
A Hybrid Attention Mechanism for Weakly-Supervised Temporal Action Localization概述
1.针对的问题
大多数现有的WTAL方法依赖于多示例学习(MIL)范式,然而,现有的基于MIL的方法有两个局限性
(1)即只捕获动作中最具辨别力的帧,而忽略活动的全部范围。
(2)这些方法不能有效地对背景活动进行建模,这在定位前景活动方面起着重要作用。
2.主要贡献
(1)提出了一个新的框架,其中包含一个混合注意力机制,对整个行为进行建模;
(2) 提出了一种背景建模策略,通过使用辅助背景类引导注意力分数;
(3)在THUMOS14和ActivityNet数据集上实现了最先进的性能。
3.方法
1.为了捕捉完整的动作示例,删除了视频中更具辨别力的部分,并将注意力集中在不太具辨别力的部分。通过计算视频中所有片段的semi-soft attention分数和hard attentions分数来实现这一点。semi-soft attention分数通过将零值分配给soft attention分数大于阈值的片段来去除视频中更具辨别力的部分,而其他部分的分数保持与soft attention分数相同。由semi-soft attention引导的视频级别分类分数仅包含前景类。另一方面,hard attentions分数会去除视频中更具辨别力的部分,并将较低辨别度部分的注意力分数分配为1,这确保了由这种hard attentions引导的视频级类分数同时包含前景类和背景类。semi-soft和hard attentions都鼓励模型学习视频中动作的完整时序边界。
2.每个未修剪的视频都包含一些没有动作发生的背景部分。这些背景部分在分类分支中被建模为一个单独的类(即共有c个类,取第c+1类为背景类)。这种方法的一个主要问题是背景类不存在负样本,并且模型无法通过仅使用正样本进行优化来学习背景活动。为了克服这个问题,在注意力分支中提出了一种混合注意力机制,以进一步探索每个片段的“动作性”得分。加入了一个注意力模块,以根据背景建模策略区分前景和背景动作。目标是使得在没有活动示例(即背景活动)的帧中,每个片段的预测注意力得分较低,而在其他区域则较高。为了创建背景类的负样本,将每个类j关于第i个片段的片段级类logit(即CAS)si(j)(即分类分支的输出)与第i个片段的片段级注意力分数ai(soft attention分数,是一个前景注意力分数)相乘,并获得注意力引导的片段级类分数![]() ,其中⊗ 是元素级的乘积。sattn作为一组没有任何背景活动的片段,可以被认为是背景类的负样本。
,其中⊗ 是元素级的乘积。sattn作为一组没有任何背景活动的片段,可以被认为是背景类的负样本。
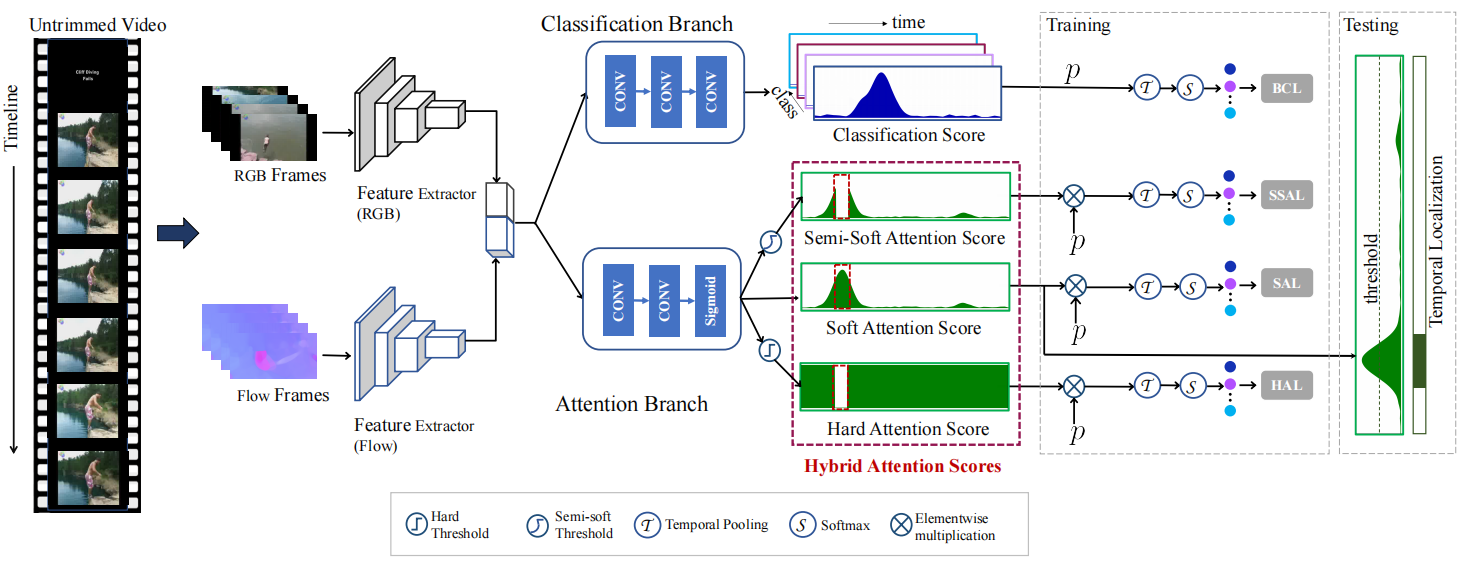
对于每个视频,首先将其划分为不重叠的片段,以提取片段级特征,提取RGB和光流的片段级特征。将两个特征连接起来,以获得完整片段特征,片段特征经过两个分支,上面的分类分支用于预测包括背景活动在内的所有动作示例的类激活分数,通过top-k策略合并片段级分数,然后通过softmax操作以获得视频级类分数,且得到一个基本损失函数LBCL,使用的是交叉熵损失,下面是一个注意力分支,用于预测视频片段的“动作性”分数,三种注意力分数的特点上面都已介绍,soft attention 分数通过与分类分支类似的操作得到视频级注意力引导类分数,并且三种注意力分别得到一个损失函数,使用的也是交叉熵损失。最终的损失函数还要包括稀疏损失和引导损失。稀疏度损失计算为soft attention分数的L1范数
最终结果会丢弃视频级类分数低于特定阈值的类,然后通过对所有片段的soft attention分数设置阈值来丢弃背景片段,通过选择剩余片段的一维连接来获得未知类的行动建议,用不同的阈值来获取行动建议,并移除具有非最大抑制的重叠部分。
4.问题
1.分类分数图的纵坐标是分数,横坐标是时间,这个时间具体是指什么?
答:是每一帧,即图上每个点对应(帧,得分)
2.hard attentions分数为何要确保包含背景类?
答:
3.sattn为什么是一组没有任何背景活动的片段?
答:![]() ,ai是soft attention分数,是一个前景注意力分数,所以两者相乘不包括背景类
,ai是soft attention分数,是一个前景注意力分数,所以两者相乘不包括背景类
答:通过设置阈值丢弃掉动作边界之外的片段,将剩下的片段连接起来作为行动建议
5.如何聚合片段级分数得到视频级分数?
答:使用top-k策略
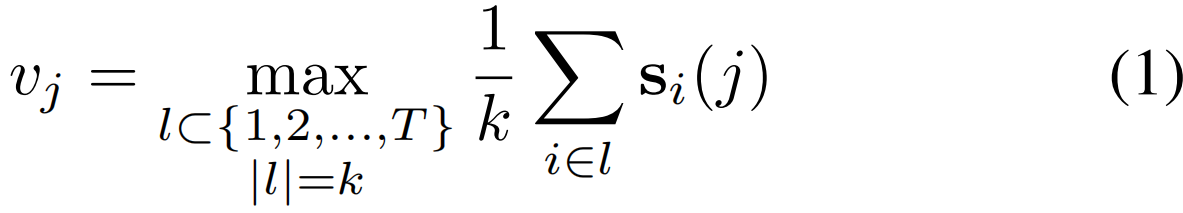
vj为每个类的视频级分数,具体来说就是选取k个片段,这些片段关于类的分数平均值最大。
6.引导损失为什么要这么设计?有什么作用?
答:某个片段成为背景的概率越高,说明该片段对于背景类的激活分数贡献也越大,则相应的背景注意力权重也应越大,所以通过引导损失使得背景类别概率和背景注意力权重相一致。
以上回答皆为个人看法,不一定正确,欢迎评论区讨论
5.More
光流通过TV-L1算法获得,通过I3D网络提取RGB和流特征
稀疏损失的思想来自于Weakly Supervised Action Localization by Sparse Temporal Pooling Network这篇论文,论文作者认为可以通过识别一组呈现重要动作成分的关键片段,将该动作从视频中识别出来,也就是本文中说的一个动作可以从视频片段的稀疏子集中识别出来,所以论文作者设计了一个神经网络来学习度量视频中每个片段的重要性,并自动选择代表性片段的稀疏子集来预测视频级别的类别标签,而L1正则化产生稀疏的权值, L2正则化产生平滑的权值(参考CSDN),所以本文中使用soft attention分数的L1范数作为稀疏损失,在没有稀疏性损失的情况下,大多数soft attention分数仍然接近1,这使得片段擦除策略无效。
辅助背景类的思想可以参考Background Suppression Network for Weakly-supervised Temporal Action Localization这篇论文(参考CSDN,博客园)
引导损失的思想可以参考Weakly-supervised Action Localization with Background Modeling这篇论文(参考CSDN),
