SF-Net:Single-Frame Supervision for Temporal Action Localization
0. 前言
摘要
在本文中,我们研究了一种用于时间动作定位(TAL)的中间监督形式,即单帧监督。为了获得单帧监督,标注者被要求在动作的时间窗口内仅识别单个帧。这可以显著降低获得全面监督的人工成本,这需要标注动作边界。与只标注视频级别标签的弱监督相比,单帧监督在保持较低标注开销的同时引入了额外的时间动作信号。为了充分利用这种单帧监督,我们提出了一种称为SF-Net的统一系统。首先,我们建议预测每个视频帧的动作评分。除了一个典型的类别分数,动作识别分数可以提供关于潜在动作发生的全面信息,并有助于推理过程中时间边界的细化。其次,我们基于单帧标注挖掘伪动作帧和背景帧。我们通过自适应地将每个带标注的单帧扩展到其附近的上下文帧来识别伪动作帧,并从多个视频中的所有未标注帧中挖掘伪背景帧。与ground-truth标记帧一起,这些伪标记帧被进一步用于训练分类器。在THUMOS14、GTEA和BEOID上进行的大量实验中,SF-Net在分段定位和单帧定位方面显著改进了最先进的弱监督方法。值得注意的是,SF-Net的结果与完全监督的结果相当,后者需要更多的资源密集型标注。该代码在https://github.com/Flowerfan/SF-Net.
1 导言
近年来,弱监督时间动作定位(TAL)引起了人们极大的兴趣。给定一个只包含视频级别标签的训练集,我们的目标是在长时间、未经剪辑的测试视频中检测和分类每个动作实例。在全监督标注中,标注者通常需要回滚重复观看视频,当他们在观看视频时注意到某个动作时,给出动作实例的精确时间边界[41]。对于弱监督标注,标注者只需观看一次视频即可给出标签。一旦他们注意到一个未见过的动作,他们就可以记录动作类。这显著减少了标注资源:视频级别标签使用的资源少于在完全监督的设置中标注开始和结束时间。
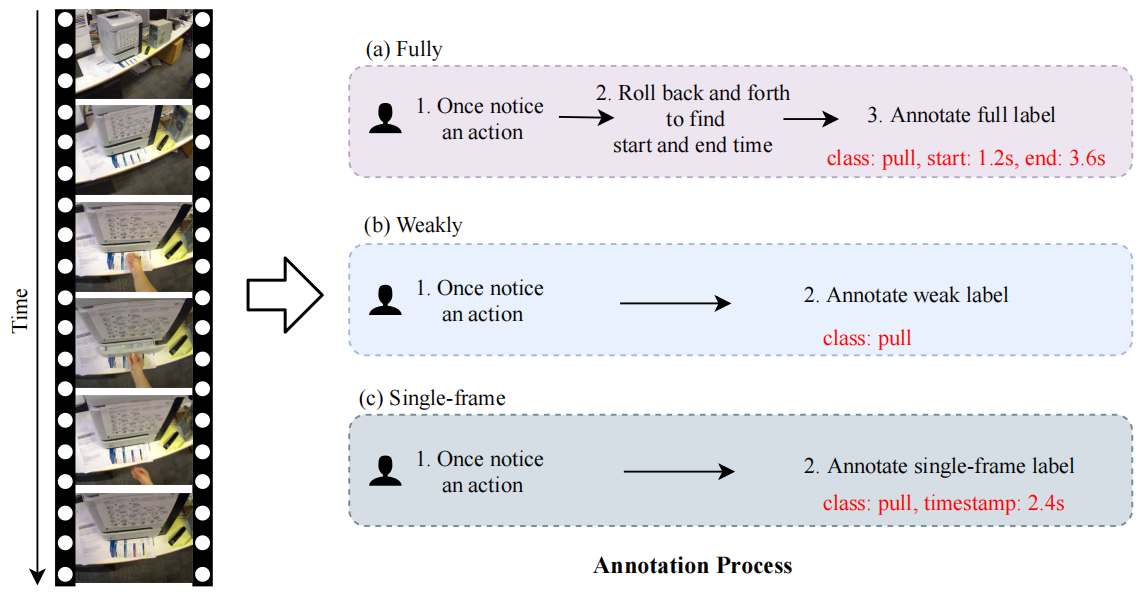
图1。观看视频时标注动作的不同方式。(a) 以完全监督的方式标注动作。每个动作实例的开始和结束时间都需要标注。(b) 在弱监督设置中标注操作。只需要提供动作类。(c) 在单帧监督中标注操作。每个操作实例都应该有一个时间戳。请注意,时间是由标注工具自动生成的。与弱监督标注相比,单帧标注只需要几个额外的暂停就可以对一个视频中重复出现的动作进行标注。
尽管最先进的弱监督TAL工作[25,27,29]取得了令人鼓舞的成果,但它们的定位性能仍然不如完全监督的TAL工作[6,18,28]。为了弥合这一差距,我们积极利用单帧监督[23]:对于每个动作实例,只指出一个阳性帧。单帧监督的标注过程与弱监督标注中的标注过程几乎相同。标注者在注意到每个动作时,只会观看一次视频,以记录动作类和时间戳。与全面监督相比,它显著减少了标注资源。
在图像领域,Bearman等人[2]率先提出了用于图像语义分割的点监督。Mettes等人[22]将点级标注扩展到了时空定位的视频领域,其中每个动作帧在训练期间都需要一个空间点标注。Moltisanti等人[23]通过提出单帧监督,进一步减少了所需资源,并开发了一种方法,选择置信度非常高的帧作为伪动作帧。
然而,[23]是为整个视频分类而设计的。为了在我们的TAL任务中充分利用单帧监督,定位动作时间边界的独特挑战仍未解决。为了应对TAL的这一挑战,我们进行了三项创新,以提高定位模型区分背景帧和动作帧的能力。首先,我们预测每一帧的“动作识别”,这表明任何动作的可能性。其次,基于动作识别,我们研究了一种新的背景挖掘算法来确定可能是背景的帧,并利用这些伪背景帧作为额外的监督。第三,在标记伪动作帧时,除了具有高置信度的帧外,我们的目标是确定更多的伪动作帧,从而提出一种动作帧扩展算法。
此外,对于许多现实世界的应用程序,检测精确的开始时间和结束时间是过分的。考虑一位记者想在街头摄影机的档案中找到一些车祸镜头:为每一次事故检索一个帧就足够了,并且记者可以很容易地截取到期望长度的剪辑。因此,除了评估TAL中传统的片段定位外,我们还提出了一个称为单帧定位的新任务,该任务只需要在每个动作实例中定位一帧。
总之,我们的贡献有三个方面:
(1) 据我们所知,这是第一次使用单帧监督来解决动作时间边界定位的挑战性问题。我们发现,与完全监督标注相比,单帧标注显著节省了标注时间。
(2) 我们发现,单帧监督可以提供关于背景的强大线索。因此,从未标注的帧中,我们分别提出了两种新的方法来挖掘可能的背景帧和动作帧。这些可能的背景和动作时间戳被进一步用作训练的伪ground-truth。
(3) 我们在三个基准上进行了大量实验,在分段定位和单帧定位任务上的性能都得到了很大提高。
2.相关工作
动作识别。动作识别最近见证了对剪辑视频的日益关注。时间和空间信息对于视频分类都很重要。早期作品主要使用手工制作的功能来解决这一任务。IDT[34]已广泛应用于许多与视频相关的任务中。近年来,各种深度神经网络被提出用于时空视频信息的编码。双流网络[31]采用光流来学习时间运动,这在后来的许多作品[4,31,36]中都有使用。许多3D卷积网络[4,33,11]也被设计用于学习动作嵌入。
除了完全监督的动作识别外,还有一些工作专注于自我监督的视频特征学习[43]和少量镜头动作识别[44]。在本文中,我们重点研究了单帧监督的时间动作定位。
点监督。Bearman等人[2]首先将点监督用于图像语义分割。Mettes等人[22]将其扩展到视频中的时空定位,在视频中,动作由每个动作帧中的一个空间位置指出。我们认为这对于时间定位来说是过分的,并且证明了单帧监督已经可以实现非常有希望的结果。最近,在[23]中,单帧监督被用于视频级别分类,但这项工作并没有解决识别时间边界的问题。请注意,Alwassel等人[1]提出在推理期间发现视频中的动作,但目标是在一个视频中检测每个类的一个动作实例,而我们提出的单帧定位任务旨在检测一个视频中的每个实例。
完全监督的时间动作定位。在全监督下训练的时间动作定位方法主要遵循提议分类范式[6,8,12,18,30,28],即先生成时间提议,然后进行分类。还研究了其他类型的方法,包括顺序决策[1]和单次探测器[17]。在给定完整的时间边界标注的情况下,提案分类方法通常在提案阶段通过二元动作分类器过滤掉背景帧。在时间动作定位任务中也研究了活动完整性。Zhao等人[42]使用结构时间金字塔池化和显式二进制分类器来评估动作实例的完整性。袁等人[38]将一个动作分为三个部分来模拟其时间演化。Cheron等人[7]通过各种监督处理时空动作定位。Long等人[21]提出了一种高斯核来动态优化动作建议的时间尺度。然而,这些方法完全使用时态标注,这是资源密集型的。
弱监督的时间动作定位。多实例学习(MIL)在弱监督时间动作定位中得到了广泛的应用。在没有时间边界标注的情况下,时间动作评分序列被广泛用于生成动作建议[35,25,19,24]。Wang等人[35]提出了由分类模块和选择模块组成的UntrimmedNet,以推断动作实例的时间持续时间。Nguyen等人[25]提出了一种用于视频级别分类的稀疏正则化方法。Shou等人[29]和Liu[20]研究了时间维度上的分数对比。Hideand Seek[32]在训练期间随机删除帧序列,以迫使网络响应多个相关部分。Liu等人[19]提出了一个多分支网络来模拟动作的完整性。Narayan等人[24]介绍了三种损失形式,以指导学习具有增强定位能力的辨别性动作特征。Nguyen[26]使用注意模块来检测前景和背景,以检测动作。尽管随着时间的推移有所改进,但弱监督方法的性能仍然不如完全监督方法。
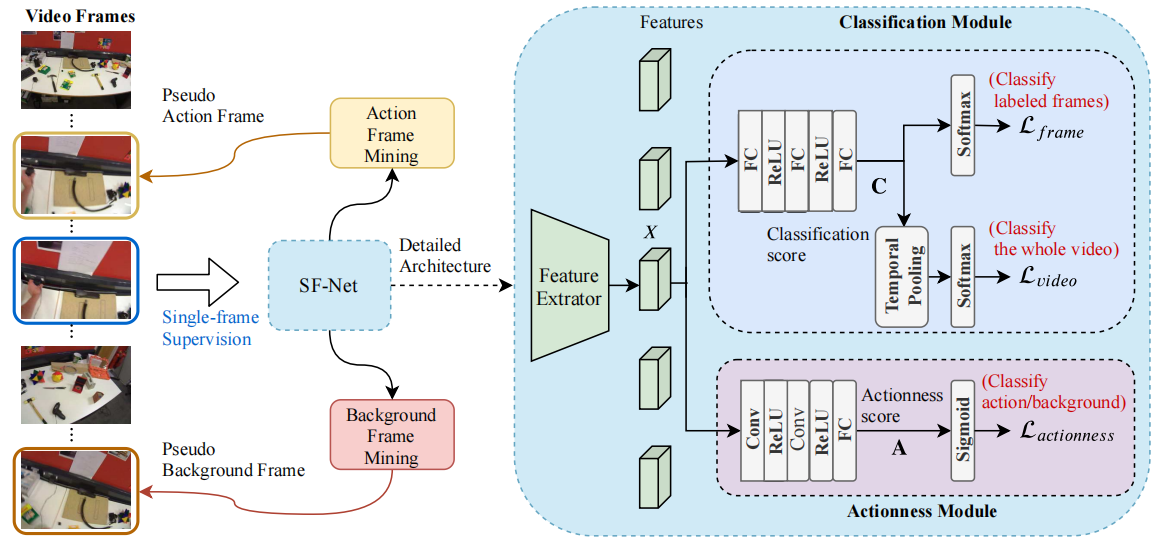
图2。我们提出的SF-Net的整体训练框架。在单帧监督的情况下,我们采用了两种新的帧挖掘策略来标记伪动作帧和背景帧。SF-Net的详细架构如右图所示。SF-Net由一个分类模块和一个动作识别模块组成,前者用于对每个标记帧和整个视频进行分类,后者用于预测每个帧是动作的概率。分类模块和动作识别模块是联合训练的,第3.3节解释了三种损失。
3.方法
在本节中,我们定义了我们的任务,介绍了我们的SF-Net的体系结构,最后分别讨论了训练和推理的细节。
3.1问题定义
训练视频可以包含多个动作类和多个动作实例。与提供每个动作实例的时间边界标注的完全监督设置不同,在我们的单帧监督设置中,每个实例只有一个由标注器指出的帧,带有时间戳t和动作类y∈{1,…,Nc},其中Nc是类的总数,我们使用索引0来表示背景类。
给定一个测试视频,我们执行两个时间定位任务:(1)分段定位。我们通过动作类预测来检测每个动作实例的开始时间和结束时间。(2) 单帧定位。我们输出每个检测到的动作实例的时间戳及其动作类预测。这两项任务的评估指标将在第4节中解释。
3.2框架
概述.我们的总体框架如图2所示。在训练期间,从单帧监督中学习,SF-Net挖掘伪动作和背景帧。在标记帧的基础上,我们使用三个损失联合训练一个分类模块对每个标记帧和整个视频进行分类,并训练一个动作识别模块预测每个帧被动作的概率。在下文中,我们概述了框架,而帧挖掘策略和不同损失的细节将在第3.3节中描述。
特征提取 对于N个视频的训练batch,将所有帧的特征提取并存储在特征张量X∈RN×T×D中,其中D为特征维数,T为帧数。由于不同的视频时间长度不同,当视频的帧数小于T时,我们简单地填充零。
分类模块 分类模块输出输入视频中所有帧的每个动作类的分数。为了对每个标记帧进行分类,我们将X输入到三个全连接(FC)层中,以得到分类分数C∈RN×T×Nc+1。然后使用分类分数C来计算帧分类损失Lframe。我们还按照[24]中的描述聚合C来计算视频级分类损失Lvideo。
动作识别模块 如图2所示,我们的模型有一个确定阳性动作帧的动作识别分支。与分类模块不同,actionness模块只为每个帧生成一个标量,以表示该帧包含在动作片段中的概率。为了预测动作评分,我们将X输入两个时间卷积层,然后是一个FC层,从而得到动作评分矩阵A∈ RN×T。我们在A上应用sigmoid,然后计算二元分类损失Lactionness。
3.3伪标签挖掘和训练目标
标记帧处的动作分类。我们使用交叉熵损失进动作帧分类。由于视频输入batch中有NT帧,且大多数帧未标记,我们首先过滤标记的帧进行分类。假设我们有K个带标签的帧,其中K«NT。我们可以从C中获得K个标记帧的分类激活。这些分数被馈送到Softmax层以获得分类概率pl∈RK×NC+1 对于所有标记的帧。该batch视频中标注帧的分类损失公式如下:
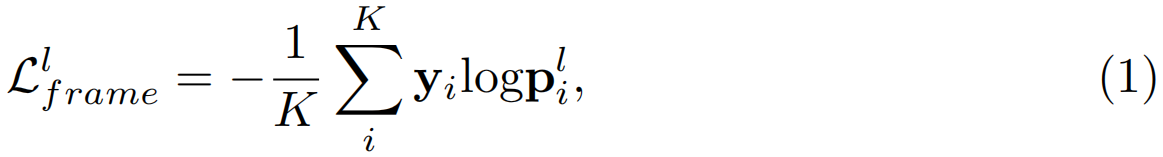
其中,pli表示第i个标记动作帧的预测。
帧的伪标记。由于每个动作实例只有一个标签,正例的总数非常少,可能很难从中学习。虽然我们不使用完整的时间标注,但很明显,动作是跨越连续帧的较长事件。为了增加模型可用的时间信息,我们设计了动作帧挖掘和背景帧挖掘策略,在训练过程中引入更多的帧。
(a) 动作帧挖掘:我们将每个有标签的动作帧视为每个动作实例的锚帧。我们首先设置扩展半径r,以限制到锚帧t的最大扩展距离。然后我们从t-1帧扩展到过去,从t+1帧扩展到未来。假设锚帧的动作类由yi表示。如果当前扩展帧与锚定帧具有相同的预测标签,并且yi类的分类分数高于锚定帧乘以预定义值ξ的分数,那么我们用标签yi标注该帧,并将其放入训练池。否则,我们将停止当前锚帧的扩展过程。
(b) 背景帧挖掘:背景帧在定位方法[19,26]中也很重要并被广泛使用,以提高模型性能。由于在单帧监督下没有背景标签,我们提出的模型能够从N个视频中的所有未标记帧中定位背景帧。一开始,我们没有监督背景帧的位置。显式引入一个背景类可以避免将一个帧被强制分类为一个动作类。我们提出的背景帧挖掘算法可以为我们提供训练此类背景类所需的监督,从而提高分类器的辨别能力。假设我们试图挖掘ηK个背景帧,我们首先从C中收集所有未标记帧的分类分数。η是背景帧与标记帧的比率。然后,这些分数沿背景类排序,以选择最高的ηK个分数pb∈RηK作为背景帧的得分向量。在前ηK个帧上,通过以下公式计算伪背景分类损失:,
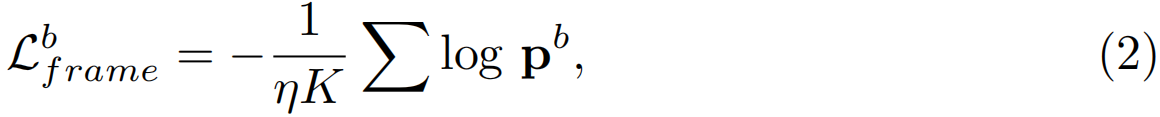
背景帧分类损失帮助模型识别不相关的帧。[19,26]中的背景挖掘要么需要额外的计算资源来生成背景帧,要么采用复杂的损失进行优化,我们在多个视频中挖掘背景帧,并使用分类损失进行优化。所选的伪背景帧在初始训练阶段中可能会有一些噪声。随着训练的发展和分类器辨别能力的提高,我们能够减少噪声,更正确地检测背景帧。以更正确的背景帧作为监督信号,可以进一步提高分类器的可鉴别性。在我们的实验中,我们观察到这种简单的背景挖掘策略可以产生更好的动作定位结果。我们将背景分类损失与标记的帧分类损失相结合来表示单帧分类损失
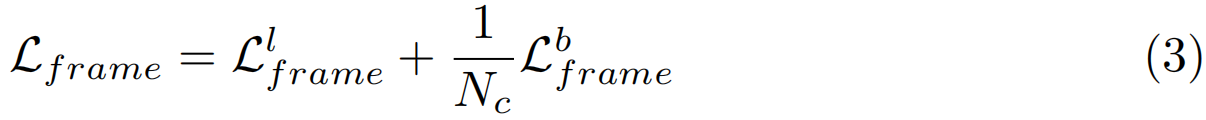
其中Nc是受到背景类影响的动作类的数量。
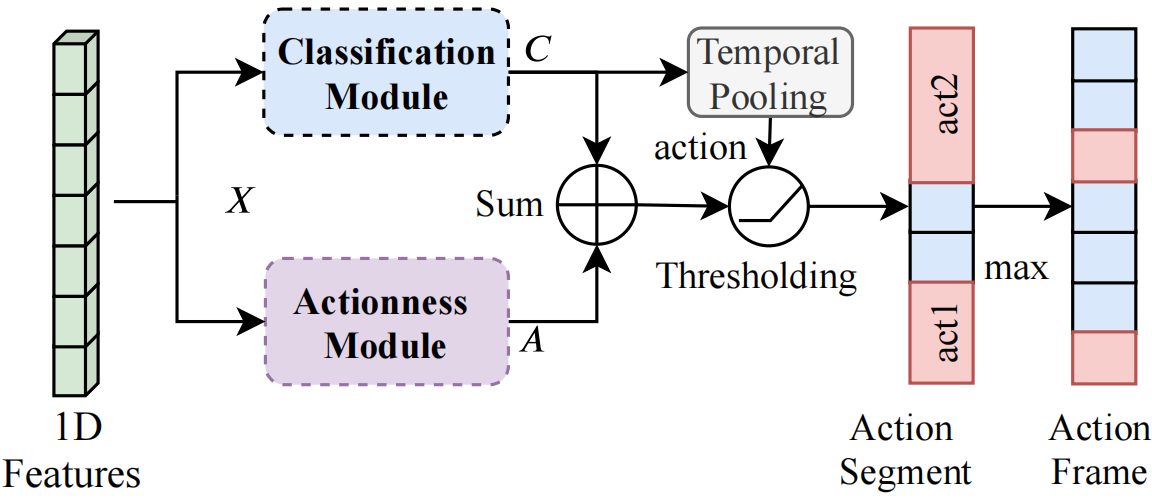
图3。SF-Net的推理框架。分类模块输出每帧的分类分数C,用于识别给定视频中可能的目标动作。动作识别模块生成动作评分,确定一个帧包含目标动作的可能性。动作识别评分和分类评分用于根据阈值生成动作片段。
标记帧处的动作识别预测。在完全监督的TAL中,各种方法学习生成可能包含潜在活动的动作建议[37,18,6]。基于此,我们设计了actionness模块,使模型关注与目标动作相关的帧。我们的actionness模块不是在提案方法中生成时间段,而是为每一帧生成actionness分数。动作识别模块与SF-Net中的分类模块并行。它为时间动作定位提供了额外的信息。我们首先收集动作识别得分Al∈RK训练视频中的标签帧。帧的动作识别得分值越高,该帧属于目标动作的概率越高。我们还使用了背景帧挖掘策略来获得动作识别评分Ab∈RηK。动作识别损失的计算公式为:
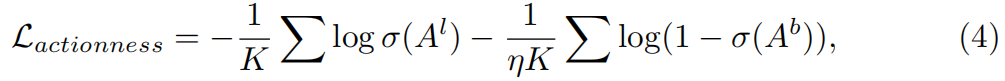
其中σ是将动作识别得分调整到[0,1]的sigmoid函数。
总目标。我们使用[24]中所述的视频级损失来解决视频级的多标签动作分类问题。对于第i个视频,选择分类激活C(i)的每个类别(其中k=Ti/8)的前k个激活,然后平均以获得特定于类别的编码ri∈ RC+1如[27,24]所示。我们对视频vi中的所有帧标签预测进行平均,以获得视频级别的ground-truth qi∈RNc+1 。视频级损失通过以下公式计算:
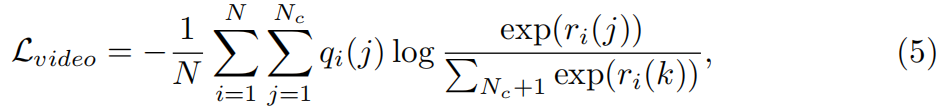
其中,qi(j)是qi的第j个值,代表视频vi属于第j类的概率值。
因此,我们提出的方法的总训练目标是
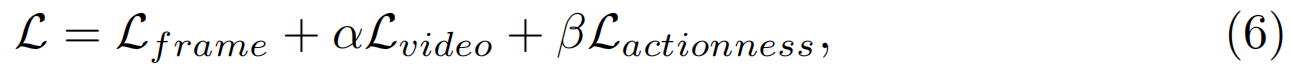
其中,Lframe,Lvideo和Lactionness分别表示帧分类损失、视频分类损失和动作识别损失。α和β是利用不同损失的超参数。
3.4推理
在测试阶段,我们需要给出每个检测到的动作的时间边界。我们遵循之前的弱监督工作[25],通过对分类分数进行时序合并和阈值化来预测视频级别标签。如图3所示,我们首先通过将视频的输入特征输入到分类模块和动作模块来获得分类分数C和动作分数A。对于片段定位,我们遵循[25,26]中的阈值策略,将动作帧保持在阈值以上,连续动作帧构成动作片段。对于每个预测的视频级动作类,我们通过检测一个间隔来定位每个动作片段,该间隔内的每一帧的分类分数和动作识别分数之和都超过了预设阈值。我们只需将检测到的片段的置信度分数设置为其最高帧分类分数和动作识别分数之和。对于单帧定位,对于动作实例,我们选择检测片段中激活分数最大的帧作为定位动作帧。
4实验
4.1数据集
THUMOS14。THUMOS14[13]中有101个动作类别的1010个验证和1574个测试视频。其中,20个类别在200个验证和213个测试视频中有时间标注。该数据集具有挑战性,因为它平均每个视频包含15个活动实例。与[14,16]类似,我们使用验证集进行训练,使用测试集评估我们的框架。
GTEA。GTEA中包含了28段视频,讲述了厨房中7种细粒度的日常活动[15]。一个活动由四个不同的主题执行,每个视频包含约1800个RGB帧,显示7个动作的序列,包括背景动作。
BEOID。BEOID中有58个视频[9]。平均每个视频有12.5个动作实例。平均长度约为60秒,总共有30个动作类。如[23]所述,我们将未剪辑的视频按80-20%的比例随机分割,用于训练和测试。
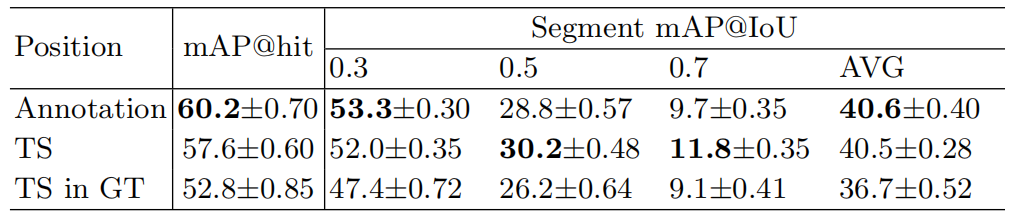
表1。在THUMOS14上模拟单帧监督的不同方法的比较。“Annotation”是指模型使用人类标注的帧进行训练。“TS”表示使用均匀分布从动作实例中采样单个帧,而“TS in GT”在每个活动的中间时间戳附近使用高斯分布。段定位的平均值是从IoU 0.1到0.7的平均图。
我们使用经过Kinetics训练的I3D网络[4]来提取视频特征。对于RGB流,我们将帧的最小尺寸重新缩放到256,并执行大小为224×224的中心裁剪。对于流,我们采用TV-L1光流算法[39]。我们遵循[24]中的双流融合操作,整合来自外观(RGB)和运动(流)分支的预测。I3D模型的输入是16帧的堆栈。
4.2实施细节
在所有数据集上,我们将学习率设置为10−3对于所有实验,使用Adam[14]以32的batch量训练模型。减肥超参数α和β设置为1。模型性能对这些超参数不敏感。对于挖掘背景帧时使用的超参数η,我们在THUMOS14上将其设置为5,在其他两个数据集上将其设置为1。GTEA、BEOID和THUMOS14的迭代次数分别设置为500、2000和5000。
4.3评估指标
(1)段定位:我们遵循三个数据集提供的标准协议进行评估。评估协议基于动作定位任务的不同联合交集(IoU)值的平均精度(mAP)。
(2)单帧定位:我们还使用mAP来比较性能。当预测的单帧位于ground-truth段的时间区域时,它被认为是正确的,并且类标签是正确的,而不是测量IoU。我们使用mAP@hit表示处于正确动作段的选定动作帧的平均精度。
4.4标注分析
单帧监督仿真。首先,为了模拟基于上述三个数据集中存在的ground-truth边界标注的单帧监督,我们探索了对单个帧进行采样的不同策略
表2。三个数据集上不同标注器之间的单帧标注差异。我们显示了由标注器1、标注器2、标注器3和标注器4标注的动作片段的数量。在最后一列中,我们报告了每个数据集的ground-truth动作片段总数。

单帧标注。我们还邀请了四位具有不同背景的标注者为三个数据集上的每个动作片段标记一个帧。标注过程的更多细节可以在补充材料中找到。在表2中,我们展示了由不同标注器标注的不同数据集的动作实例。表中的基本事实表示在完全监督设置中标注的动作实例。从该表中,我们可以看出,不同标注器的动作实例数量差异非常小。标记帧的数量与完全监督设置中的动作片段数量非常接近。这表明标注器对目标动作有共同的理由,并且几乎不会错过动作实例,尽管它们只暂停一次来标注每个动作的单个帧。每个动作实例。我们按照[23]中的策略生成均匀高斯分布的单帧标注(用GT中的TS和TS表示)。我们在表1中报告了不同IoU阈值下的片段定位和THUMOS14上的帧定位结果。每个单帧标注的模型训练五次。表中报告了mAP的平均值和标准差。与在采样帧上训练的模型相比,在人工标注帧上训练的模型达到了最高的性能mAP@hit.由于动作帧是预测段中预测分数最大的帧,因此模型的预测分数较高mAP@hit当人们需要检索目标动作的帧时,可以帮助更准确地定位动作时间戳。当采样帧从接近中间的时间戳到动作片段(GT中的TS)时,该模型的性能不如其他模型,因为这些帧可能不包含完整动作的信息元素。对于片段定位结果,基于真正的单帧标注训练的模型在较小的IoU阈值下获得较高的映射,而基于从动作实例均匀采样的帧训练的模型在较大的IoU阈值下获得较高的映射。它可能是由均匀分布的采样帧产生的,该采样帧包含给定动作实例的更多边界信息。
我们还展示了单帧标注相对于相应动作片段的相对位置分布。如图4所示,在完全监督的设置中,存在来自ground-truth的动作实例的时间范围之外的罕见帧。由于带标注的单帧的数量几乎与动作片段的数量相同,我们可以得出如下推论:
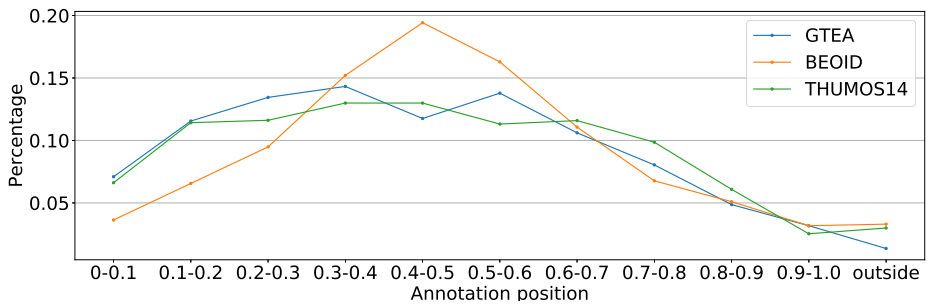
图4。三个数据集上人类标注单帧的统计。X轴:单帧落在整个动作的相对部分;Y轴:带标注帧的百分比。我们使用不同的颜色来表示标注在不同数据集上的分布。
单帧标注包含几乎所有潜在的动作实例。我们发现标注者更喜欢在动作实例的中间部分附近标注帧。这表明人类可以在不看整个动作片段的情况下识别动作。另一方面,与完全监督的标注相比,这将显著减少标注时间,因为我们可以在单帧标注之后快速跳过当前动作实例。
不同监督的标注速度。为了测量不同监督所需的标注资源,我们对GTEA进行了研究。四名标注员经过训练,熟悉GTEA中的动作类。我们要求标注者指出持续93分钟的21个视频的视频级别标签、单帧标签和时间边界标签。在观看时,标注者可以快速浏览、暂停和转到任何时间戳。平均而言,每个人标注1分钟视频所用的标注时间,视频级别标签为45秒,单帧标签为50秒,片段标签为300秒。单帧标签的标注时间接近视频级别标签的标注时间,但远小于完全监督标注的时间。
4.5分析
每个模块的有效性、损失和监督。为了分析分类模块、动作模块、背景帧挖掘策略和动作帧挖掘策略的贡献,我们对THUMOS14、GTEA和BEOID数据集进行了一系列消融研究。不同阈值下的路段定位图如表3所示。我们还比较了只有弱监督的模型和完全监督的模型。基于[24]实现了监督薄弱的模型。
我们观察到,单帧监督模型优于弱监督模型。在GTEA和BEOID数据集上可以获得较大的性能增益,因为单个视频通常包含多个动作类,而在THUMOS14中,一个视频中的动作类较少。背景帧挖掘策略和动作帧挖掘策略都提高了性能
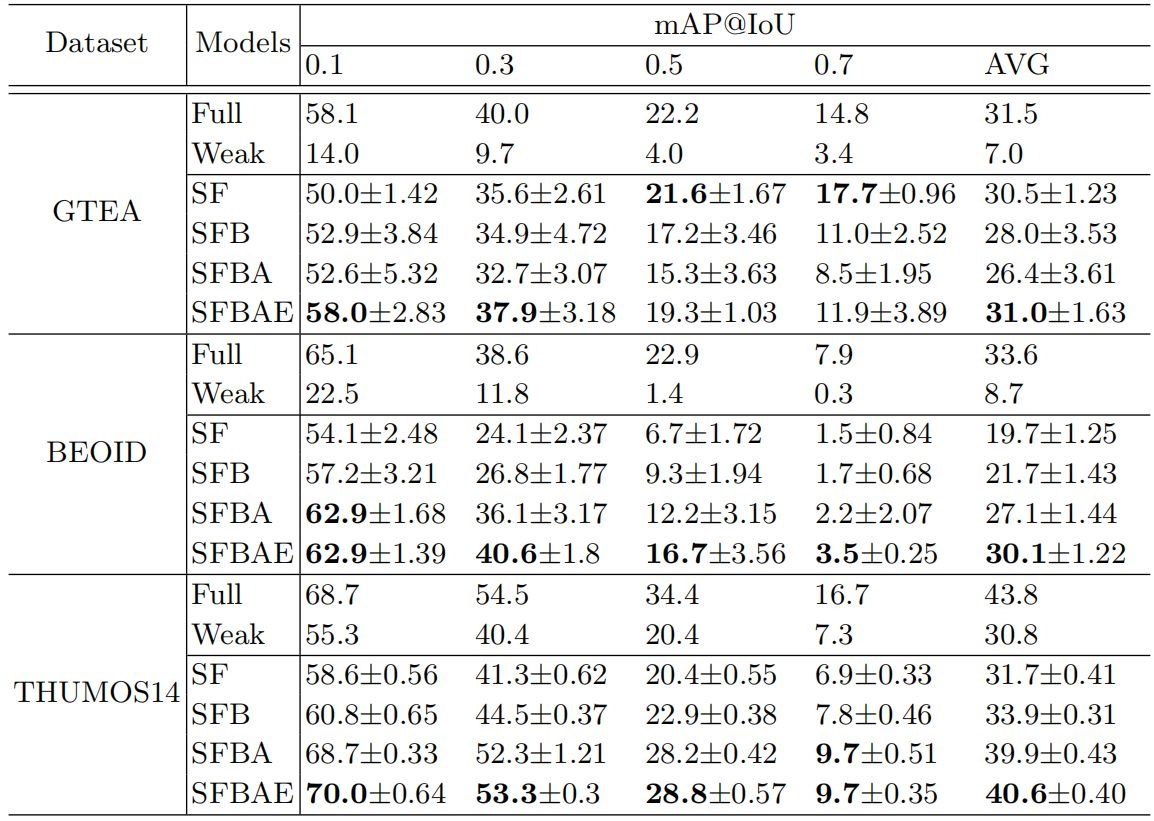
表3。三个数据集上不同IoU阈值下的段定位图结果。弱表示仅使用视频级别标签进行训练。所有动作帧均用于全面监督方法。SF使用额外的单帧监督和帧级分类损失。SFB表示在训练中加入伪背景帧,而SFBA采用动作识别模块,SFBAE表示在模型中加入动作帧挖掘策略。对于基于单帧标注训练的模型,我们报告了五次运行的平均值和标准偏差结果。平均值是从IoU 0.1到0.7的平均地图。
在BEOID和THUMOS14上,通过在训练中加入更多帧,GTEA的性能下降,主要是因为GTEA几乎不包含背景帧。在这种情况下,使用背景挖掘和旨在区分背景和动作的动作模块是没有帮助的。actionness模块对于BEOID和THUMOS14数据集运行良好,尽管actionness模块只为每帧生成一个分数。
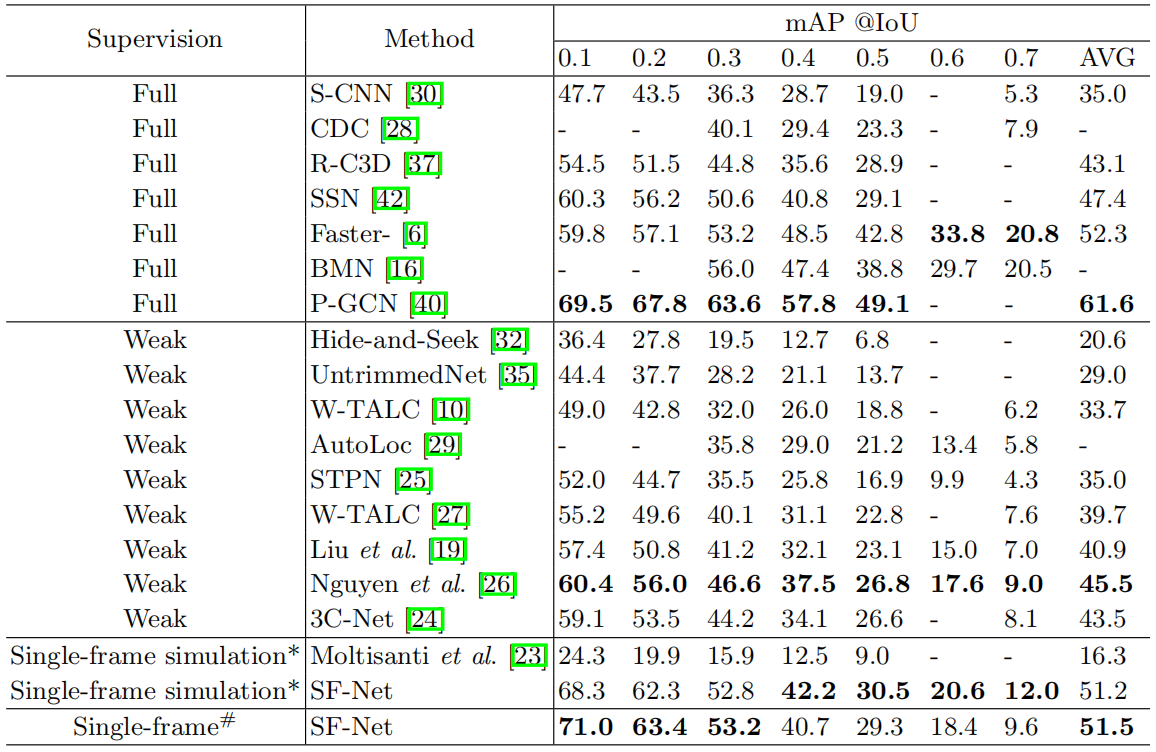
与最新技术的比较。在THUMOS14测试装置上的实验结果如表4所示。我们提出的单帧动作定位方法与现有的弱监督时间动作定位方法以及几种全监督时间动作定位方法进行了比较。无论特征提取网络的选择如何,我们的模型在所有IoU阈值下都优于以前的弱监督方法。即使每个动作实例只提供一个单独的帧,增益也是相当可观的。与基于动作片段均匀采样帧训练的模型相比,基于人工标注帧训练的模型在较低的IoU下获得了更高的映射,这种差异来自于这样一个事实,即来自ground-truth动作片段的均匀采样帧包含关于不同动作的时间边界的更多信息。由于THUMOS14数据集中有许多背景帧,单帧监督有助于所提出的模型在整个视频中定位潜在的动作帧。请注意,受监督的方法有回归模块来细化动作边界,而我们只是对分数序列设定阈值,仍然可以获得可比的结果。
表4。THUMOS14数据集上的片段定位结果。报告了不同IoU阈值下的mAP值,AVG列表示IoU阈值下的平均mAP从0.1到0.5。*表示基于ground-truth标注模拟单帧标签。#表示单帧标签由人工标注器手动标注。
5 结论
在本文中,我们研究了如何利用单帧监督来训练时间动作定位模型,用于推理过程中的分段定位和单帧定位。我们的SF-Net通过预测动作评分、伪背景帧挖掘和伪动作帧挖掘充分利用了单帧监督。在三个标准基准上,SF-Net在段定位和单帧定位方面显著优于弱监督方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号