FTCL:Fine-grained Temporal Contrastive Learning for Weakly-supervised Temporal Action Localization
摘要
我们的目标是弱监督动作定位(WSAL)任务,在模型训练过程中只有视频级的动作标签可用。尽管近年来取得了一些进展,但现有的方法主要遵循于通过优化视频级分类目标来实现定位的方式,这些方法大多忽略了视频之间丰富的时序对比关系,因此在分类学习和分类-定位自适应的过程中面临着极大的模糊性。本文认为通过考虑上下文的序列到序列对比可以为弱监督时序行为定位提供本质的归纳偏置并帮助识别连续的行为片段。具体来说,在一个可导的动态规划框架下,设计了两个互补的对比目标,其中包括细粒度序列距离(FSD)对比和最长公共子序列(LCS)对比,其中,第一个通过使用匹配、插入和删除操作符来考虑各种动作/背景建议之间的关系,第二个挖掘两个视频之间最长的公共子序列。两种对比模块可以相互增强,共同享受区分动作-背景分离的优点,减轻分类和定位之间的任务差距。大量的实验表明,我们的方法在两个流行的基准测试上达到了最先进的性能。
1.介绍
动作定位是计算机视觉中最基本的任务之一,其目标是在一个未经裁剪的视频中定位不同动作的开始和结束时间戳[41,63,67,75]。在过去的几年里,在全监督的环境下,性能经历了惊人的增长。然而,收集和注释精确的帧级信息是一个瓶颈,因此限制了完全监督框架在真实场景中的可伸缩性。因此,研究了弱监督动作定位(WSAL)[26,27,56,69],其中只有视频级类别标签可用。
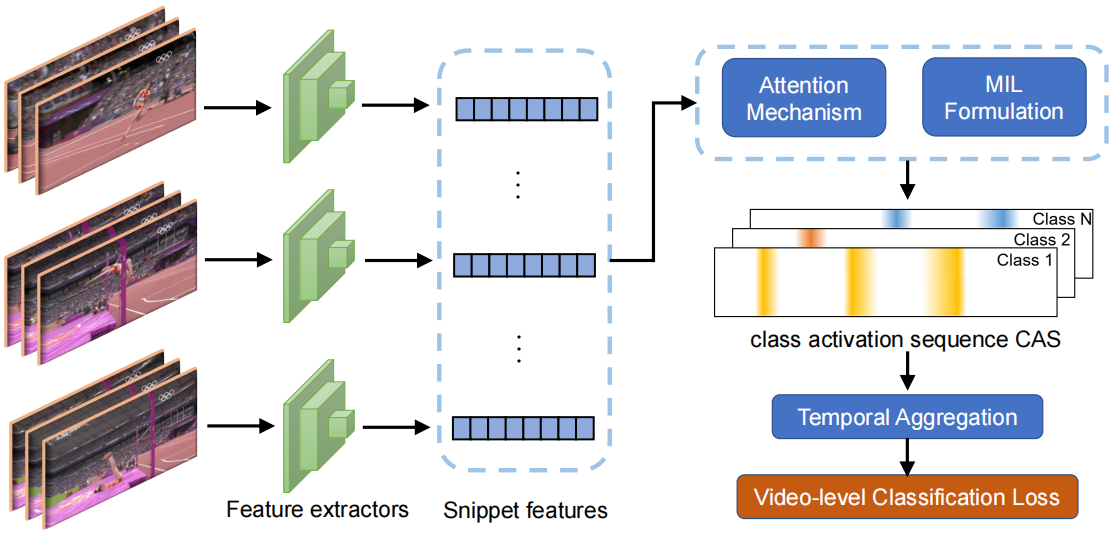
图1所示。分类定位范式的流程。它首先提取出snippet级特征,采用注意力/MIL机制,在视频级监督下学习CAS。
到目前为止的文献中,目前的方法主要采用分类定位的方法[54,57,65,68],这种方法将每个输入的视频分成一系列固定大小的不重叠片段,目的是生成时序类激活序列(temporal Class Activation Sequences, CAS)[56,71]。具体来说,如图1所示,通过优化视频级分类损失,大多数现有的WSAL方法采用多实例学习(MIL)公式[45]和注意力机制[56]来训练模型分配具有不同类激活的片段。通过阈值化和合并这些激活来推断最终的动作定位结果。为了提高学习CAS的准确性,提出了各种策略,如不确定性建模[69],协同学习[26,27],动作单元记忆[42],因果分析[37]等,取得了很好的效果。
尽管取得了显著的进展,但上述学习流程仍然存在严重的定位歧义,由于在时间维度中缺乏细粒度的帧级注释,这极大地阻碍了按分类定位范式的WSAL性能。具体来说,歧义是双重的:(1)在弱监督设置中没有足够的注释,学习的分类器本身没有足够的区别和鲁棒性,导致了动作-背景分离的困难。(2)由于分类和定位之间存在较大的任务差距,学习到的分类器通常专注于易于区分的片段,而忽略那些在定位中不突出的片段。因此,局部的时间序列往往是不完整和不精确的。

图2。两个视频之间细粒度的时间区别。这里,这两个未修剪的视频来自同一个动作类别:CleanAndJerk。注意这些区别来自两个方面:(1)精细的动作背景区别。动作实例中的片段和背景子序列在语义上是不同的,在鲁棒WSAL模型中应该有效地将其分离。(2)动作实例之间的细粒度区别。在本例中,Video2中的动作实例的三个片段可以与Video1中的部分动作实例对齐。此外,我们可以观察到红色箭头所链接的三个片段是两个视频中最长的公共序列。我们认为,考虑上述细粒度的区别可以有利于WSAL学习。
为了缓解上述模糊性,我们认为视频自然提供了丰富的时间结构和额外的约束,以改善弱监督学习。如图2所示,一个动作视频通常包含一系列细粒度的片段,而不同的动作/背景实例具有相关的和细粒度的时间差别。例如,给定一对来自相同动作类别但拍摄于不同场景的视频,两个视频之间存在潜在的时间关联。考虑到这一点,一个关键的考虑是利用这种时间差异来改善WSAL中的表征学习。然而,当仔细比较两个视频时,不能保证它们可以直接对齐。最近,动态时间规划(dynamic time warping, DTW)[2,55]被提出,用于解决各种视频分析任务中的错位问题,如动作分类[25],few-shot学习[7],动作分割和视频摘要[9,10]。DTW根据动态规划中的最佳对齐来计算两个视频之间的差异。然而,上述方法要么假设视频是修剪过的[7,25],要么要求额外的监督[9,10],比如动作顺序,这就阻碍了DTW在WSAL中的直接使用。
在本文中,针对上述问题,我们提出了一个用于弱监督时间动作定位的新型细粒度时间对比学习(FTCL)框架。通过捕捉不同视频序列的独特时间动态,FTCL侧重于优化视频之间的结构和细粒度的片段级关系,利用端到端的可导动态规划目标,损失由结构关系决定。具体来说,(1)为了提高动作背景分离的鲁棒性,我们通过设计一种改进的可导编辑距离度量方法,对比了从不同动作/背景实例对计算出的细粒度序列距离(FSD)。该测量可以通过计算将一个序列转换为另一个序列所需的最小成本来评估两个序列在结构上是否类似。(2)为了缓解分类和定位之间的任务鸿沟,我们将两个包含相同动作的未裁剪视频挖掘的最长公共子序列(LCS)进行对比。同一类别的不同视频序列可以通过优化LCS,为探索完整的动作实例提供互补线索。因此,不同视频序列之间的LCS学习提高了预测动作实例中的一致性。最后,通过对比FSD和LCS,以端到端方式构建了一个统一的框架,而提出的FTCL策略可以无缝地集成到任何现有的WSAL方法中。本文的主要贡献有三个方面:
•根据上述分析,我们认为,通过上下文对比细粒度时间差别来定位动作,在WSAL中提供了一个重要的归纳偏差。因此,我们引入了第一个用于鲁棒WSAL的判别sequence-to-sequence比较框架,以解决缺乏帧级注释的问题,能够利用细粒度的时序差异。
•设计了一个统一的可导动态规划公式,包括细粒度序列远程学习和最长公共子序列挖掘,该公式具有(1)区分动作背景分离(2)缓解分类与定位之间的任务差距的优点。
•在两个常用基准上的广泛实验结果表明,提出的FTCL算法具有良好的性能。请注意,所提出的策略是与模型无关的,并且具有非侵入性,因此可以在现有方法之上发挥补充作用,从而始终如一地提高动作定位性能。
2.相关工作
全监督时间动作定位 (TAL)。与传统的视频理解任务[8,17,19,20,23]相比,TAL的目标是对未裁剪视频中的每个活动实例进行分类,并预测其准确的时间位置。现有的TAL方法大致可分为两类:two-stage法[11,13,61,63,66,73,75]和one-stage法[4,34,35,41,58,64,67]。对于前者,首先生成动作建议,然后将其输入分类器。这条流程主要致力于提高提案的质量[11,61,75]和分类器的健壮性[63,73]。单阶段方法可以同时预测动作的定位和类别。SS-TAD[4]利用递归神经网络联合回归时间边界和动作标签。Lin等人[34]以从粗到细的方式引入了一个无锚框架。尽管上述模型取得了显著的性能,但全监督设置限制了其在现实世界中的可扩展性和实用性[18,21,22]。
弱监督动作定位。为了克服上述限制,WSAL近年来利用不同类型的监管手段吸引了大量的注意力,例如,web视频[16],动作指令[3],单帧标注[31,44]和视频级类别标签[36,52,65]。在这些较弱的监管中,最后一种监管因其成本较低而最为常用。UntrimmedNet[65]是第一个通过相关片段选择模块为WSAL使用视频级类别标签的作品。目前,大多数现有的方法大致可以分为三种,即基于注意的方法[26,26,39,42,49,56,57,68],基于mil的方法[32,43,45,48,54],以及基于擦除的方法[62,72,74]。基于注意力的方法旨在选择高激活分数的片段并抑制背景片段。通过同时有效地考虑动作实例,上下文和背景信息,ACM-Net[56]研究了一个三分支注意力模块。基于mil的流程将整个视频视为一个包,并使用top-k操作来选择积极的实例。W-TALC[54]为类间和类内信息模型引入了一种协同活动关系损失。基于擦除的方法,如Hide-and-Seek[62],通常在训练过程中尝试擦除输入片段以突出显示不那么有辨别力的片段。
值得注意的是,现有的方法大多只考虑视频级的监督,而忽略了视频之间细微的时间差别,很难从基于片段的对比的有区别的学习中获益。虽然有些方法研究了不同类型的对比正则化,如可乐中的硬片段对比[71],但它们仅通过考虑视频级信息[30,50,54]或忽略细粒度的时间结构[49,53,71]来进行对比。据我们所知,我们是第一个将细粒度时间区别的对比学习引入WSAL任务的人。实验结果表明,提出的FTCL学习判别表示,从而促进动作定位。
视频理解的动态规划。最近的研究表明,学习离散操作的连续松弛(如动态规划)可以使视频表示学习受益[7,9,10,25]。比较流行的框架是采用序列比对作为代理任务,然后使用动态时间规整(dynamic time warp, DTW)来寻找最优比对[2,6,12,14,15,46,55]。例如,基于一种新颖的概率寻径视图,哈吉等人[25]利用可导DTW为视频表示学习设计了对比和循环一致性的目标。Chang等人提出了判别原型DTW,学习class-specific的原型用于时间动作识别。然而,上述动态规划策略要么假设视频被裁剪[7,25],要么要求额外的监督[9,10],如动作指令,因此不能应用于WSAL任务。与上述方法不同的是,本文提出利用细粒度序列距离和最长公共子序列对比实现前景背景的判别分离和鲁棒的分类定位自适应。
3.我们的方法
在这项工作中,我们描述了基于细粒度时序对比学习(FTCL)的WSAL方法。如图3所示,给定一组视频序列对,我们的训练目标是学习应用于每个片段的嵌入函数。我们首先采用特征提取器获取每个片段的外观(RGB)和运动(光流)特征(3.1)。然后,在可导动态规划公式下,设计了两个互补的对比目标,用于学习细粒度时间特征,包括细粒度序列距离(FSD)对比(章节3.2)和最长公共子序列(LCS)对比(章节3.3)。最后,将整个框架进行端到端学习(章节3.4),共同实现区分动作背景分离,缓解分类与定位之间的任务差距。
3.1.符号和准备
给定一个未修剪的视频X,它的真实标签是y∈RC ,其中C为动作类别数。如果第i个动作类出现在视频中则yi = 1,否则yi = 0。对于视频,我们将其分成不重叠的T个片段,并应用特征提取器来获得片段特征X = [x1,…,…, xT]∈RD×T,其中D为特征维数,每个片段有16帧。在本文中,为了进行公平的比较,我们采用了之前的方法[50,54,56,71],使用在Kinetics数据集上预先训练的I3D网络[8]从RGB和光流流中提取特征。然后将这两种类型的特征连接在一起,输入到一个嵌入模块中,如convolutional layers[56],用于生成X。WSAL的目标是学习一个模型,该模型可以同时对视频中所有的动作实例进行定位和分类,时间戳为(ts,te, c,ϕ),其中ts,te, c,ϕ分别表示动作建议的开始时间,结束时间,预测动作类别和置信度得分。
目前主流的方法主要采用分类定位框架,该框架首先学习将片段级特征聚合为视频级嵌入的重要性评分,然后使用视频级标签进行动作分类:
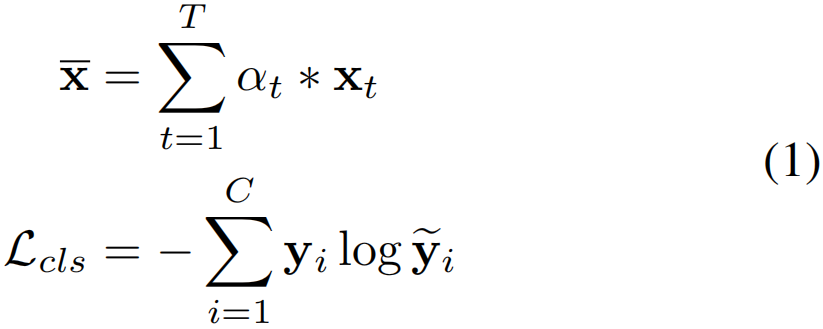
3.2.通过FSD对比进行判别性acion - background分离
为了在上述分类定位框架中学习判别性动作背景分离,现有的一些方法要么使用全局视频特征[30,50,54]进行对比学习,要么只考虑视频内对比而不考虑时域建模[49,53,71]。然而,这些模型忽略了视频之间细粒度的时间差异,导致分类识别能力不足。
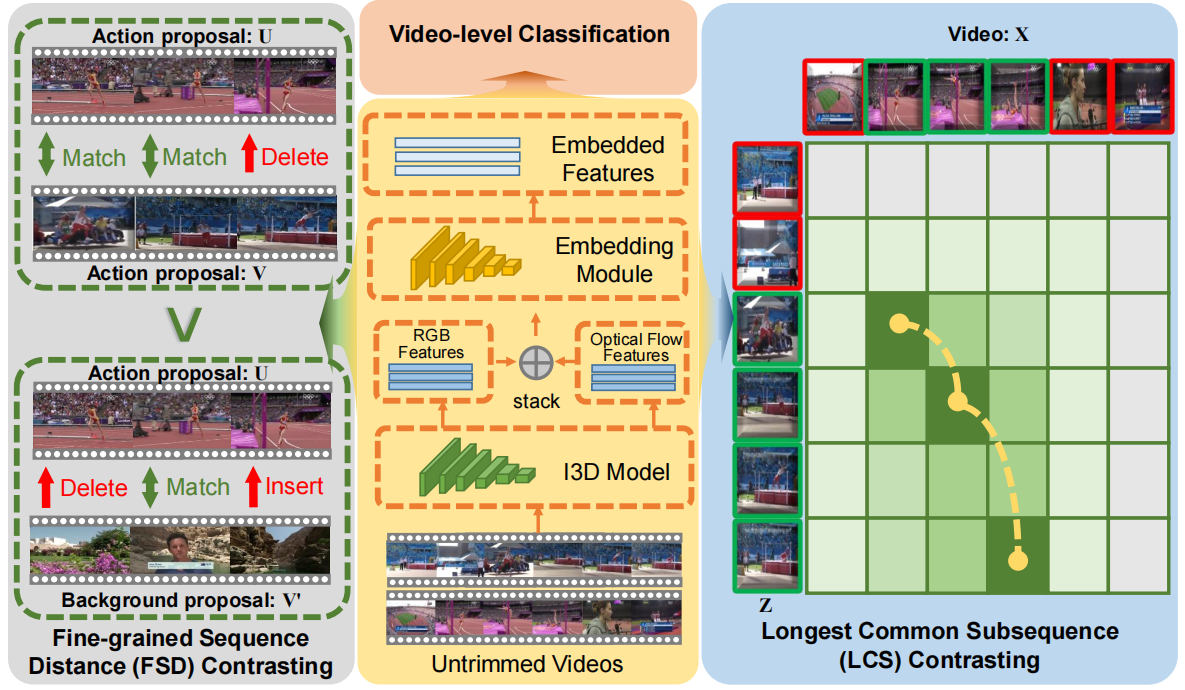
图3。我们提出的FTCL架构和简单示例。首先对输入视频采用预先训练好的I3D模型,得到RGB和光流特征。然后利用嵌入模块在视频级监督下提取片段级特征。为了实现区分动作背景的分离,FSD对比旨在使用匹配、插入和删除运算符考虑不同行动/背景提案之间的关系。为了适应分类到定位,我们使用LCS对比来寻找两个视频之间的最长公共子序列。两种对比策略均通过可导动态规划实现。
在这项工作中,我们提出以细粒度的方式在时间上对比两个视频序列。现有的方法一般通过测量两个序列的全局特征表示之间的向量距离来计算它们的相似度。与这种匹配策略不同的是,如图3左侧所示,我们希望通过评估将一个序列转换为另一个序列所需的最小代价来确定两个序列在结构上是否相似。天真的想法是详尽地比较所有可能的转换,这是NP-hard。一种快速的解决方案是利用可解决的动态规划技术,其中子问题可以递归地嵌套在更大的问题中。这里,受计算语言学和计算机科学的中广泛使用的编辑距离[51](编辑距离是一种通过计算将一个字符串转换为另一个字符串所需的最小操作数来量化两个字符串之间的不同程度的方法。)启发,我们设计了可导的匹配,插入和删除操作符用于序列之间的相似性计算。具体来说,使用学习到的CAS,我们可以生成各种行动/背景建议,其中行动建议U包含具有高行动激活的片段,而背景建议V恰恰相反。对于长度为M和N的两个建议序列,U=[u1,...,ui,...,uM]∈RD×M和V=[v1,...,vi,...,vM]∈RD×N,通过以下递归对它们的相似性进行评估:
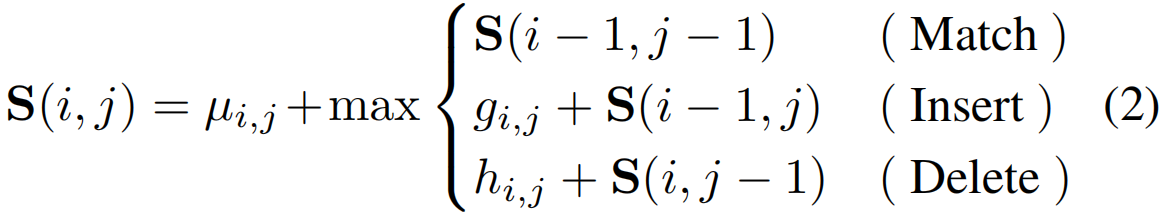
其中,子序列相似度得分S(i,j)在第一个序列U的位置i和第二个序列V的位置j上被计算。S(0,:)和S(:,0)被初始化为零。直观地说,在位置(i,j)中,如果ui和vj相匹配,则序列相似性得分应该增加。如果执行插入或删除操作,应该对相似度评分进行惩罚。为此,我们学习了三种类型的残差值(标量),即µi,j,gi,j和hi,j。以µi,j,gi,j为例,计算方法如下:
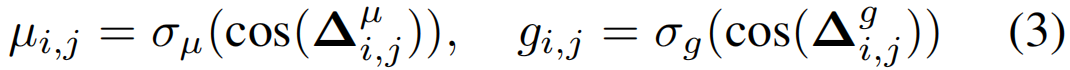
其中,∆µi,j=[fµ(ui),fµ(vj)]和∆gi,j的定义类似。fµ(·),fg(·)和fh(·)是三个全连接的层。我们利用这些函数来模拟不同的操作,包括匹配,插入和删除。σµ和σg是获取残差值的激活函数。
经过上述递归计算,保证了S(i,j)是两个序列之间的最优相似度得分。显然,来自同一类别的两个行动建议之间的相似性应该大于行动建议和背景建议之间的相似性。通过利用这种关系,我们设计了FSD对比损失如下:
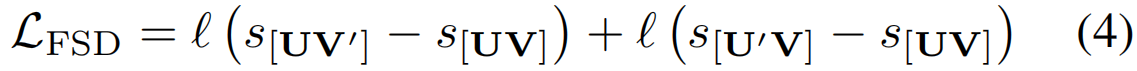
其中,ℓ(x)表示ranking loss。下标[UV]表示来自同一类别的两个计算序列到序列相似度的动作建议s=S(M,N)。U'和V'代表背景建议。在我们的实现中,我们利用学习到的重要性评分α[56]来选择行动和背景建议
平滑max操作。由于等式(2)中的max操作是不可导的,递归矩阵和回溯在当前的公式中无法区分。因此,我们对max操作符[46]使用一个标准的光滑近似:
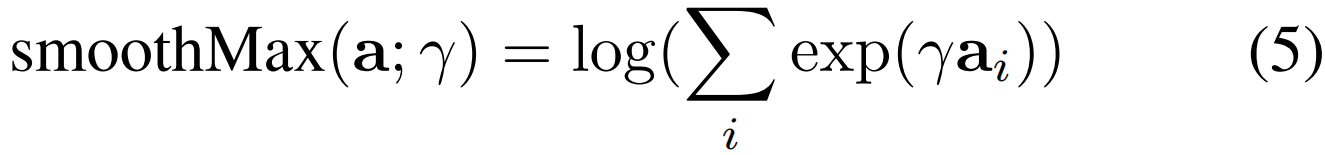
其中a=[a1,...,ai,…]是max操作符计算的向量。γ表示温度超参数。请注意,其他类型的光滑近似[6,12,25]也可以用于微分,而设计一个新的平滑max操作不是我们的论文的目标。
3.3.基于LCS对比的鲁棒分类定位适应
在上一节中,我们考虑了动作背景的分离,提高了学习动作分类器的识别能力。然而,WSAL的目标任务是使用精确的时间戳临时定位动作实例,从而导致分类和定位之间存在很大的任务差异。为了解决这个问题,我们尝试在两个未裁剪的视频X和Z之间挖掘最长公共子序列(LCS),从而提高学习到的动作建议的一致性。这个想法背后的直觉是双重的:(1)如果两个视频没有共享相同的动作,那么X和Z之间的LCS长度应该很小。显然,由于两种类型的动作背景不同,差异较大,两个单独视频的片段很可能高度不一致,导致LCS较短。(2)同样的,如果两个视频共享同一个动作,那么它们的LCS很容易长,因为同一类别的动作实例是由相似的时间动作片段组成的。理想情况下,这种情况下的LCS与较短的动作实例一样长。例如,如图2所示,动作CleanAndJerk由几个顺序的子动作组成,比如蹲下,抓握和抬起。
基于上述观察,如图3右侧所示,我们提出通过设计一种可导动态规划策略对X和Z之间的LCS进行建模。具体来说,我们保持一个递归矩阵R∈R(T +1)×(T +1),元素R(i, j)存储前缀Xi和Zj的最长公共子序列的长度。为了查找前缀Xi和Zj的LCS,我们首先比较xi和zj。如果它们相等,则计算的公共子序列被该元素扩展,因此R(i, j) = R(i−1,j−1)+ 1。在WSAL任务中,由于一对片段即使描述了相同的动作也不可能完全相同,因此我们采用它们的相似性来计算两个序列的累积软长度。为此,我们设计了LCS建模的递推公式:
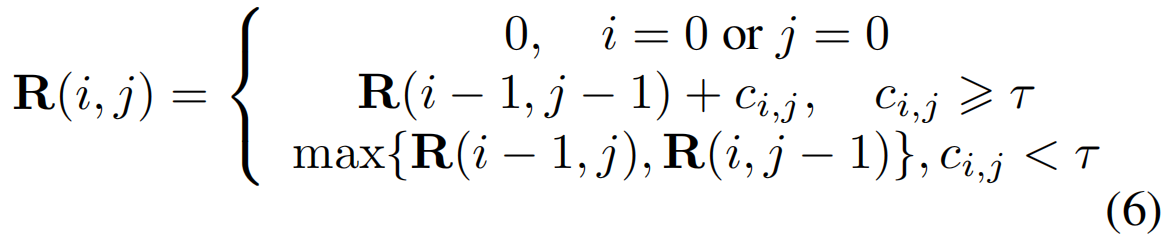
其中,τ是一个阈值,它决定了视频X的第i个片段和视频Z的第j个片段是否匹配。ci,j=cos(xi,zj)是片段xi和zj的余弦相似性。注意,通过使用上面的公式,我们可以寻找两个视频之间最长的公共子序列。虽然这里没有使用,但挖掘的子序列可以定性地证明我们方法的有效性并提高方法的可解释性(第4.3节)。
通过上述动态规划,得到的结果值r = R(T, T)表示两个视频之间的最长公共子序列的soft长度。我们利用交叉熵损失作为LCS学习的约束:
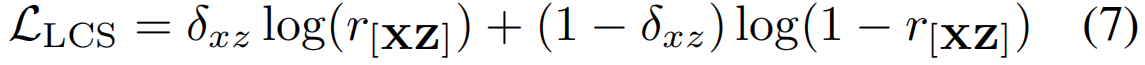
其中,δxz是指示这两个视频X和Z是否具有相同的动作类别的groundtruth。
讨论。本文通过可导动态规划提出了FSD和LCS学习策略,而它们都是针对序列之间的对比设计的。但是这两个模块并不是冗余的,并且有很大的区别:(1)考虑到不同类型的序列,它们的目标是不同的。我们利用FSD学习强大的行动背景分离,同时采用不同的动作和背景建议。而LCS对比性是为了在两个未裁剪的视频中找到一致的动作实例,从而实现分类到定位的适应。(2)二者具有不同的对比水平。在FSD对比中,不同的动作/背景对之间的关系被考虑(等式(4)),而在LCS中,对比是在一对未经裁剪的视频中进行的(等式(7))。我们还证明,在4.3节中,共同学习FSD和LCS可以相互促进和补充,以追求有效的WSAL。
3.4.学习和推理
训练。上述两个目标可以无缝集成到现有的WSAL框架中,并相互协作。为了优化整个模型,我们将分类损失和两个对比损失组成:
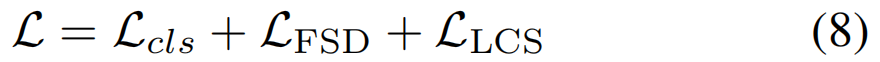
由于我们提出的方法是模型无关的和非侵入性的,这两个对比损失可以很好地配合任何其他弱监督的动作定位目标通过替换Lcls 具有不同类型的损失功能和骨干(请参阅4.3节)。
推理。对于给定的测试视频,我们首先预测片段CAS,然后应用阈值策略来获得遵循标准流程[56]的动作片段候选。最后,将连续的片段分组到动作建议中,然后执行非最大抑制(non-maximum-suppression, NMS)以删除重复的建议。
4.实验结果
我们在两个流行的数据集上评估了所提出的FTCL: THUMOS14[28]和ActivityNet1.3[5]。大量实验结果证明了该方法的有效性。
4.1.实验装置
THUMOS14。它包含了200个验证视频和213个带时间动作边界注解的测试视频,来自20个动作类别。每个视频平均包含15.4个动作实例,这对弱监督的时间动作定位来说是一个挑战。接下来的预览工作[26,37,56,69,71],我们将验证集应用于训练,测试集应用于评估。
ActivityNet1.3。ActivityNet1.3包含200个动作类别的1024个训练视频和4926个验证视频,平均每个视频包含1.6个动作实例。按照之前工作的标准方案[26,37,56,69,71],我们在训练集上进行训练并进行测试
评价指标。根据之前的模型[38,54,65],我们使用在联合(t-IoU)阈值上不同时间交集下的平均平均精度(mAP)作为评价指标。THUMOS14的t-IoU阈值为[0.1:0.1:0.7],ActivityNet的t-IoU阈值为[0.5:0.05:0.95]。
实现细节。在已有方法的基础上,采用在Kinetics数据集上预训练的I3D[8]模型作为RGB和光流特征提取器。输出特征的尺寸是2048。注意,为了进行公平的比较,I3D特征提取器没有应用任何微调操作。THUMOS14和ActivityNet的采样片段数T分别设置为750和75。实现fα(·)和fcls(·)采用预训练的ACM-Net[56]作为视频级分类的骨干。为了与FSD形成对比,我们选择了动作/背景建议使用所学的CAS。对于LCS对比性,为了节省计算成本,我们不使用整个未裁剪的视频,而是选择top-J激活的片段进行对比,J分别被设置为30和10的THUMOS14和ActivityNet。f的输出维数µ(·)和fg(·)是1024。为简单起见,fh(·)和f一样g(·)。式(5)和式(6)中的温度超参数γ和阈值τ分别为10和0.92。我们的模型是用PyTorch 1.9.0实现的,Adam的学习速度是10−4 和batch大小为16的优化。我们训练我们的模型,直到训练损失是平稳的。
4.2.与最新方法的比较
THUMOS14的评估。如表1所示,FTCL在THUMOS14数据集上的几乎所有IoU指标上都优于以前的弱监督方法。具体来说,我们的方法取得了良好的性能,分别为35.6% mAP@0.5和43.6% mAP@Avg。与接近ACM-Net[56]和facc - net[27]的SOTA相比,平均mAP的绝对收益分别为1.4%和1.0%。此外,我们观察到我们的方法甚至可以达到与几个全监督的方法相当的性能,尽管我们在训练中使用较少的监督。请注意,CoLA[71]获得了比我们更高的mAP@0.7。然而,我们在平均mAP上获得2.7%的绝对收益。CoLA采用硬片段挖掘策略,追求动作的完整性,进一步配备我们的FTCL,使WSAL更高效。评价ActivityNet1.3。如表2所示,我们的方法还在Activi- tyNet1.3数据集上实现了最先进的性能。具体来说,与目前最先进的ACM-Net[56]相比,我们获得了0.8%的相对增益。请注意这个数据集的性能改进不如THUMOS14数据集显著;原因可能是ActivityNet中的视频比THUMOS14中的视频短得多。ActivityNet平均每个视频只包含1.6个实例,而在THUMOS14中这个数字是15.6。显然,充足的时间信息可以促进细粒度的时间对比。
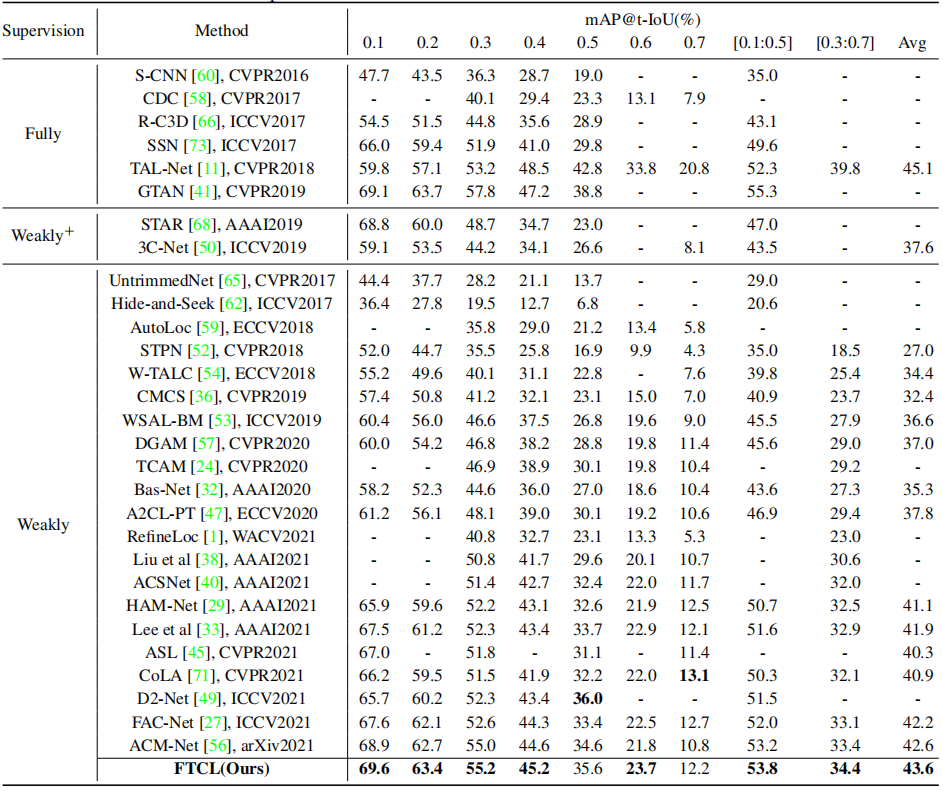
表1。时间动作定位性能与最先进的方法在THUMOS14数据集上的比较。请注意,弱+ 表示除了视频标签之外,利用外部监督信息的方法。
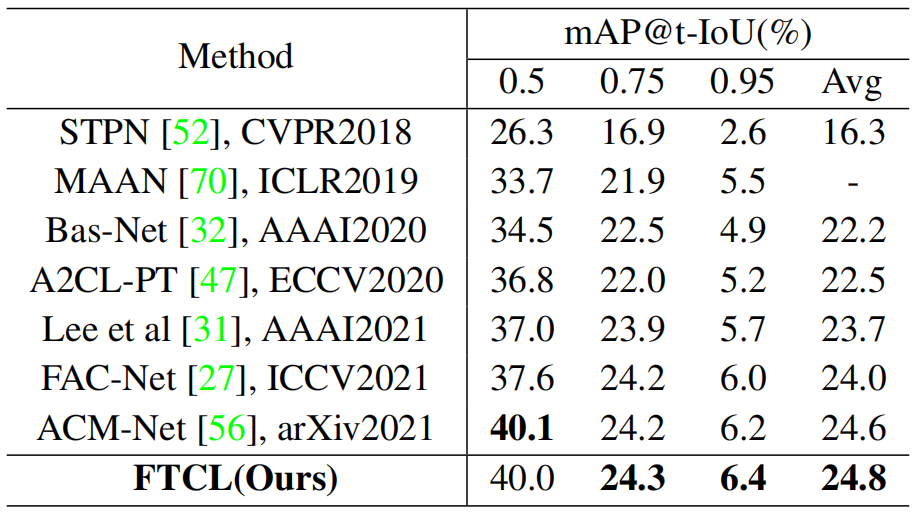
表2。在Activitynet1.3数据集上的比较结果。
4.3.进一步评论
为了更好地理解我们的算法,我们对THUMOS14数据集进行了消融和深入分析。
FSD对比效果。我们利用FSD对比来区分前景和背景。为了评估这种对比的有效性,我们将该模块(称为FTCL(w/o FSD))从整个模型中去掉,观察到性能显著下降,如表3所示。具体来说,我们的完整模型FTCL在t-IoU阈值[0.10,0.30,0.50,0.70]上的mAP相对收益(0.8%,1.7%,2.9%,6.1%)优于基线。如果没有FSD对比,就无法很好地处理精细的前景-背景区分,导致分类器学习不足。
LCS对比效果。我们还将LCS与完整模型(FTCL(w/o LCS))进行对比,以评估其对整体性能的贡献,相应的性能持续下降,如表3所示,证明了鲁棒分类对定位自适应的积极影响,从LCS中挖掘未裁剪的视频,可以使模型在动作实例中发现一致的片段,从而提高定位性能。
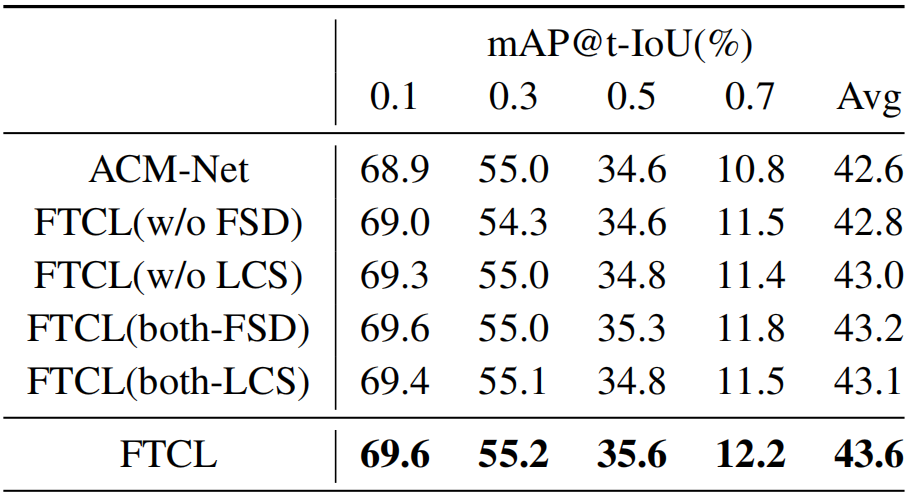
表3。在THUMOS14上消融模块有效性的研究。
以上两个模块是冗余的吗? FSD和LCS的目标都采用了顺序对比,但目标不同。精明的读者可能会好奇FSD和LCS学习策略是否冗余。是否可以采用FSD或LCS联合建模前景背景分离和分类定位适应?为了回答这个问题,我们进行了只对比FSD或LCS的实验,以解决分离和适应目标,即表3中的FTCL(both-FSD)和FTCL(both-LCS)。我们观察到,我们的完整模型优于这两个变量,证明了上述两个模块不是冗余的。另一个观察结果是,这两种变体的性能优于FTCL(w/o FSD))和FTCL(w/o LCS))。这是因为FSD和LCS都属于序列对序列的测量,仅能促进分离和适应目标。然而,由于这两个目标有其独特的性质,我们设计了FSD和LCS对比策略来解决它们,获得了最好的性能。
为什么不求助于其他动态编程策略,比如DTW? 我们观察到最近一些工作正在致力于基于动态时间规整(DTW)的视频序列对齐[7,14,25]。然而,DTW假设两个序列可以完全对齐,因此需要裁剪视频。为了验证我们的FTCL的有效性,如表4所示,我们将我们提出的方法与目前最先进的基于DTW的方法,Cycle- Consistency DTW(CC-DTW)[25]和Drop-DTW[14]进行了比较。结果显示了我们的框架的优越性。我们也将我们的FSD和LCS策略(Eq.(2)和Eq.(6))替换为标准差分DTW算子[25](记为DTW),其结果不如我们前面分析的那样。
提出的FTCL的补充作用。很明显,提出的策略是模型无关的和非侵入性的,因此可以在现有方法上发挥补充作用。在表5中,我们将FSD和LCS对比插入到STPN[52],W-TALC[54]和CoLA三种WSAL方法中[71]。结果表明我们提出的学习策略可以不断提高他们的成绩。此外,我们的方法在模型推理过程中不引入计算代价。值得注意的是,CoLA还采用了snippet级别的对比学习,而我们提出的方法可以通过额外考虑细粒度时间差异进一步提高其性能。
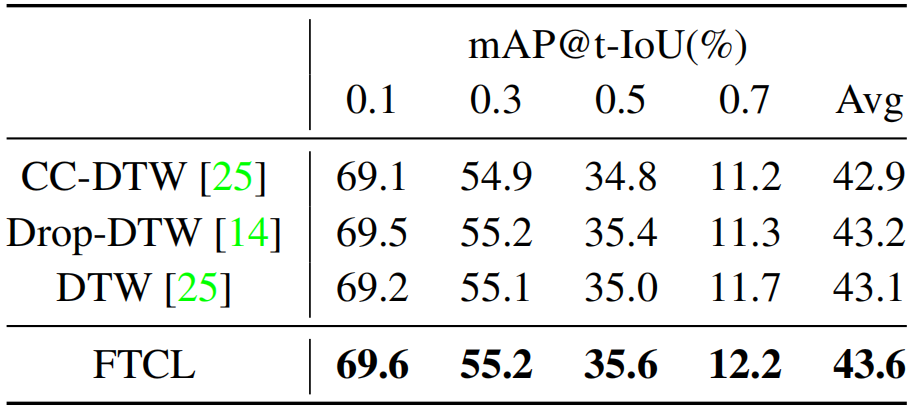
表4。与基于dtw的方法在THUMOS14上的比较。
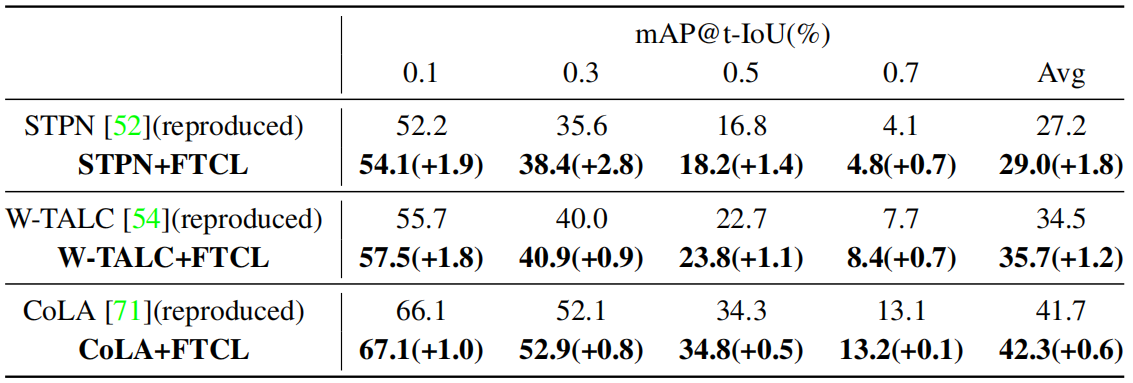
表5所示。评估FTCL的互补作用。
5.结论
本文提出了一种细粒度的时间对比学习框架,该框架具有区分动作背景分离的优点,同时也缓解了分类和定位之间的任务差距。具体而言,通过可导动态规划设计了FSD和LCS两种对比策略,能够进行细粒度的时间区分。大量实验证明了该方法的积极效果。
局限性。在这项工作中,与现有的WSAL模型类似,我们对所有视频都使用固定的片段划分策略。但是,由于不同的视频时长和镜头不同,简单固定的方式可能会阻碍细粒度的时间对比学习。在未来,我们计划采用自适应的方式进行FTCL,例如考虑时间结构的分层,或者在统一的框架下进行镜头检测和动作定位。
