考知乎
41.各种激活函数
1.relu
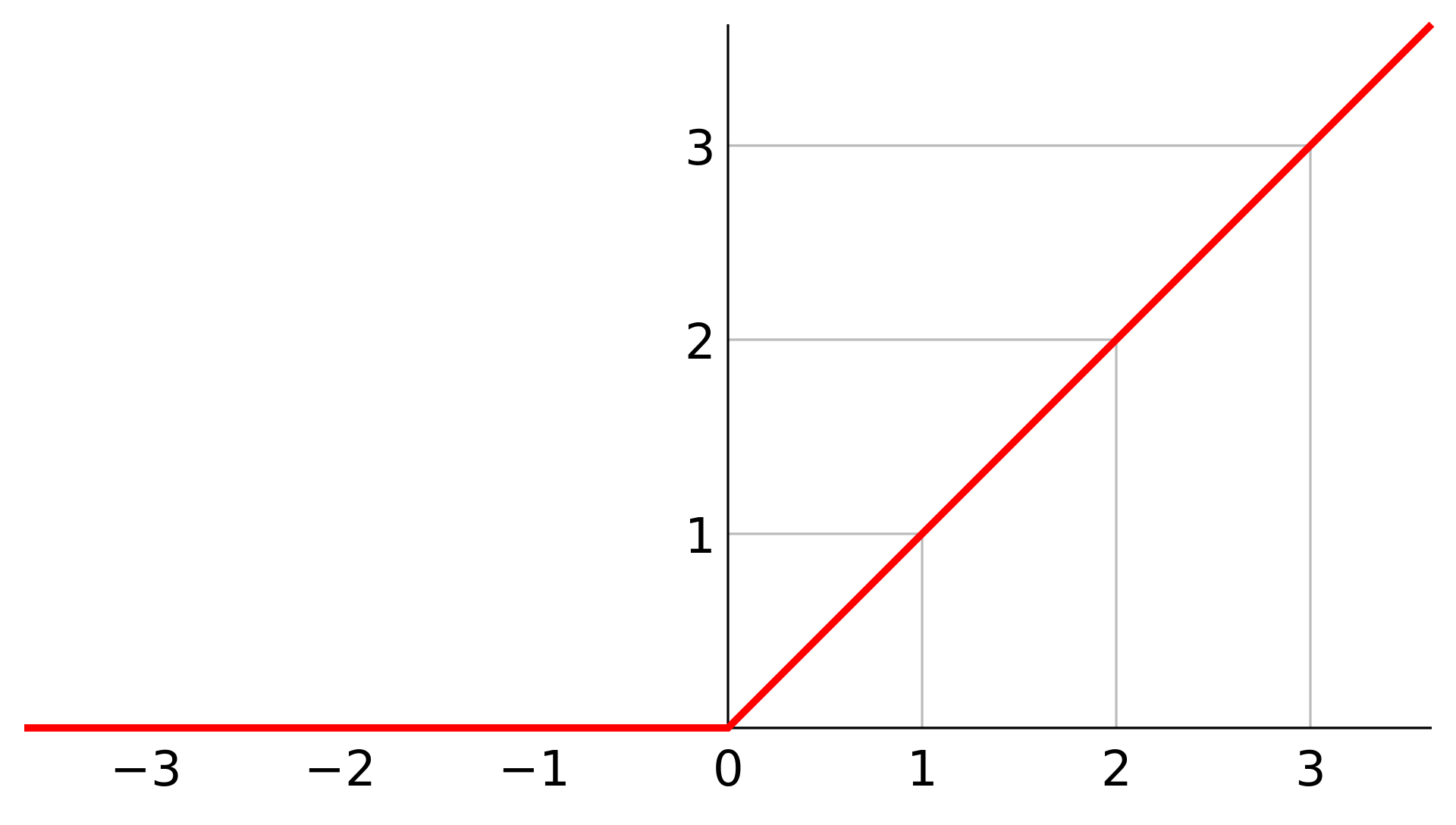
优势:
1、没有饱和区,不存在梯度消失问题,防止梯度弥散;
2、稀疏性;
3、没有复杂的指数运算,计算简单、效率提高;
4、实际收敛速度较快,比 Sigmoid/tanh 快很多;
5、比 Sigmoid 更符合生物学神经激活机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号