对Weakly Supervised Relative Spatial Reasoning for Visual Question Answering的进一步总结
作者研究了VQA模型是否能够解决GQA挑战中图像中物体之间的空间关系问题。研究结果表明,尽管模型正确地回答了其中一些问题(∼60%),但它们不能真实地解决空间关系问题,这就引出了一个问题:VQA模型是否真的理解了场景的几何形状,或者它们是否基于从数据中学习到的虚假相关性来回答空间问题?基于此,作者设计了两个考虑三维几何形状的任务,目标质心估计和相对位置估计。将现有的基于transformer的语言模型的训练协议与基于场景三维几何形状的新型弱监督SR任务相结合,即目标质心估计(OCE)和相对位置估计(RPE),OCE训练模型来预测图像中每个物体的质心。RPE被训练来预测投影的单位归一化向量空间中每对不同对象之间的距离向量。
使用了一种开源的单目深度估计方法AdaBins提取深度zc,通过给定的对象边界框[(x1、y1)、(x2、y2)]计算出对象质心坐标(xc、yc、zc),这些坐标对空间推理任务起着弱监督的作用,通过质心坐标计算相对位置估计,得到预测向量[x1−x2,y1−y2,z1−z2],将该成对相对距离向量输入Feedforward Layer。
模型总体结构如下:
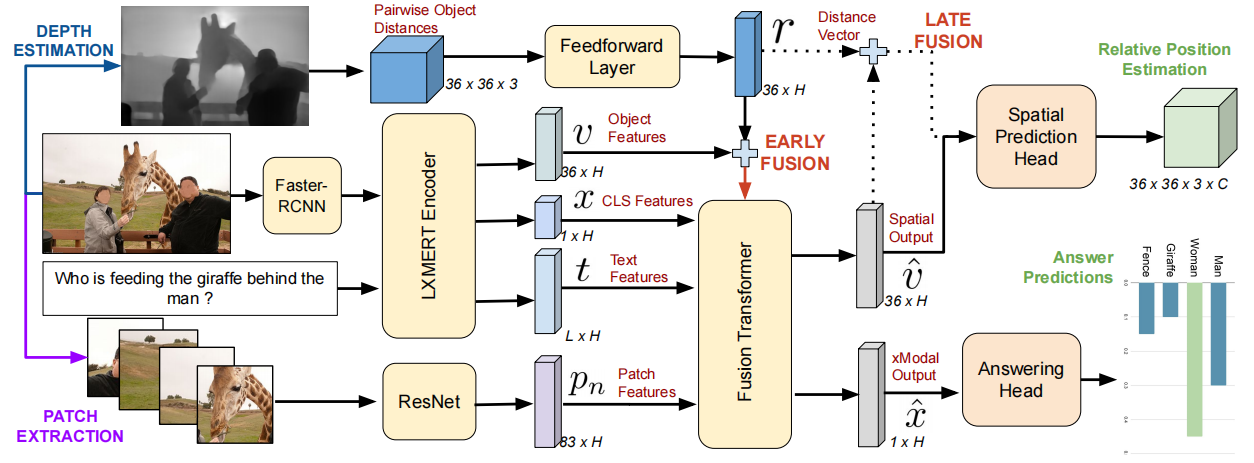
Faster R-CNN对象检测器提取的前36个对象的对象特征作为输入图像的视觉表示,LXMERT编码器的交叉模态注意力层产生视觉特征v∈R36×H、跨模态特征x∈R1×H、文本特征t∈RL×H,H是隐藏维数,L是token数量,这些输出用于微调两个任务的模型:使用x作为输入的VQA,以及使用v作为输入的空间推理任务。为了结合原始图像中的空间特征来捕获相对物体的位置和深度信息,使用空间金字塔patch特征将给定的图像表示到不同尺度的特征序列中。模型还使用成对距离作为输入,并训练模型来重建成对距离。这使得模型成为回归任务的自动编码器。
