
对Uncertainty-Aware Weakly Supervised Action Detection from Untrimmed Videos的进一步总结
网上已经有大佬进行了总结,可以参考一下:CSDN
就目前来看,大多数弱监督方法的提出动力之一就是数据标注过于昂贵,模型基于MIL,主要创新点在于结合了网络做出的不确定性预测,标准的交叉熵损失会严重惩罚错误的预测,但是论文中的方法在预测结果错误但是不确定性较高时损失也不会太大,从而减小了训练误差,使得网络可以预测不确定性较低的bag级标签,也可以预测不确定性较高的bag级标签,以避免在任何tubelets中都不存在bag级标签的情况下,因噪声bag而受到严重惩罚。
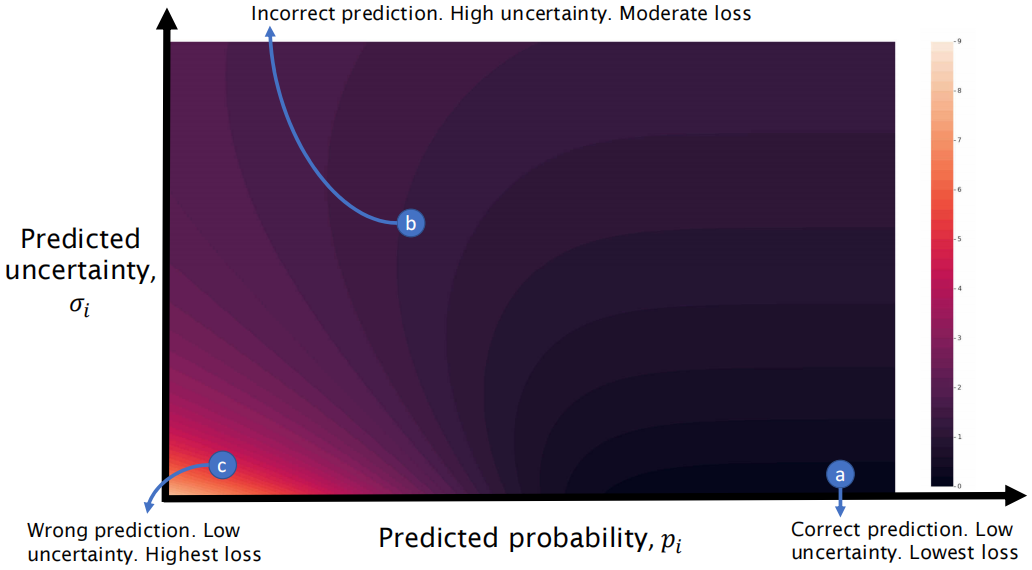
上图示例中的ground-truth二进制标签为1。因此,当网络预测高概率和低不确定性(点“a”)时,损失最小化。但是,做出具有高度不确定性的错误预测不会受到太大的惩罚(点“b”),并且适用于输入bag有噪声且任何tubelets中都不存在bag标签的情况。最后,预测为不确定度较低的错误标签受到的惩罚最大(c点)。
总体框架如下
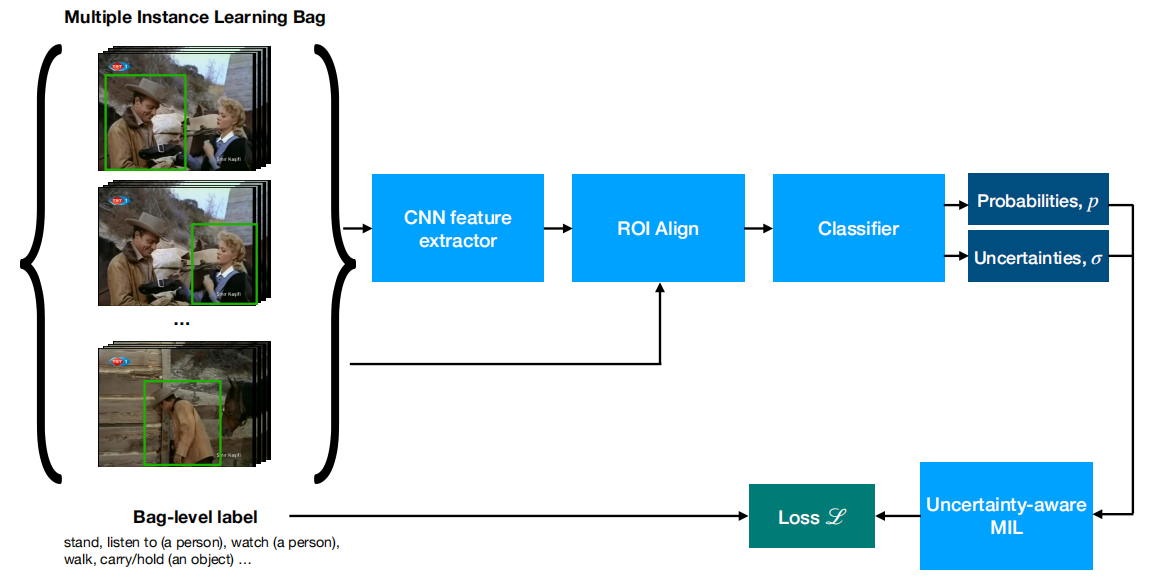
每个bag由从视频clip中提取的所有teblets组成。这些tubelets是使用现成的person检测器获得的,该检测器未在感兴趣的数据集上进行训练。这些tubelets作为Faster-RCNN型检测器的建议,在rgb图像序列上运行。然后将bag中每个tubelets的预测汇总在一起,并与bag级标签进行比较。网络产生的不确定性估计用于补偿训练期间bag级标签中的噪声。
