
Two-Stream Consensus Network for Weakly-Supervised Temporal Action Localization
0. 前言
-
相关资料:
-
code
-
论文解读
-
论文基本信息:
-
领域:弱监督时序动作定位
-
发表时间:ECCV2020(2020.10.22)
摘要
弱监督时间动作定位(W-TAL)旨在仅在视频级监督下对未剪辑视频中的所有动作示例进行分类和定位。然而,在没有帧级注释的情况下,W-TAL方法很难识别假阳性的动作建议,并生成具有精确时间边界的动作建议。在本文中,我们提出了一个双流共识网络(TSCN)来同时应对这些挑战。提出的TSCN具有一种迭代细化训练方法,其中帧级伪ground-truth被迭代更新,并用于为改进的模型训练和误报动作建议消除提供帧级监督。此外,我们提出了一种新的注意力归一化损失,以鼓励预测的注意力权重接近二进制选择,并促进动作示例边界的精确定位。在THUMOS14和ActivityNet数据集上进行的实验表明,所提出的TSCN优于当前最先进的方法,甚至与一些最近的完全监督方法取得了相当的结果。
1介绍
弱监督时间动作定位(W-TAL)的任务是在学习阶段,仅给出视频级分类标签的情况下,对长时间未剪辑视频中的所有动作示例同时进行定位和分类。相比于在训练过程中需要对所有动作示例进行帧级标注的全监督对应,W-TAL大大简化了数据收集过程,避免了人工标注者的标注偏差,因此近年来得到了广泛的研究[18,41,34,27,30,1,23,46,24,28,26,43,20] 。
几种W-TAL方法[41,30,27,23,28,26,20]采用多示例学习(MIL)框架,将视频视为一包帧/片段以执行视频级动作分类。在测试过程中,经过训练的模型会随时间滑动,并生成一个时间类激活图(T-CAM)[49,27](即每个时间步上动作类的概率分布序列)和衡量每个片段相对重要性的注意力序列。动作建议是通过设置注意力值和/或T-CAM的阈值来生成的。MIL框架通常基于两种特征模式,即RGB帧和光流,它们以两种可能的方式融合。early fusion方法[30,34,1,23,24,20]在将RGB和光流特征输入网络之前,将它们连接起来,并采用late fusion方法[27,23,28,26]在生成动作建议之前,计算各自输出的加权和。图1显示了late fusion的一个例子。
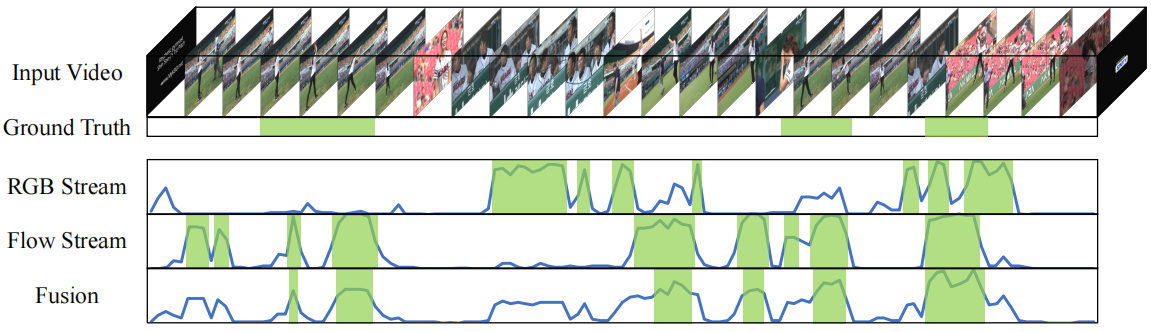
图1:双流输出及其late fusion结果的可视化。前两行分别是输入视频和ground-truth动作示例。最后三行分别是由RGB流,光流及其加权和(即融合结果)预测的注意力序列(从0到1缩放),水平轴和垂直轴分别表示注意力值的时间和强度。绿色框表示将注意力阈值设置为0.5时产生的定位结果。通过将RGB和flow streams预测的两种不同的注意力分布进行适当组合,late fusion结果获得了更高的真阳性率和更低的假阳性率,从而具有更好的定位性能
尽管最近有了这些发展,但两大挑战仍然存在。之前的W-TAL方法所面临的最关键的问题之一是缺乏排除假阳性动作建议的能力。如果没有帧级注释,它们会定位不一定与视频级标签对应的动作示例。例如,模型可能仅通过检查场景中是否存在水来错误定位动作“游泳”。因此,有必要利用更细粒度的监督来指导学习过程。另一个问题在于动作建议的制定。在以前的方法中,动作建议是通过使用一个固定的阈值对激活序列进行阈值化来生成的,该阈值是根据经验预设的。它对动作建议的质量有重大影响:高阈值可能会导致动作建议不完整,而低阈值可能会带来更多误报。但如何走出这一困境却鲜有研究。
在本文中,我们引入了一个双流共识网络(TSCN)来解决上述两个问题。为了消除假阳性行为建议,我们设计了一种迭代细化训练方案,其中从late fusion注意力序列生成一个帧级伪ground-truth,并作为更精确的帧级监督来迭代更新双流模型。我们的直觉很简单:late fusion本质上是RGB和光流的投票集合,如果选择合适的融合参数(即控制双流的相对重要性的超参数),late fusion可以提供比每个光流更准确的结果。结合双流的优势已通过用于动作识别的双流卷积网络[37]得到证明。如图所示。1, 双流产生不同的激活分布,从而导致不同的假阳性和假阴性。然而,当它们结合在一起时,仅存在于一个光流中的假阳性动作建议可以在很大程度上被消除,并且只有当双流都确信存在一个动作示例时,才会出现高激活值。由于late fusion结果的质量高于单光流结果,因此它可以作为帧级伪ground-truth来监督和细化双流。为了产生高质量的动作建议,我们引入了一种新的注意力归一化方法。它将预测的注意力推向极值,即0和1,以避免歧义。因此,只要将阈值设置为0.5,就可以产生高质量的动作建议。
形式上,给定一个输入视频,首先从预训练好的深度网络中提取RGB和光流特征。然后分别利用RGB和光流特征对双流base模型进行训练,其中注意力归一化损失用于学习注意力分布。在获得双流注意力序列后,基于它们的加权和(即late fusion注意力序列)生成帧级伪ground-truth,并反过来提供帧级监督以改进双流模型。我们迭代地更新伪ground-truth并细化双流base模型,同时归一化项迫使预测的注意力接近二元选择。最后对融合后的注意力序列进行阈值化,得到最终的定位结果。
总而言之,我们的贡献有三个方面:
–我们为W-TAL引入了双流共识网络(TSCN)。所提出的TSCN使用迭代细化训练方法,其中由前一迭代中的late fusion注意力序列生成的伪ground-truth可以为当前迭代提供更精确的帧级监督。
–我们提出了一个注意力归一化损失函数,它迫使注意力像二进制选择一样,从而提高了阈值方法生成的动作建议的质量。
–在两个标准基准(即THUMOS14和ActivityNet)上进行了大量实验,以证明所提出方法的有效性。我们的TSCN显著优于之前最先进的W-TAL方法,甚至与最近一些完全监督的TAL方法取得了相当的结果。
2相关工作
动作识别。传统方法[19,7,8,39]目的通过手工制作的特征对时空信息进行建模。双流卷积网络[37]使用两个独立的卷积神经网络(CNN)分别利用RGB帧和光流的外观和运动线索,并使用late fusion方法协调双流输出。[10]重点研究融合这两条光流的不同方法。Inflated 3D ConvNet(I3D)[3]将双流网络中的二维CNN扩展为三维CNN。最近的几种方法[47,5,35,40,31]专注于从RGB帧直接学习运动线索,而不是计算光流。
完全监督的时间动作定位。完全监督的TAL需要在训练期间对所有动作示例进行帧级注释。已经为这项任务创建了几个大型数据集,例如THUMOS[15,13],ActivityNet[2],还有Charades[36]。很多方法[33,48,12,14,6,42,22,4]采用两阶段流程,即生成动作建议,然后进行动作分类。几种方法[42,6,11,4]采用更快的R-CNN[32]框架到TAL。最近,一些方法[22,25,21]尝试制定更灵活的动作计划。曾等[45]应用图卷积网络(GCN)[17,38]到TAL以利用提案-提案关系。
弱监督的时间动作定位。W-TAL在训练期间只需要视频级别的监督,极大地减轻了数据注释工作,近年来越来越受到社区的关注。Hide-and-Seek[18]随机隐藏部分输入视频,以引导网络发现其他相关部分。UntrimmedNet[41]包括一个用于选择重要代码段的选择模块和一个用于按代码段进行分类的分类模块。稀疏时态池网络(STPN)[27]通过添加稀疏损失来增强选定线段的稀疏性,从而改进了UntrimmedNet。W-TALC[30]联合优化协同活动相似性损失和多示例学习损失,以训练网络。AutoLoc[34]是W-TAL中最早的两阶段方法之一,它首先生成初始动作建议,然后使用外部-内部对比损失回归动作建议的边界。CleanNet[24]通过利用片段级动作分类预测中的时间对比度来改进AutoLoc。刘等人[23]提出一个多分支网络来模拟不同的动作阶段。此外,还有几种方法[28,20]专注于背景建模,实现最先进的表演。
最近,RefineLoc[1]使用迭代优化方法帮助模型捕获完整的动作示例。我们的方法在三个主要方面与RefineLoc不同。(1) 我们采用了late fusion框架,而RefineLoc采用了early fusion框架。(2) 我们的伪ground-truth是由双流的late fusion注意力序列生成的,这比每个流提供更好的定位性能,而RefineLoc通过扩展以前的定位结果生成伪ground-truth,这可能会导致更粗糙和更完整的动作建议。(3) 我们引入了一个新的注意力归一化损失可以明确避免注意力的模糊性,而RefineLoc对注意力值没有明确的限制。
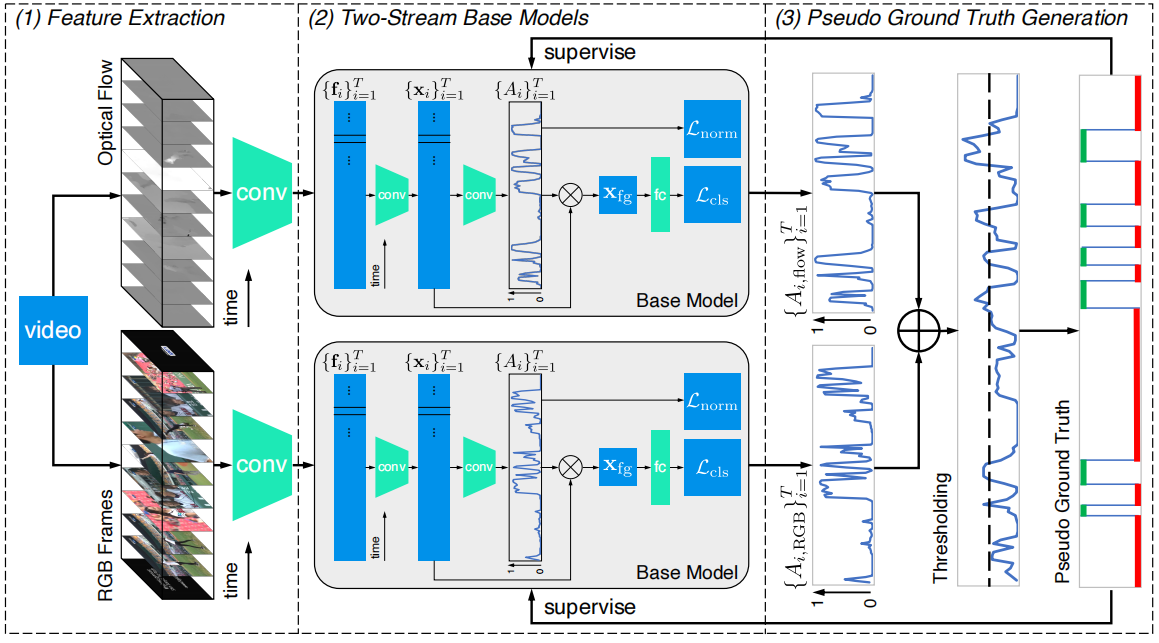
图2:提出的双流一致性网络的概述,包括三个部分:(1)使用预训练的模型提取RGB和光流片段级特征;(2) 使用这些RGB和光流特征分别训练双流base模型;(3) 帧级伪ground-truth由双流的late fusion注意力序列生成,并反过来为双流base模型提供帧级监督
3双流共识网络
在这一部分中,我们首先阐述了弱监督时间动作定位(W-TAL)的任务,然后详细描述了所提出的双流一致性网络(TSCN)。整体架构如图2所示。
3.1问题表述
假设我们得到了一组训练视频。对于每个视频v,我们只有它的视频级分类标签y,其中y∈RC是一个归一化的multi-hot向量,C是动作类别的数量。时间动作定位的目标是为每个测试视频生成一组动作建议{(ts,te,c,ψ)},其中ts,te,c,ψ分别表示动作建议的开始时间,结束时间,预测的动作类别和置信度得分。
3.2特征提取
遵循最近的W-TAL方法[34,27,30,23,24,28,26,43,20],我们根据从原始视频中提取的片段级特征序列构建TSCN,利用预训练好的深度网络(如I3D[3])分别从非重叠的固定长度RGB帧片段和光流片段中提取RGB和光流特征。它们提供了相应代码片段的高级外观和运动信息。形式上,给定一个分为T个非重叠片段的视频,我们表示RGB特征和光流特征为{fRGB,i}Ti=1和{fflow,i}Ti=1,分别,其中fRGB,i,fflow,i∈RD分别是第i个RGB帧和光流片段的特征表示,D表示通道维度。
3.3双流base模型
在获得RGB和光流特征后,我们首先使用双流base模型来执行视频级动作分类,然后使用帧级伪ground-truth迭代地细化base模型。两种模式的特征分别输入到两个独立的base模型中,两个base模型使用相同的体系结构,但不共享参数。因此,在本小节中,为了简洁起见,我们省略了下标RGB和flow。
由于这些特征最初不是针对W-TAL任务进行训练的,我们连接T个输入特征{fi}Ti=1,并使用一组时间卷积层生成一组新特征{xi}}Ti=1,其中,xi∈RD',D'表示输出特征维度。
由于视频可能包含背景片段,为了执行视频级的分类,我们需要选择可能包含动作实例的片段,同时过滤掉可能包含背景的片段。为此,一个注意力值Ai∈(0,1)来测量第i个片段包含一个动作的可能性,Ai由一个全连接(FC)层给出:

其中,σ(·),wA和bA分别为注意力层的sigmoid函数,权重向量和偏差。然后,我们对特征序列进行注意力加权池化,生成单个前景特征xfg,并将其输入FC softmax层,得到视频级预测: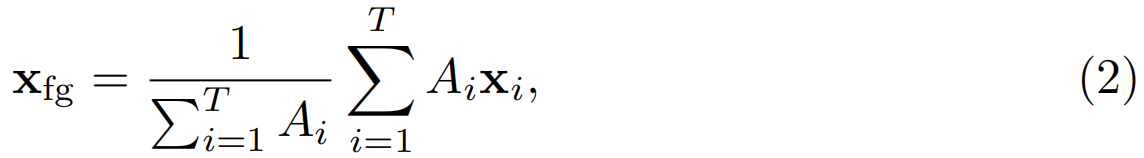

其中,![]() 是视频中包含第c个动作的概率,wc和bc是类别c的FC层的权重和偏差。分类损失函数Lcls被定义为标准的交叉熵损失:
是视频中包含第c个动作的概率,wc和bc是类别c的FC层的权重和偏差。分类损失函数Lcls被定义为标准的交叉熵损失:
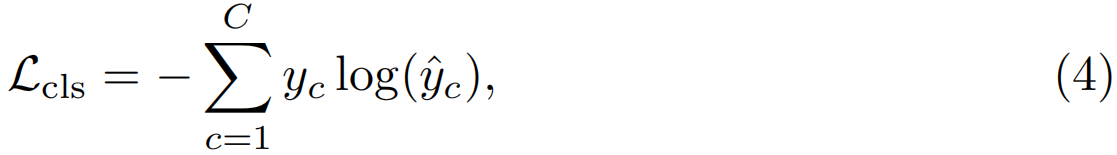
其中,yc表示在索引c处的标签向量y的值。
理想情况下,注意力值应为二进制,其中1表示存在动作,0表示背景。最近,有几种方法[28,20]引入背景类别,并使用背景分类来指导注意力的学习。在这项工作中,我们没有使用背景分类,而是引入了一个注意力归一化项来强制注意力接近极值:
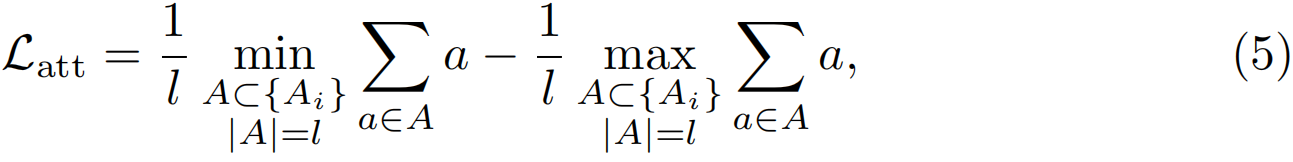
其中l=max(1,![]() )和s是一个超参数,用于控制所选代码段。这种归一化损失的目的是最大化top-l平均注意力值和bottom-l平均注意力值之间的差异,并强制前景注意力为1,背景注意力为0。
)和s是一个超参数,用于控制所选代码段。这种归一化损失的目的是最大化top-l平均注意力值和bottom-l平均注意力值之间的差异,并强制前景注意力为1,背景注意力为0。
因此,base模型训练的总体损失是分类损失和注意力归一化项的加权和:

其中α是一个超参数,用于控制归一化损失的权重。
此外,时间类激活映射(T-CAM){si}Ti=1,si∈RC也可以通过在所有片段上滑动分类FCsoftmax层来生成:
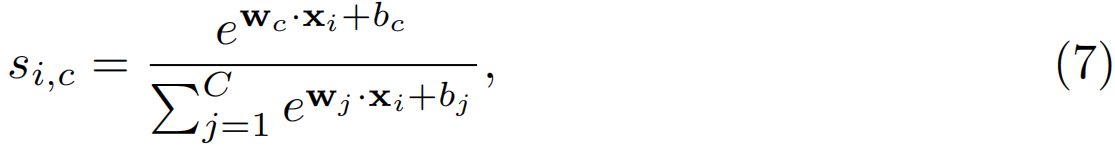
其中,si,c是类别c的第i个片段的T-CAM值。
3.4伪ground-truth生成
我们用一个帧级伪ground-truth对双流base模型进行迭代优化。具体来说,我们将整个训练过程划分为几个迭代。在迭代0中,只有视频级别的标签用于训练。在迭代n+1时,在迭代n处生成帧级伪ground-truth,并为当前迭代提供帧级监督。然而,如果没有真实的ground-truth注释,我们既不能测量伪ground-truth的质量,也不能保证伪ground-truth可以帮助base模型实现更高的性能。
受双流late fusion的启发,我们介绍了一种简单而有效的生成伪ground-truth的方法。直觉上,两种流都具有高激活率的位置可能包含ground-truth动作示例;只有一个流具有高激活率的位置可能是只有一个流可以检测到的假阳性动作建议或真实动作示例;两种流的激活率都较低的位置可能是背景。
根据这一直觉,我们在细化迭代n中使用融合注意力序列{A(n)fuse,i}Ti=1来为化迭代n+1生成伪ground truth真实值{G(n+1)i}Ti=1,其中A(n)fuse,i=βA(n)RGB,i+(1−β)A(n)flow,i,β∈[0,1]是一个超参数来控制RGB和光流注意力的相对重要性。我们介绍了两种伪ground-truth生成方法。
软伪ground-truth意味着直接使用融合注意力值作为伪标签:Gi(n+1)=A(n)fuse,i。软伪标签包含了一个片段是前景动作的概率,但也增加了模型的不确定性。
硬伪ground-truth在注意力序列上施加阈值以生成一个二进制序列:
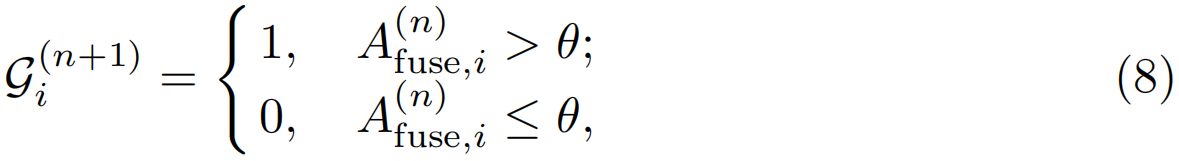
其中θ是阈值。设置较大的θ值将消除只有一个光流具有高激活率的操作建议,从而降低误报率。相比之下,将θ设置为一个较小的值将有助于模型生成更多的动作建议,并实现更高的召回率。硬伪标签消除了不确定性,提供了更强的监督,但引入了超参数。
在生成帧级伪ground-truth后,我们强制每个光流生成的注意力序列与伪ground-truth相似,并具有均方误差(MSE)损失(虽然直接使用交叉熵损失计算硬伪ground-truth很简单,但我们在实践中发现,交叉熵损失和均方误差损失达到了类似的性能。为了简化训练,我们对这两种伪ground-truth都使用了均方误差损失。
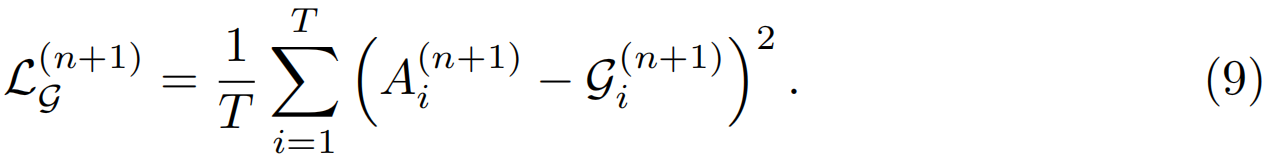
在细化迭代n+1时,每个光流的总损失为
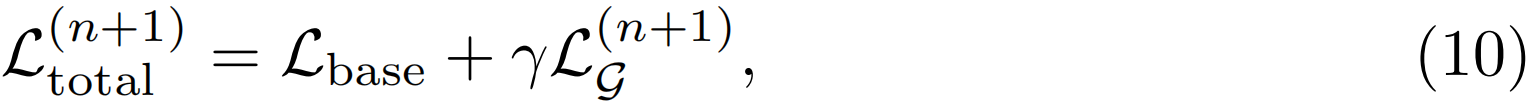
其中γ是一个超参数,用于控制两个损失的相对重要性。
3.5动作定位
在测试过程中,遵循BaS-Net[20],首先,我们通过线性插值将注意力序列和T-CAM的采样时间增加了8倍。然后,我们从融合视频级预测![]() 中选择top-k动作类别进动作作定位,其中
中选择top-k动作类别进动作作定位,其中![]() =β
=β![]() +(1-β)
+(1-β)![]() 。对于这些类别中的每一个,根据我们的注意力执行二进制选择的想法,通过直接将注意力值设置为0.5并连接连续的片段来生成行动建议。行动建议是通过外部-内部-约束得分[34]的一个变体来评分的:我们不是使用平均T-CAM,而是使用注意力加权T-CAM来测量外部和内部时间对比。形式上,给定行动建议(ts,te,c),融合注意力{A(n)fuse,i}Ti=1和T-CAM{sfuse,i},其中,sfuse,i=βsRGB+(1−β)sflow,i,分数ψ计算为
。对于这些类别中的每一个,根据我们的注意力执行二进制选择的想法,通过直接将注意力值设置为0.5并连接连续的片段来生成行动建议。行动建议是通过外部-内部-约束得分[34]的一个变体来评分的:我们不是使用平均T-CAM,而是使用注意力加权T-CAM来测量外部和内部时间对比。形式上,给定行动建议(ts,te,c),融合注意力{A(n)fuse,i}Ti=1和T-CAM{sfuse,i},其中,sfuse,i=βsRGB+(1−β)sflow,i,分数ψ计算为
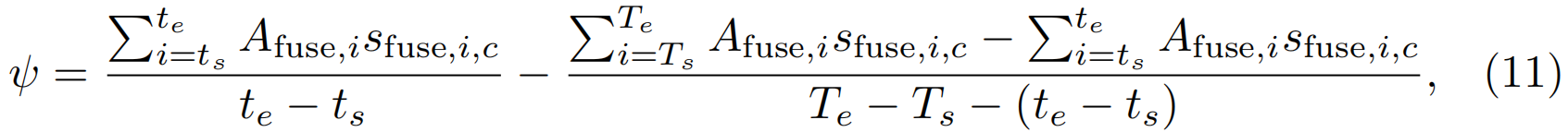
其中包括Ts = ts-L/4,Te = te+L/4和L=te-ts。我们放弃了置信度分数低于0的行动建议。
4实验
4.2实施细节
在我们的实验中使用了两个现成的特征提取主干,即UntrimmedNet[41]还有I3D[3],片段长度分别为15帧和16帧。这两个backbone在ImageNet[9]和Kinetics[3]上接受了预训练,并没有进行微调以进行公平比较。RGB和光流片段级特征在全局池层提取为1024维向量。
这些网络是在PyTorch中实现的[29].我们用Adam[16]具有固定学习率0.0001的优化器。我们在细化迭代0时分别对base模型进行200和80个epochs的训练,并分别对ActivityNet和THUMOS14的后续细化迭代进行100和40个epochs的训练。对于THUMOS14数据集,我们将优化迭代的最大次数设置为4次,对于ActivityNet数据集为24次,并选择在前一次细化迭代中损失最低的base模型来生成伪ground-truth。为了消除碎片动作建议,在actitynet数据集上生成伪ground-truth之前,对融合注意力序列使用核大小5和步幅1的时间最大池化。我们使用了整个视频作为一个batch。所有的超参数都是通过网格搜索来确定的:s=8,α=0.1,β=0.4,γ=2。我们将THUMOS14和激活网络的θ分别设置为0.55和0.5。我们选择排名前2的动作类别,并拒绝融合分类预测得分低于0.1的类别进行动作定位。
4.4消融研究
在本小节中,使用ntrimmedNet特征在THUMOS14测试集上进行了一系列消融研究,以分析TSCN中各成分的功效。
Latt的消融实验。式(5)中Latt的目标是迫使注意力值接近极值,从而生成一个干净的前景特征xfg,提高行动建议的质量。最近的一些方法[28,20]将背景分类引入了W-TAL。特别是引入背景分类损失Lbg[28]对背景进行分类,将背景注意力定义为1−Ai,通过对所有片段的背景注意力加权池生成背景特征来进行背景分类。因此,Lbg本质上是一种隐注意力归一化损失。然而,这种背景损失的一个缺点是,为所有视频分配背景标签会使T-CAM中背景类别的值增加。我们在我们的模型中重现了Lbg,并将其与我们提出的Latt进行了比较,然后在表4中列出了结果。结果表明,Lbg和Latt都有助于提高性能。与Latt相比,Lbg具有更高的注意力方差和更好的定位性能,说明我们的注意力归一化项Latt可以更好地避免注意力的模糊性。令人惊讶的是,Lbg和Latt的定位性能仍然低于只有Latt,我们认为这是因为背景分类的噪声降低了行动建议得分的准确性。
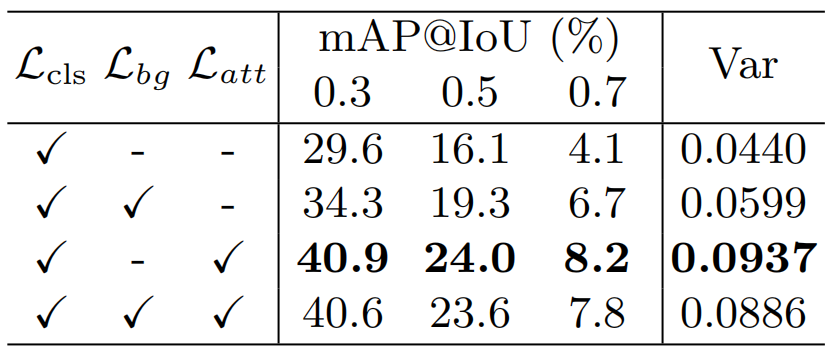
表4:我们的方法在THUMOS14测试集上与不同的注意力归一化函数的比较。Lbg是[28]中引入的背景分类损失,Latt的定义见式(5)。var列表示在整个测试集上的平均注意力方差
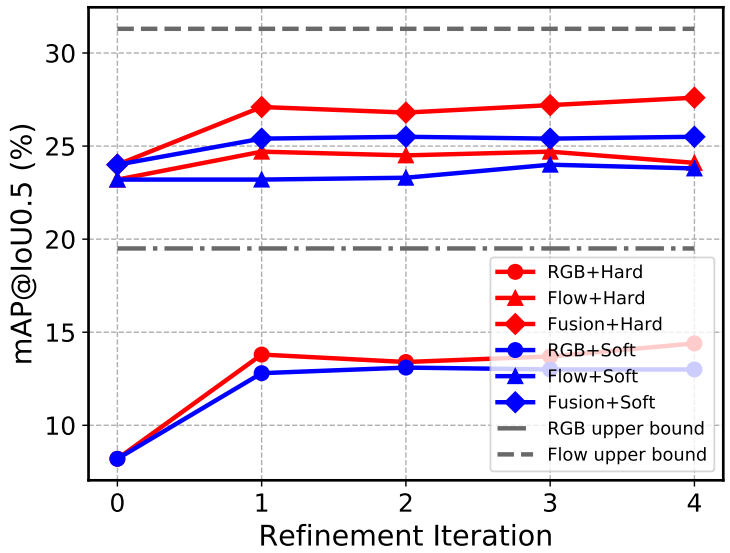
图3:在THUMOS14测试集上使用不同伪ground-truth训练的模型之间的比较。上界表示用ground-truth动作序列训练的模型
伪ground-truth的消融实验。图3绘制不同伪ground-truth方法在不同细化迭代中的性能比较。软伪ground truth和硬伪ground truth都有助于提高定位性能。硬伪ground-truth消除了模型的不确定性,从而实现了更高的性能改进。然而,在相同的帧级监督下,光流的性能大大优于RGB流。我们认为这是因为两种模式的性质:RGB模式对动作的敏感度低于光流模式。为了证明这一点,我们生成了一个真实的帧级ground-truth动作序列(不使用动作类别),并以与伪ground-truth相同的方式训练我们的模型。结果如图3中upper bound所示。结果验证了我们的假设,并证明光流模式比RGB模式更适合动作定位任务。
表5列出了仅使用视频级别标签训练的模型与使用硬伪ground-truth训练的模型之间的详细性能比较。结果表明,伪ground-truth提高了两种模式在所有IoU阈值下的定位性能,从而提高了融合结果的性能。此外,伪ground-truth极大地提高了RGB流和融合结果的精度和召回率,并在召回率损失较小的情况下提高了光流的精度(总体F度量显著提高),这表明伪ground-truth可以帮助消除假阳性动作建议。
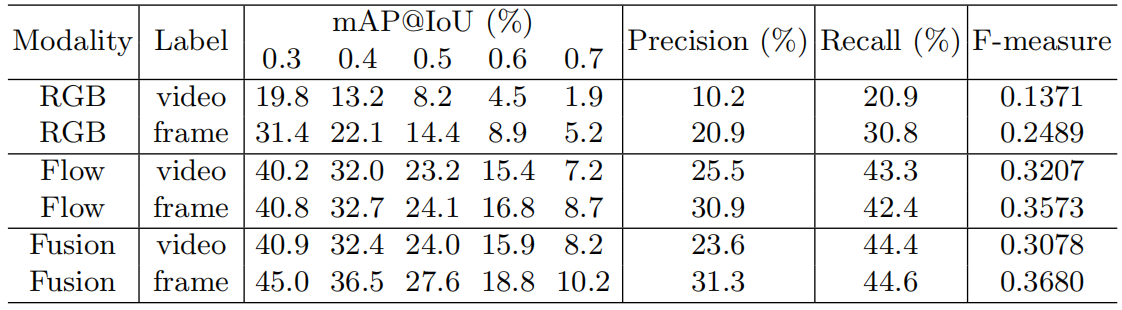
表5:在THUMOS14测试集上,仅使用视频级别标签训练的模型与使用硬伪ground-truth训练的模型之间的比较。标签列表示训练中使用的监督,其中“视频”表示仅使用视频级别的标签,“帧”表示在训练期间也使用硬伪ground truth事实。在IoU阈值0.5下计算精度,召回率和F测量值
定性分析。TAL结果的三个代表性示例如图4所示。以说明所提出的伪监督的有效性。在跳水和悬崖跳水的第一个示例中,仅使用视频级别标签,RGB流提供比光流光流更差的定位结果,从而导致噪声融合注意力序列。伪ground-truth引导RGB流识别假阳性动作建议和发现真实动作示例,并进一步导致更清晰的融合注意力序列,其中高激活度更符合ground-truth。在板球镜头的第二个示例中,只有视频级别的监督,RGB流只能区分某些场景,无法分离接近的动作示例。相反,光流可以精确地检测动作示例。因此,伪ground-truth有助于RGB流分离连续动作示例。在足球处罚的最后一个例子中,双流在某些假阳性时间位置上都有较高的激活率。在这种情况下,在帧级伪监督下,误报动作建议将具有更高的激活率。然而,为了消除这种虚假的积极动作建议,需要真正的ground-truth监督。总而言之,这两种模式有各自的优点和局限性:RGB流对外观敏感,因此在从不寻常的角度拍摄的场景中或在同一场景中分离接近的动作示例时失败;光流对运动敏感,并提供更准确的结果,但在缓慢或闭塞运动中失败。定性结果表明,伪ground-truth有助于双流在大多数时间位置达成共识。因此,融合注意力序列变得更清晰,有助于生成更精确的动作建议和更可靠的置信度分数。
5结论
在本文中,我们提出了一种适用于W-TAL的双流一致性网络(TSCN),它得益于迭代细化训练方法和新的关注点

图4:THUMOS14测试集的定性结果。每个示例中的八行分别是来自仅使用视频级标签和帧级伪ground-truth训练的模型的输入视频,ground-truth动作示例,RGB流,光流和融合注意力序列。动作建议用绿色方框表示。水平轴和垂直轴分别是注意力的时间和强度
归一化损失。迭代求精训练使用一种新的帧级伪ground-truth作为细粒度监督,并迭代地改进双流base模型。注意力归一化损失函数减少了注意力值的模糊性,从而导致更精确的动作建议。在两个基准上的实验表明,所提出的TSCN优于目前最先进的方法,并验证了我们的设计直觉。
