
对Weakly Supervised Human-Object Interaction Detection in Video via Contrastive Spatiotemporal Regions的进一步总结
利用来自自然语言句子描述的带有动词和名词短语标注的视频,以弱监督的方式检测视频中的人-物交互,并检测视频多帧中的人和物体边界框,这里的弱监督指的是在训练时不需要边界框注释,同时,允许以零次学习的方式检测罕见和未见过的人-物交互。
主要创新点:引入了一种对比性的弱监督训练损失,可以在无边界框标注的情况下检测人-物交互并生成人类,物体边界框。
整个训练步骤如下图所示。
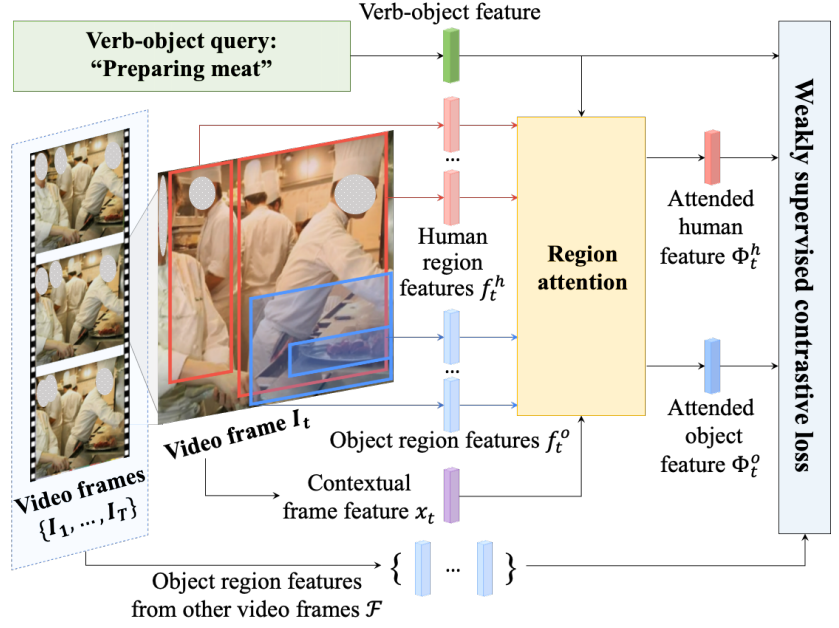
给定一个视频片段和一个动词-对象查询,对于每一帧,首先提取它的人和物体区域特征。人/物体特征聚合进一个区域注意模块中,以关注与查询更相关的区域。利用人类注意力特征、物体注意力特征、动词-宾语查询特征和其他帧的物体区域特征来计算弱监督对比损失。
总体训练损失如下:
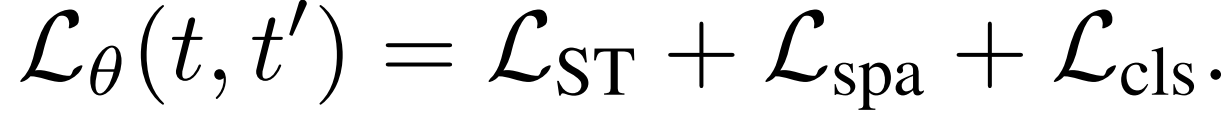
其中,为弱监督对比损失,为稀疏学习损失,为分类损失。
总体损失建立在对比损失的基础上,对比损失旨在促使单位长度特征的正对接近(用点积测量),负对在特征空间中距离很远。
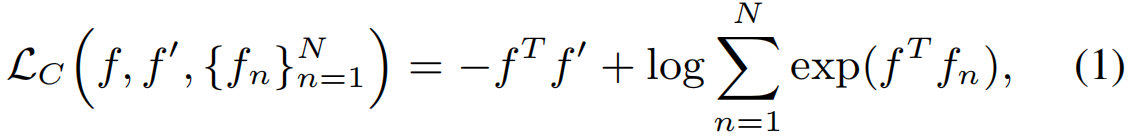
其中f为anchor特征,f’为正特征,{fn}Nn=1为N个负特征。基于上式,提出了一种弱监督语言嵌入对齐损失来对齐时空区域与输入动词-宾语查询,以及一种自监督时间对比损失,以鼓励目标区域的时间连续性.
