D2-Net: weakly-supervised action localization via dis criminative embeddings
0.前言
摘要
这项工作提出了一个弱监督的时序动作定位框架,称为D2-Net,它致力于利用视频级监督在时间上定位动作。我们的主要贡献是引入了一种新的损失公式,它联合增强了潜在嵌入的识别性和输出的时序类激活对弱监督引起的前背景噪声的鲁棒性。所提出的公式包括用于增强时序动作定位的判别和去噪损失项。判别项包含了分类损失,并利用自顶向下的注意力机制来增强潜在前-背景嵌入的可分离性。消噪损失项利用自底向上的注意力机制,同时最大化视频内和视频间的互信息,明确地解决了类激活中的前景-背景噪声。结果,前景区域的激活被增强,而背景区域的激活被抑制,从而产生更可靠的预测。在多个基准上进行综合实验,包括THUMOS14和ActivityNet1.2。与所有数据集上的现有方法相比,我们的D2-Net表现良好,在THUMOS14上IoU=0.5的mAP方面获得了高达2.3%的收益。
1.介绍
时间动作定位是一个具有挑战性的问题,其目的是在视频中对动作的时序边界进行分类和定位。大多数现有的方法[42,5,41,33,48,35]都是基于强监督,需要在训练过程中手动标注动作的时序边界。与这些强帧级监督的方法相比,弱监督的动作定位学习在视频中定位动作,只利用视频级别的监督。因此,弱监督动作定位显得尤为重要,因为在视频中对时序边界进行人工标注不仅费力,昂贵,而且容易产生较大的变化[31,30]。
现有的用于弱监督动作定位的方法[38,39,24,26,34]通常使用动作类形式的视频级标注,并学习一系列class-specific分数,称为时序类激活映射(TCAMs)。通常采用分类损失的方法来获得TCAMs中具有判别性的前景区域。一些方法[24,26,23,25]使用动作标签学习TCAMs并通过后处理步骤获得时序边界,而另一些方法[34,16]使用tcam生成的视频分类分支以及显式的定位分支直接回归动作边界。然而,定位性能在很大程度上依赖于tcam的质量。在具有全监督设置的帧级标注的情况下,TCAMs的质量可能会提高。这种帧级信息(真实的前景和背景区域)在弱监督范式中是不可用的。在这种范式中,预测的前景区域通常与ground-truth背景区域重叠,而预测的背景区域很可能与ground-truth前景区域重叠。这就导致了学习到的tcam中的噪声激活,即假阳性和假阴性。目前大多数弱监督动作定位方法通常依赖于分离前景和背景区域(前-背景分离)学习TCAMs,并且没有明确地处理其噪声输出。
在这项工作中,我们解决了前背景分离的问题,并明确处理了用于弱监督动作定位的TCAMs中的噪声问题。我们提出了一个统一的损失公式,共同优化分类和时间定位视频中的动作片段(一组帧)。我们的损失公式包括判别和去噪损失项。判别损失试图通过互联分类和定位学习目标(第3.1节)最大程度地将背景与动作(前景)区分开来。去噪损失(第3.2节)通过明确地处理激活过程中的前背景噪声来补充判别项,从而产生健壮的TCAMs(见图1)。

图1所示。我们提出的损失公式对输出TCAMs质量的影响。与基线相比(没有我们的判别和去噪损失项),判别损失项的引入改善了前景和背景激活之间的分离(例如,从左至右的第三和第四个ground-truth动作实例)。此外,我们的最终D2-Net由判别和去噪损失项组成,减少了TCAMs中的噪声,产生更健壮的TCAMs。
在我们的损失公式中,我们学习了不同的潜在嵌入,这样它们的前背景分离是基于输出TCAMs产生的相应自上而下的注意力而最大化的。此外,嵌入被用来根据前景得分(自底向上的注意力)生成伪标签。通过强调伪前景区域中相应的输出激活,同时抑制伪背景区域中的激活,这些伪标签被用来明确地处理噪声。这种伪背景抑制和伪前景增强是通过最大化激活和在动作视频(视频内)中生成的伪标签之间的互信息(MI)来实现的。最大化预测激活和标签之间的互信息(MI)降低了预测的不确定性,从而导致更稳健的预测。除了捕捉视频内的MI,我们的公式还努力在一个MIni-batch的视频间(inter-video)最大化动作类预测和视频级ground-truth 标签之间的MI。
贡献:我们引入了一个弱监督动作定位框架,D2-Net,它包含了一个新的损失公式,同时增强前景-背景的可分离性,并明确处理噪声以使输出的TCAMs更robust。我们的主要贡献是:
•我们引入了一个判别损失项,它同时针对视频分类和增强的前背景分离。
•我们引入去噪损失项来提高TCAMs的鲁棒性。我们的去噪损失通过最大化视频内(intra-video)和视频间(inter-video)激活和标签之间的MI,明确解决了TCAM中的噪声问题。据我们所知,我们是第一个引入了一个损失项,同时捕获一个视频中的多个片段和一个batch中所有视频的MI,以进行弱监督动作定位。
•在多个基准上进行实验,包括THUMOS14[7]和ActivityNet1.2[3]。我们的D2-Net在所有数据集上优于现有的弱监督方法,在THUMOS14上IoU=0.5获得高达2.3% mAP的增益。
2.相关工作
在动作定位的上下文,研究了几种弱监督策略,包括类别标签[38,24,39,26,34,46],稀疏时序点[20],动作顺序[29,2],实例数[23,44]和单帧标注[18]。现有的弱监督动作定位方法大多采用类别标签作为弱监督,通常利用从骨干网中提取的特征对动作识别任务进行训练[40,4]。[39]的工作提出了检测相关时序片段的选择模块,并采用分类损失进行训练。Autoloc方法[34]通过添加显式定位分支扩展了[39],并利用内外对比损失对其进行训练。相比之下,[26,9]通过使用分类和基于相似性的损失来匹配成对视频中相似的动作片段,这需要在一个MIni-batch中匹配多个相同动作的视频。与这些作品不同的是,我们的方法通过样本重加权明确解决了大量易负压倒少量硬正的问题,并通过互联分类和定位目标执行前景-背景分离。
片段级损失:[25]的工作采用了背景感知损失和自导向损失对背景进行建模,而[22]还采用了迭代多遍擦除步骤来发现TCAMs中不同的动作片段。不同的是,[17]中的训练在通过期望最大化更新键实例分配分支和分类分支之间交替进行。相比之下,[13]最近的工作是根据前景类的特征大小和熵对前地面/背景片段进行分类。然而,所有这些方法都聚集了训练中每个片段的损失,并且没有明确地捕获激活和标签之间的互信息(MI),这可能更有利,因为在弱监督设置中没有片段级别的标签。不同于现有的方法[25,22,17,13,23,24,1,9],我们的方法通过利用类激活和相应标签之间的视频间和视频内MI来解决前景背景噪声问题,从而产生健壮的TCAM。据我们所知,我们是第一个提出弱监督的动作定位方法的人,该方法同同时捕获一个视频中的多个片段和一个MIni-batch中所有视频的MI(参见图4)。
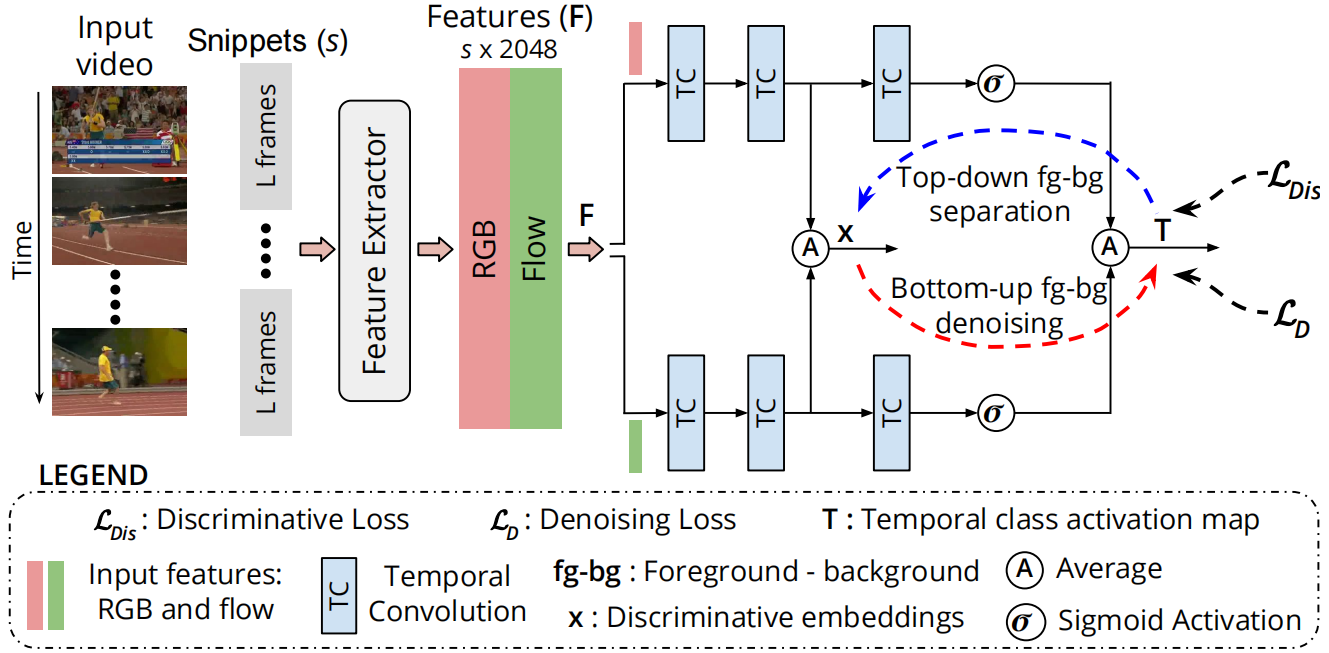
图2。我们D2-Net的总体架构。我们设计的重点是引入一种新的损失公式,它联合增强了潜在嵌入的识别性,并明确地解决了输出类激活中的前-背景噪声。该网络包括两个相同的并行流(RGB和flow),由三个时序卷积TC层组成。对来自两个流的第二个TC层激活进行平均,以获得潜在嵌入x。然后对两个流的最终输出进行平均,以获得未修剪输入视频的时序类激活映射(TCAMs) T。判别损失LDis (3.1节)除了实现视频分类外,还引入了自顶向下的注意力机制,以增强embeddings x的前背景可分离性![]() 。此外,去噪损失LD (第3.2节)引入了自底向上的注意力,明确解决了T的类激活中的前-背景噪声
。此外,去噪损失LD (第3.2节)引入了自底向上的注意力,明确解决了T的类激活中的前-背景噪声![]() 。利用损失项LDis 和LD共同对网络进行训练。
。利用损失项LDis 和LD共同对网络进行训练。
3.提出的方法
我们的D2-Net致力于改善视频中前-背景特征表示的分离,同时提高输出TCAMs关于前-背景噪声的鲁棒性。这使得前景动作和周围背景区域有了更好的分离,从而增强了动作在具有挑战性的弱监督环境中的定位能力。在这里,我们首先介绍我们的总体架构,然后详细描述我们为训练D2-Net提出的损失。
D2-Net的总体架构如图2所示。给定一个视频v,我们把它分成L = 16帧的互不重叠的片段。然后提取特征来编码外观(RGB)和运动(光流)信息。与[24,26,23]类似,我们使用Inflated 3D (I3D)[4]获得每个16帧片段的d = 2048维特征。设F∈Rs×d 表示视频的特征,其中s为片段数。提取的特征作为我们的D2-Net的输入,D2-Net由两个并行的RGB流和光流组成。每个流由三个时序卷积(TC)层组成。前两层从输入特征F学习潜在判别嵌入x(t)∈Rd/2(时间t∈[1,s]),最后一个TC层的输出通过sigmoid激活。随后,对两个流的输出进行平均,得到TCAMs T∈Rs×C 表示C个动作类随时间变化的class-specific得分序列。我们工作的主要贡献是引入一种新的损失公式来训练提出的D2-Net。我们的训练目标结合了判别(LDis)和去噪项(LD),并使用了一个平衡权重α,
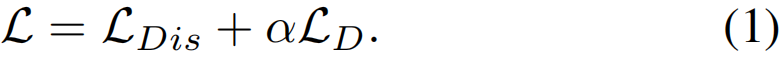
这两个损失项利用相反方向的前背景注意力序列:(i)判别损失LDis利用自顶向下的注意力,它是从输出的TCAMs(最顶层)计算得到。(ii)去噪损失LD利用了一个自下而上的注意力,这是从潜在嵌入(中间层特征)的前景分数中衍生出来的。我们将在第3.1和3.2节中详细描述这些损失。
3.1.Foreground-Background判别:LDis
在这项工作中,我们引入了一个判别损失(LDis),利用TCAMs自顶向下的注意力,学习在潜在嵌入方面,可分离的class-agnostic的前景和无动作的背景特征表示。具有s个片段的视频的嵌入是通过基于类activations T∈Rs×C的加权时序池化来定义的。让自上而下的前景注意力λ(t) = maxc T[t, c]表示所有动作类c∈{1,…, C},其中t∈[1,s], C是类的个数。那么,class-agnostic前景和背景嵌入是:
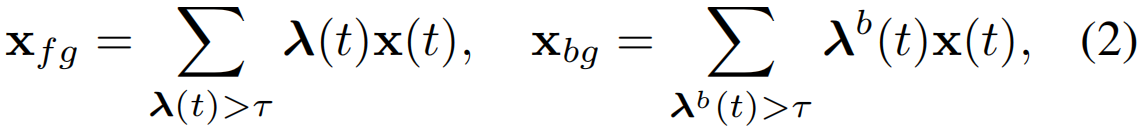
其中τ=0.5,λb(t)=1−λ(t)是背景注意力。最大化前景和背景嵌入之间的距离增强了相应输出激活的可分离性,从而改善了定位。此外,不同的动作类集合之间可能具有某些相同的特征,如掷链球和掷铁饼具有相似的空间上下文和动作。因此,在粗级别上聚合前景嵌入可能有助于“从粗到细”的片段级分类。类似地,聚合背景嵌入有助于学习近似的通用背景嵌入,这可能有助于在测试时推广到新的背景。因此,在我们的LDis中引入了三个权重项wfb,wfg和wbg,分别针对前景-背景分离,前景分组和背景分组。它们被定义为:
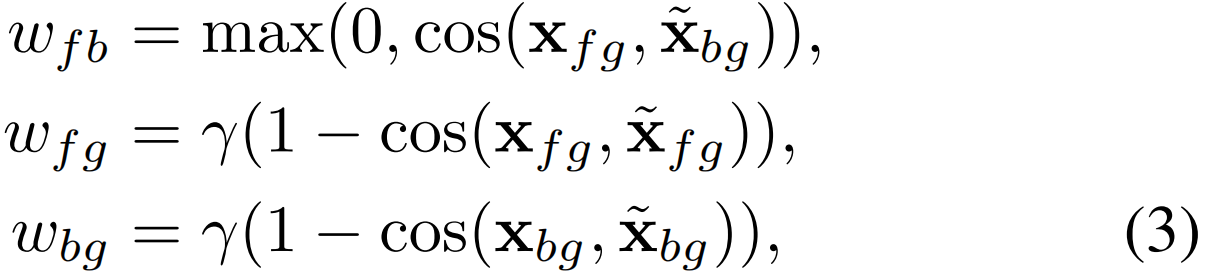
其中x和![]() 表示来自MIni-batch中不同视频的嵌入。在这里,γ表示用于分组相同类(前景vs.背景)嵌入的类内紧凑性权重。除了robust定位,我们的另一个目标是动作类别的多标签分类。类不平衡问题引入了一个主要的挑战,即简单的背景片段的数量远远超过了困难的前景。为了解决这个问题,我们受到了用于目标检测[14]的focal loss的启发,我们建议在我们的LDis中包含基于权重(等式3)的惩罚项。为此,通过对T进行时序top-k池化得到视频级预测p∈RC。我们的LDis项同时解决类别平衡问题并增强前景-背景分离,定义为
表示来自MIni-batch中不同视频的嵌入。在这里,γ表示用于分组相同类(前景vs.背景)嵌入的类内紧凑性权重。除了robust定位,我们的另一个目标是动作类别的多标签分类。类不平衡问题引入了一个主要的挑战,即简单的背景片段的数量远远超过了困难的前景。为了解决这个问题,我们受到了用于目标检测[14]的focal loss的启发,我们建议在我们的LDis中包含基于权重(等式3)的惩罚项。为此,通过对T进行时序top-k池化得到视频级预测p∈RC。我们的LDis项同时解决类别平衡问题并增强前景-背景分离,定义为
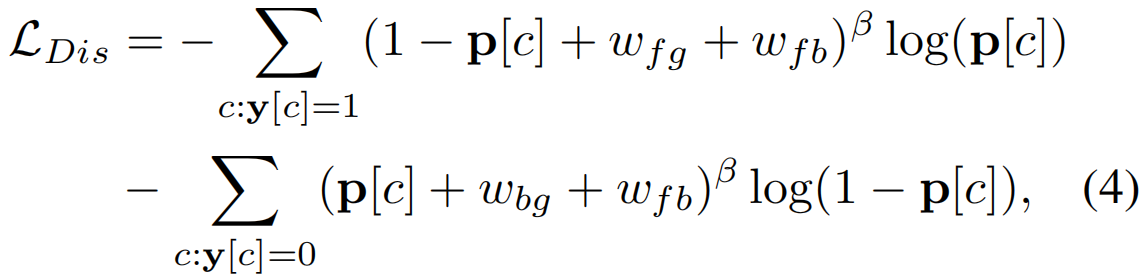
其中y∈{0,1}C 表示视频级标签,β为聚焦参数。式4中的第一项表示阳性动作类的损失,而第二项包含了阴性类的损失。权重项wfb(见等式3)是为阳性动作类和背景类添加的,因为它代表前背景分离。wfg和wbg项分别增强了正类和背景类的类内紧凑性。在等式中4的第一项表示只有当(i)其预测概率p[c]较高,以及(ii)对应视频的前景分组wfg和前景-背景分离wfb同时较低时,阳性动作类c造成的损失才较低。类似的观察也适用于第二项对负类的观察。因此,LDis通过鼓励前景-背景分离,同时实现分类,提高了嵌入x(t)的可辨别性。
3.2.鲁棒时序类激活映射:LD
我们的判别损失LDis通过增强潜在嵌入的独特性,改进了动作定位。然而,在弱监督下,真实前景区域的时间位置是未知的,导致从视频级标签中学习到的输出时间类激活有噪声(以及自上而下的噪声注意力)。因此,从自上而下的注意力λ(t)中学习到的前景和背景嵌入(xfg和xbg)很可能是有噪声的。我们的目标是明确地减少由于缺少片段级标签而引起的前景-背景噪声,并提高输出类激活的鲁棒性。为此,我们引入了一种由一种新的基于伪行列式的互信息(pDMI)损失组成的去噪损失LD。我们的LD利用了类激活和相应标签之间的视频内和视频间的互信息(MI)。
我们的基于伪行列式的互信息(pDMI)损失是受基于行列式的互信息(DMI)[43]的启发。DMI是为多类分类提出的,计算为联合分布矩阵的行列式,即 DMI(P, Y)=|det(U)|。这里,U = 1/nPY是预测后验概率P和ground-truth (有噪声)标签Y的联合分布。矩阵P和Y大小分别为C × n和n × C,其中n为MIni-batch大小,C为类数。DMI损失LdMI被定义为
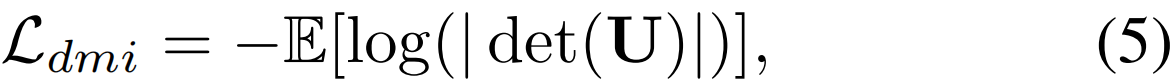
其中E表示期望。请注意,LdMI依赖于U的行列式,为了确保det(U)非零,标签矩阵Y必须是满秩的,即MIni-batch必须包含所有类的实例。对于大量的类来说,这是不可行的。这种用于动作定位的MIni-batch采样也会导致gpu中的内存问题,因为数据集中的未修剪视频的持续时间很长,特别是在捕获视频间MI时。
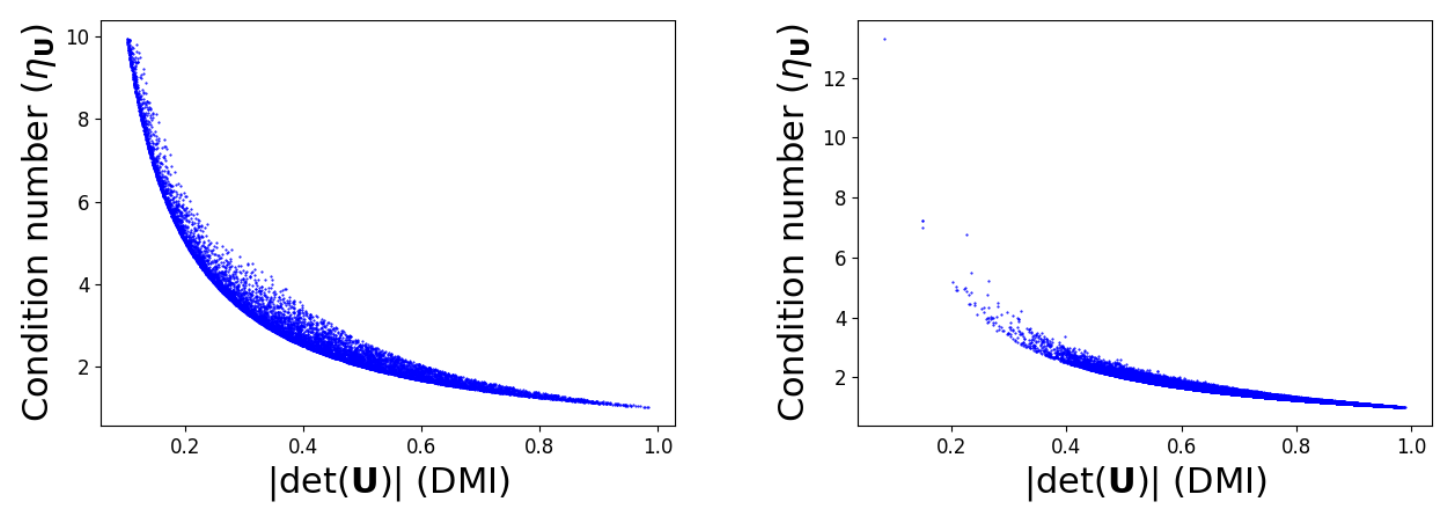
图3。条件数(ηU)和联合分布矩阵U的行列式(|det(U)|)的比较。左边: 25k随机抽样的U。右边:在我们的snippet-level训练中得到U。在这两种情况下,最小化ηU导致最大|det(U)| (DMI)。
我们的pDMI损失克服了这些限制,通过避免显式的行列式计算,确保了DMI的非退化值。为此,我们观察到,若DMI损失趋于零,则联合分布的行列式| det(U)|必须趋于1。在形式上,
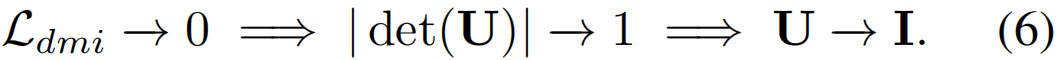
因此,当|det(U)|=1时,DMI最大,单位矩阵I是大小为C×C的U的最优解(因为U的元素∈[0,1])。此外,最优解I的条件数η最小,即η=1。因此,不需要最大化| det(U)|,我们可以选择最小化它的η。实际上,U的条件变得更好,这提高了对标签噪声的激活的鲁棒性。提出的pDMI损失LpdMI则由下式给出
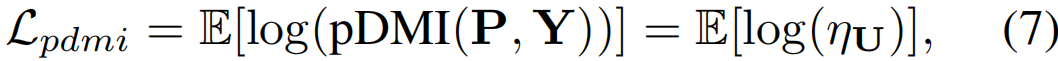
其中ηU表示U的条件数,由于U的秩为r≤C,因此ηU计算为σ1/σr,其中{σ1,…,σr}为U的非零奇异值。因此,我们的pDMI损失避免了显式的行列式计算,并克服了标准DMI的限制。图3显示了关于联合分布矩阵U,ηUvs|det(U)|,U分别为随机采样(左)和在视频内MI训练中遇到(右,见3.2.1节)。可以观察到最小化ηU确实使|det(U)|,即DMI,最大化,相应地最大化MI。因此,当使用有噪声的时序动作标签进行优化时,我们的pDMI可以作为原始DMI的一个很有前途的替代方案。
3.2.1片段级和视频级噪声去除
为了增强tcam的鲁棒性,我们在两个层面上使用了LpdMI:(i)snippet-level利用intra-video MI, (ii)video-level利用inter-video MI。snippet-level去噪融合了自底向上的注意力,强调前景动作,同时通过捕捉视频中时序激活和相应前景标签之间的MI来抑制背景动作。另一方面,视频级去噪步骤利用视频表示和对应标签之间的MI,跨视频,以实现相同的目标。图4给出了带有和不带捕获MI的损失计算的概念图。
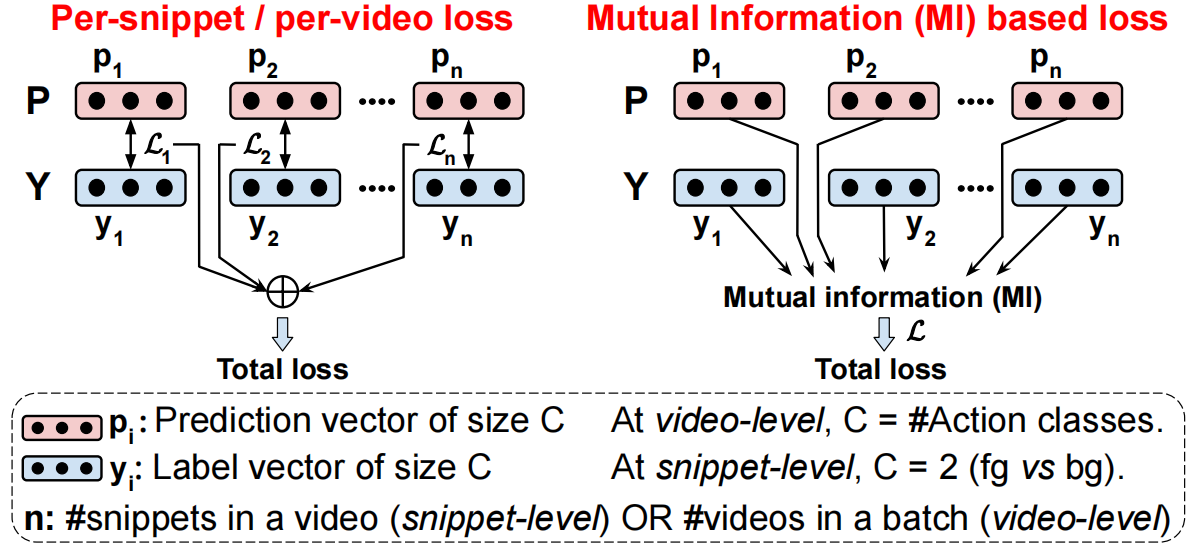
图4。使用(右侧)和没有(左侧)捕获互信息(MI)的损失计算的概念说明。通常,现有的方法通过在每个视频或每个片段级别的预测pi和标签yi之间聚合单个损失(Li),从而得到最终损失,不适用MI(例如交叉熵损失)。与此相反,我们通过捕获预测(P)和标签(Y)之间的MI,计算(i)视频中所有片段(片段级别)和(ii)一个batch中的所有视频(视频级别)的共同损失。
片段级联合分布:它捕获视频中前背景激活和片段级伪标签之间的MI。为此,我们利用了一种自底向上的注意力机制,它为相应片段编码潜在嵌入x(t)的前景分数λ'(t)。分数λ'(t)计算为关于一个相关背景嵌入xref,由下式给出
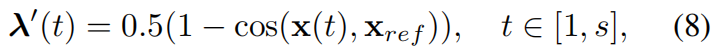
其中,x[m]ref=0.9x[m−1]ref+0.1xµ,[m]bg逐步计算为xbg在m次迭代中的运行平均值。这里,xµ,[m]bg表示迭代m时一个MIni-batch中背景嵌入的平均值。让tf={t:λ'(t)>0.5}和tb={t:λ'(t)<0.5}表示关于λ'(t)选择前景和背景激活的时间瞬间。使用伪前景时序定位tf,一个宽度为nf=|tf|的行矩阵λf采用自顶向下注意力λ(t), t∈tf构造 。同样, 宽度为nb=|tb|的λb是为伪背景片段构造的。然后,预测矩阵P1和伪标签矩阵Y1是由
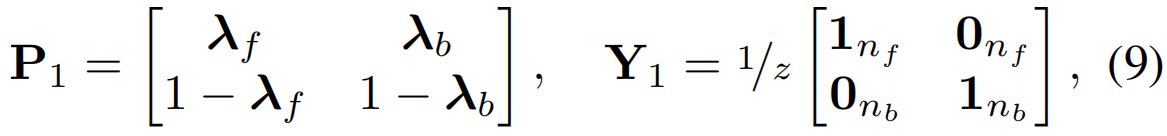
其中z=nf +nb, P1∈R2×z, Y1∈Rz×2, 1k, 0k为1和0的k维列向量。片段联合分布定义为U1=P1Y1。
视频级联合分布:这里,噪声来源于视频级预测p∈RC,这主要是由时序top-k池化引起的。在弱监督设置下,为动作类预测的所有前k个位置不一定都属于那个类。此外,未修剪视频中的动作可能无法跨越![]() 个片段。因此,对视频级预测p进行去噪最终会增强片段激活输出。让预测P2和标签Y2为
个片段。因此,对视频级预测p进行去噪最终会增强片段激活输出。让预测P2和标签Y2为
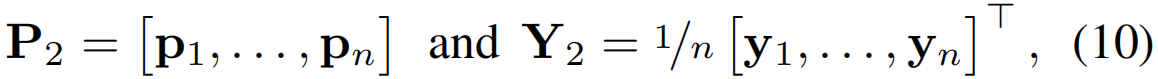
其中pi∈RC 和yi ∈{0,1}C 表示MIni-batch第i个视频的视频级预测和相关标签。那么,在视频中捕捉类激活和动作类之间的MI的视频级联合分布是U2= P2Y2。我们最终将去噪损失定义为
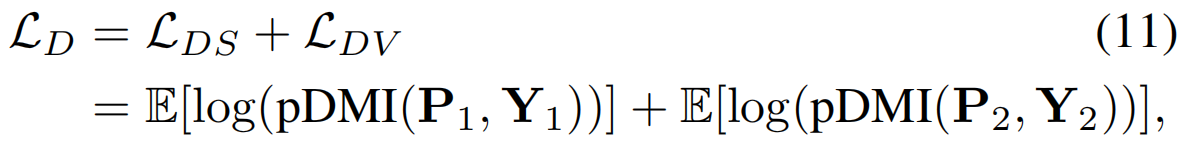
其中的pDMI损失由公式7给出。在这里,LDS和LDV表示片段级和视频级损失。因此,我们的去噪损失改善了TCAMs,在片段级和视频级,通过使它们在弱监督设置下对前景-背景噪声鲁棒。
3.3.推理:从TCAMs进行动作定位
在推理中,给定一个视频,D2-Net输出一个自底向上的注意序列λ'(等式8)。我们执行top-k聚合来获得预测的类概率p∈RC,然后用于寻找阈值pth=0.5max(p)以上的相关动作类。 对于每个相关的类c,其对应的类激活Tc∈Rs与λ'∈Rs相乘,得到一个细化的序列rc=λ'Tc。激活超过阈值的片段被保留,并使用一维连接组件来获得段建议。多个阈值用于获得更大的建议池。然后,利用提案本身的平均激活与其周围区域[34],S=Si−So之间的对比,对每个提案进行评分,其中Si和So分别表示提案及其邻近背景的平均激活。相邻背景是通过在提议的任意一侧膨胀其宽度的25%来获得的,如[34]。使用类级的NMS去除高度重叠的提议。只有高分提案(即 s > sth)保留为最终检测。
4.实验
数据集:我们在多个具有挑战性的时序动作定位基准上评估D2-Net。THUMOS14[7]数据集包含来自20个动作类别的200个验证和212个测试视频的时序标注。数据集具有挑战性,因为每个视频平均包含15个动作实例。如[26,1],验证集和测试集分别用于训练和评估。ActivityNet1.2[3]数据集拥有4819个训练和2383个验证视频中的100个类别的标注,平均每个视频有1.5个活动实例。如[34,26],我们使用训练集和验证集分别进行训练和评估。
实现细节:对于每个片段,从在Kinetics[4]上预训练的RGB和Flow I3D模型中提取2048-d特征。时序卷积层的核尺寸和膨胀率分别为:THUMOS14:(3,1),ActivityNet1.2:(5,2)。每个流的前两次卷积之后是一个负斜率为0.2的漏洞ReLU。我们的D2-Net使用学习率为10-4的Adam[10]优化器,用10的MIni-batch大小进行训练经过20K次迭代,权重衰减为0.005。top-k的k设为![]() ,如[26,23]。所有的超参数都是通过交叉验证选择的。平衡参数α设为0.2和10−3 对于THUMOS14和ActivityNet1.2。对于两个数据集,类内紧凑性权重γ和focusing参数β被设置为0.01和2。从0.025到0.5的多个阈值,以0.025为增量用于提案生成。NMS阈值设置为0.5,评分阈值Sth用于在视频中保留检测,设置为该视频中最大建议评分的10%。
,如[26,23]。所有的超参数都是通过交叉验证选择的。平衡参数α设为0.2和10−3 对于THUMOS14和ActivityNet1.2。对于两个数据集,类内紧凑性权重γ和focusing参数β被设置为0.01和2。从0.025到0.5的多个阈值,以0.025为增量用于提案生成。NMS阈值设置为0.5,评分阈值Sth用于在视频中保留检测,设置为该视频中最大建议评分的10%。
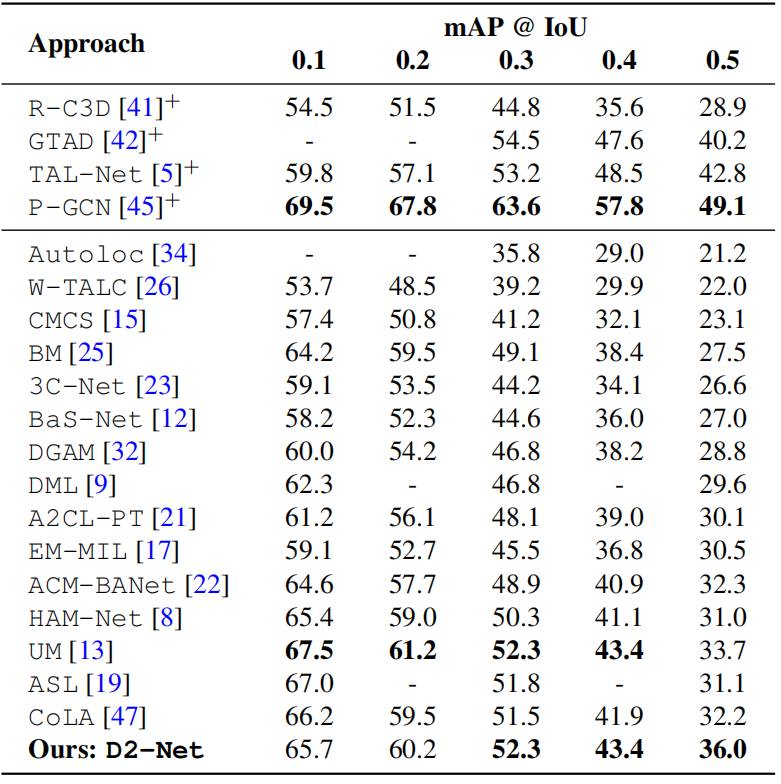
表1。在THUMOS14数据集上进行最先进的比较。上标“+”的方法需要对训练进行强帧级监督。与现有的弱监督方法相比,我们的D2-Net表现良好,并在平均精度均值(mAP)方面实现了一致的改进。
4.1.与SOTA比较
表1和表2分别比较了D2-Net与THUMOS14和ActivityNet1.2上的最先进的方法。带有“+”的方法需要对训练进行强监督。THUMOS14:与我们类似,表1中的所有弱监督方法都使用I3D骨干,Autoloc[34]除外,它使用TSN[40]。但是BM[25]考虑额外的背景类时,DGAM[32]使用VAE[11]扩展了BM。虽然DML[9]和EM-MIL[17]在IoU=0.5时得到的mAP值为29.6和30.5,但它们不能很好地推广到ActivityNet1.2(见表2)。如前所述,最近的工作UM[13]采用了背景片段的非分布检测。我们还通过整合损失项来验证我们的方法与UM的互补性,并观察到不同IOU的平均收益为1%。我们的D2-Net在现有的弱监督方法中表现良好,包括最近的CoLA[47]和ASL[19]。与现有的最佳方法(UM)相比,我们的方法在IoU=0.5时实现了2.3%的绝对收益。此外,在其他IoU阈值处也获得了良好的定位性能
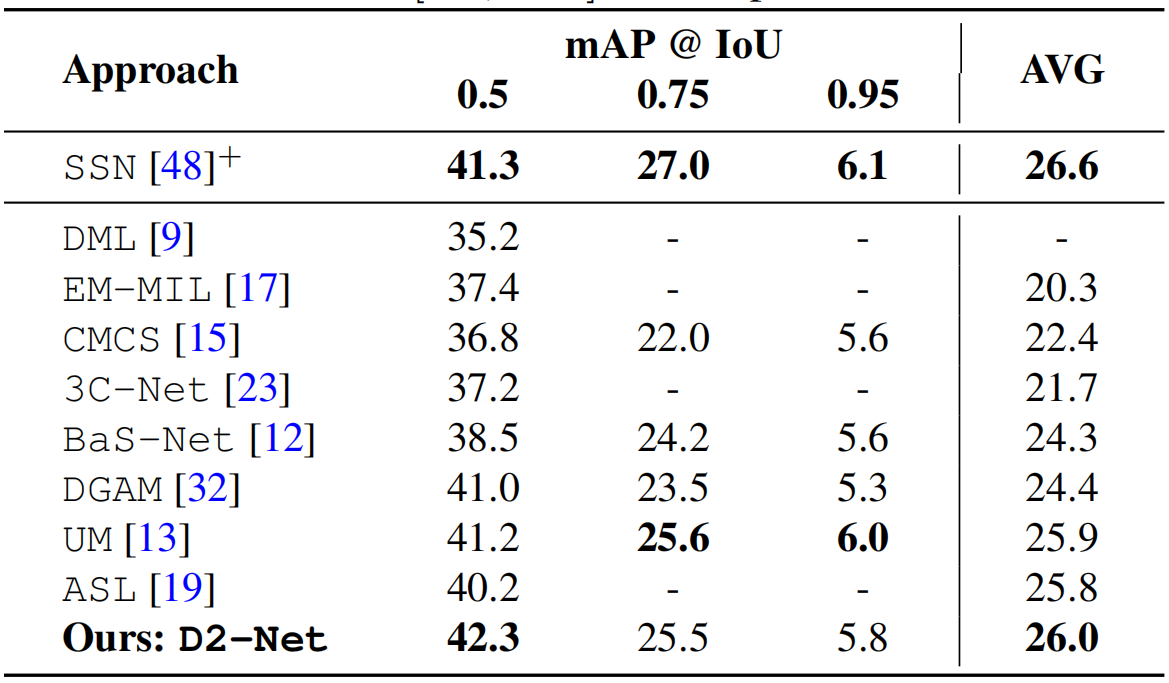
表2。在ActivityNet1.2数据集上的最先进的比较。与现有的弱监督方法相比,我们的D2-Net表现良好。此外,我们的D2-Net性能与SSN[48]相当,SSN[48]经过了严格的监督训练(用上标“+”表示)。AVG表示IoU在[0.5,0.95]中的mAP值平均值,步长为0.05。
ActivityNet1.2:与我们的D2-Net类似,表2中所有弱监督方法都使用I3D骨干网。遵循标准评估协议[3],我们报告不同IoU阈值([0.5,0.95]以0.05的步骤)下的mAP得分平均值(表示为AVG)。基于生成建模的方法DGAM[32]和基于背景抑制的BaS-Net[12]表现相当,平均mAP得分分别为24.4和24.3。相比之下,最近的UM[13]和ASL[19]等方法在平均mAP上的定位性能分别达到25.9和25.8。我们提出的D2-Net的性能与这些现有的方法相比较,并实现了26.0平均mAP的有前景的定位性能。附录中提供了其他结果。
4.2.消融实验
如前所述,我们的D2-Net包含一个判别LDis 和去噪损失LD。在这里,我们通过替换两个提出的损失项(LDis 和LD)在我们的框架中,要么是标准的交叉熵损失LCE 或focal lossLF 。此外,我们还展示了我们的D2-Net仅使用LDis的性能。表3展示了这些在THUMOS14上mAP和F1方面的性能比较。采用标准的交叉熵损失(表3中为LCE)在我们的框架中,在IoU=0.5处的mAP得分为23.0。我们观察到使用标准focal loss进行训练(通过对公式4中的权重w进行归零得到)有助于缓解大量容易样本压倒困难样本的问题。这个设置,表3中的LF,在IoU=0.5时,相比LCE收益为3.7% mAP,从而突出了解决简单背景和困难前景之间不平衡的必要性。据我们所知,我们是弱监督动作定位设置中第一个评估标准focal loss,LF,的工作,我们的带有判别损失项LDis的D2-Net,它同时解决了类别不平衡,增强了背景-前景分离,提供了超过LF的改进并在IoU=0.5时实现32.2%的mAP。通过引入我们提出的LDis代替LF ,就IoU=0.5的mAP而言,获得了5.5%的绝对收益。此外,我们的由LDis和LD组成的D2-Net在IoU=0.5时获得了最好的结果,mAP得分为36.0%。在IoU=0.5时,我们的D2-Net相对于LCE和LF分别实现了12.9%和9.2%的绝对收益。值得注意的是,我们最终的D2-Net,包含两个LDis 和LD,在F1得分上较单独使用LDis显著提高了5.9%。这种对LDis 的改进是由于我们的LD明确地解决了tcam中的噪声而获得的,在不影响召回的情况下,导致假阳性的数量大幅减少(28%)。
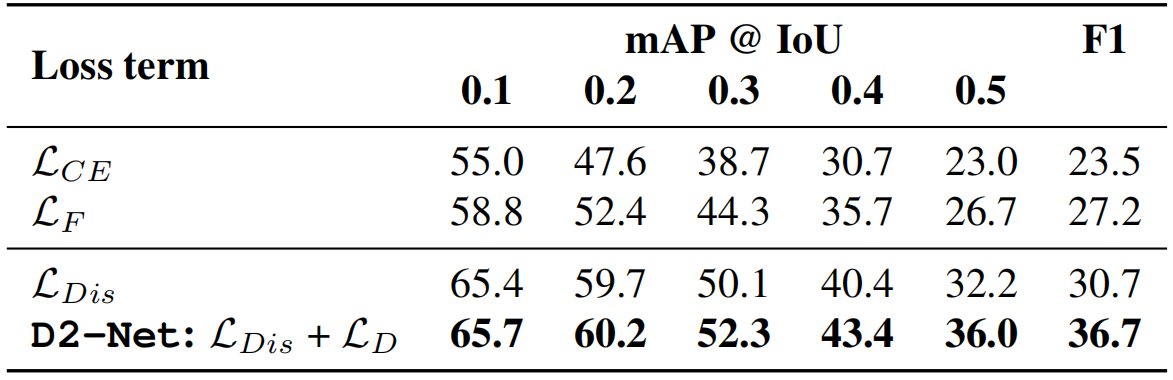
表3。通过用标准交叉熵损失(LCE)或focal损失(LF)替换我们提出的D2-Net中的两个损失项(LDis和LD)来进行性能比较。此外,我们还展示了我们的D2-Net的性能。结果显示,在THUMOS14上,IoU=为0.5时的mAP和F1评分。用LCE和LF替换我们的框架中提出的损失项,IoU=0.5分别为23.0和26.7。我们的具有判别损失项LDis的D2-Net比LF取得了稳定的性能改善,在IoU=为0.5时,mAP的绝对增益为5.5%。此外,我们最终的D2-Net包括两个损失项(LDis和LD)取得了最好的性能,在IuU=0.5时,相对LCE和LF的绝对mAP收益分别为12.9%和9.2%

表4。基于MI的去噪对THUMOS14的影响。我们的D2-Net,在LD中使用基于MI的pDMI损失,比在LD中使用标准损失(L1和BCE)表现更好。
基于MI去噪的影响:我们还进行了一个实验,用标准的L1和BCE损失替换了LD中提出的pDMI损失以对片段激活去噪。L1和BCE损失,没有明确捕获MI,在THUMOS14上IoU=0.5时分别获得32.9%和33.5%的mAP分数(见表4),我们的D2-Net在LD中采用了基于MI的pDMI损失,取得了改进的结果,IoU=0.5时mAP分数为36.0%。这些结果表明,我们基于MI的去噪能够在弱监督设置中鲁棒地增强tcam。

图5。我们提出的D2-Net在样本测试视频上的定性时序动作定位结果,包括跳水,从THUMOS14的掷铁饼动作和ActivityNet1.2的修剪草坪活动。对于每个视频,样本帧(顶行),ground-truth GT片段(绿色),基线检测(红色)和D2-Net检测(蓝色)被显示。检测的高度指示了它的得分。Baseline错误地合并多个GT实例,在背景区域有假阳性,并在整个视频长度内错误地检测出动作的存在。我们的D2-Net正确地检测了多个实例(例如,在Diving中1到5 GT,在Throw Discus中3到5 GT),并抑制了背景区域中的大多数假阳性,实现了有前景的定位性能。
定性结果:图5显示了基线(红色)和D2-Net(蓝色)以及ground-truth (GT)动作片段(绿色)的定性比较。基线只采用LF 与图1中使用的基线相同。从THUMOS14的潜水和掷铁饼动作的例子测试视频显示在前两行。基线错误地合并了多个GT实例(例如,在Diving中1到5 GT),并在背景区域产生假阳性(例如,朝着Diving视频开始的方向)。我们的D2-Net正确地检测到这些多个动作实例,并抑制了背景区域中的大多数误报。第三行显示了一个使用ActivityNet1.2中修剪草坪活动的样本测试视频。基线错误地检测了整个视频长度中动作的存在。相比之下,我们的D2-Net改进了对多个活动实例的检测,带来了良好的定位性能。附录中提供了其他结果和讨论。
5.结论
我们提出一种被称为D2-Net的弱监督动作定位方法,它包括判别和去噪损失。判别损失项通过相互联系的分类和定位目标努力改善前-背景可分离性。消噪损失项是对判别项的补充,它解决了激活过程中的前背景噪声问题。这是通过最大化激活和视频内(视频内)和跨视频(视频间)标签之间的互信息来实现的。在多个基准上进行的综合实验表明,我们的D2-Net在所有数据集上优于现有方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号