
Uncertainty-Aware Weakly Supervised Action Detection from Untrimmed Videos
本篇论文收录于ECCV2020,主要介绍了通过弱监督学习来检测时空动作,地址如下:
以下是本人对这篇论文的大致翻译及粗浅理解,难免有不少错漏之处,敬请包涵与指正。
摘要
尽管视频分类取得了进展,但时空动作识别的进展滞后。一个主要的促成因素是对视频每一帧进行标注的高昂成本。在本文中,我们提出了一个只用视频级标签进行训练的时空动作识别模型,因为它更容易标注。我们的方法利用了多帧学习框架内在大型图像数据集中训练的每帧person检测器。我们展示了如何在标准多示例学习假设(每个bag至少包含一个具有指定标签的示例)无效的情况下,使用新的概率变量MIL来应用我们的方法,其中我们估计每个预测的不确定性。此外,我们报告了AVA数据集上的第一个弱监督结果,以及UCF101-24上弱监督方法中的最先进结果。
1 介绍
由于Kinetics和Moments in Time等大型数据集,视频分类最近取得了巨大的进步,这些数据集支持视频专业神经网络架构的训练。然而,其他视频理解任务(如时空动作检测)的进展相对滞后。用于动作识别的数据集较少,也明显小于视频分类对应的数据集。这样做的一个原因是使用时空标签对视频进行标注的成本过高——动作的每一帧都必须手动使用边界框进行标记。此外,标注行动的时间边界不仅困难,而且往往模棱两可,标注者无法就行动的开始和结束时间达成共识。
在本文中,我们提出了一种只使用弱视频级标注来训练时空动作检测器的方法,如图1所示。为了实现这一点,我们利用了基于图像的个人检测器,这些检测器已经在大型图像数据集(如Microsoft COCO)上进行了培训,并且在外观、场景和姿势的巨大变化中都是准确的。我们采用多示例学习(MIL)
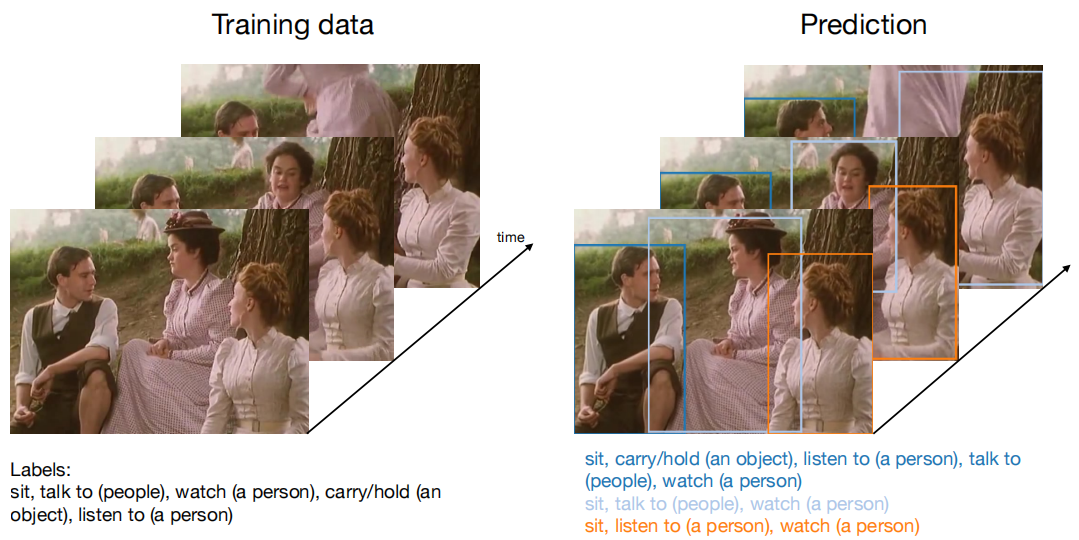
图1。我们提出了一种在具有挑战性的真实数据集上仅使用弱视频级别标签来训练时空动作检测器的方法。请注意,我们拥有的视频级标签可能适用于视频中的多个人,并且这些标签可能仅在输入片段的未标注时间间隔内处于活动状态。
框架,其中一个person tubelet是一个示例,视频中的所有person tubelet形成一个bag。在我们的方法中,一个重要的考虑因素是标签噪声的存在:这是由于使用未在感兴趣视频数据集上训练过的现成person检测器引入的,而且由于内存限制,我们必须从长视频中的大bags中采样tubelet。在这两种情况下,可能违反标准的多示例学习假设,即每个bag至少包含一个带有bag级别标签的示例。我们不知道以前的工作已经明确地解决了这个问题,我们使用MIL的概率变量来解决这个问题,我们在其中估计示例级预测的不确定性。
使用我们的方法,我们在UCF101-24数据集上获得了弱监督方法的最先进结果。此外,据我们所知,我们报告了AVA数据集(唯一用于时空动作识别的大规模数据集)上的第一个弱监督结果,其中我们还显示了在标注不同持续时间的时间间隔视频片段时的准确性权衡。
2 相关工作
大多数以前关于时空动作识别的工作都得到了充分的监督。该区域的初始方法使用了3D滑动窗口探测器结合手工制作的体积特征。当前最先进的方法是对象检测架构的时间扩展,例如Faster-RCNN和SSD。这些方法预测帧中动作周围的边界框,使用单个帧和光流作为输入来捕获时间信息,或在输入处使用多个帧来提供时间上下文。然后使用在线贪婪算法或动态规划将预测的边界框随时间链接起来,以创建时空轨迹。我们的工作建立在这些方法的基础上,还利用了检测架构和时空链接。然而,这些方法都需要视频中每一帧的边界框标注,而我们只使用视频级别的标签,这些标签的获取成本要低得多。
弱监督的时空动作识别方法也曾被探索过,因为它们能够显著减少标注时间和成本。与我们的方法相关的是[6]的工作。Che'ron等人[6]也使用人物检测,并使用基于区分聚类的公式推断其动作标签。尽管他们的方法允许他们结合不同类型的监督,但它只能在预训练的深层特征之上有效地学习线性分类器。相比之下,我们的方法完全是端到端学习的。Mettes等人也采用了多示例学习(MIL),但使用了动作建议,而不是我们的工作和[6]使用的人类检测。而且,他们的方法依赖于额外廉价的“点”标注(为构成动作的帧子集标注的单个空间点),这也确保不违反标准MIL假设。在后续工作[28]中,作者通过加入偏差(即视频中物体的存在,动作通常发生在帧中心的偏差),消除了对“点”标注的需要。最后,Weinzaepfel等人[50]还结合人类检测使用了多示例学习框架。然而,作者假设存在稀疏的空间监督(即action tube中一小部分帧的边界框),这与我们的方法不同,我们的方法只需要视频级别标签。
我们还注意到,许多方法已经解决了时间动作检测(在时间而非空间中定位动作),仅使用视频级标签监督[48,42,31,34]。UntrimmedNET[ 48 ]使用具有两个分支的网络:一个分类模块来执行动作分类和一个选择模块来选择相关帧。Hide-and-Seek[42]通过随机隐藏视频的某些部分以强制网络关注更多的区分性帧,从而获得更精确的时间边界。然而,这些方法是在ActivityNet[4]和THUMOS14[18]等数据集上进行培训和评估的,这些数据集主要包含每个视频的一个动作,因此,与我们评估的AVA[14]等数据集相比,挑战性要小得多。
最后,我们注意到另一种对抗数据集标注的方法是各种形式的自监督学习,其中可以使用未标记的数据学习区分性特征表示。视频方面的例子包括通过学习视频[1,33,51]中容易获得的音频和图像流之间的对应关系、转录语音[44]或使用诸如hashtags[10]之类的元数据作为弱标记形式的跨模态自监督学习。然而,自我监督方法是对我们方法的补充,因为它们仍然需要有限数量的完整标记数据来完成感兴趣的最终任务。
在我们的弱监督动作检测场景中,我们从来没有为单个训练示例提供完整的时空ground-truth标注。
3 提出的方法
如图1所示,给定一组视频片段,仅对发生的动作进行片段级别的标注,我们的目标是学习一个模型来识别和定位这些动作的空间和时间。我们的方法基于多示例学习(MIL),我们将在3.1节中对其进行简要回顾。此后,我们将在3.2节中展示如何使用它进行弱监督时空动作识别。然后,我们描述了标准MIL假设在我们的场景中如何经常被违反,并描述了一种通过利用在3.3节中所述的我们网络的不确定性估计来缓解这种情况的方法。最后,我们将在3.4节中讨论我们网络的实现细节。
3.1 多示例学习
在标准多示例学习(MIL)[7]公式中,一个示例被赋予一个包含N个示例的bag,表示为x={x1,x2,…,xN}。每个示例的类标签未知,但整个bag的标签x已知。MIL的标准假设是,如果bag中至少有一个示例与该标签关联,则为bag分配一个类别标签。更正式地,我们考虑多标签分类的情况下,bag的标签向量是y∈![]() 、 如果bag子中至少存在一个带有lth标签的示例,则yl=1,否则yl=0。请注意,每个bag子都可以使用C个类别标签中的多个进行标记。
、 如果bag子中至少存在一个带有lth标签的示例,则yl=1,否则yl=0。请注意,每个bag子都可以使用C个类别标签中的多个进行标记。
我们的目标是训练一个示例级分类器(参数化为神经网络),用于预测第j个示例的p(yl=1 | xj)或标签概率。然而,由于我们只有整个bag的标签,而不是每个示例的标签,MIL方法使用聚合函数g(·)将bag i的示例级概率集合{pij}聚合为bag级概率pi,其中概率是从神经网络日志输出上的适当激活函数(sigmoid or softmax)获得:
![]()
一旦我们有了bag级别预测,我们就可以在bag级别概率和bag级别ground-truth之间应用标准分类损失,并训练使用随机梯度下降的神经网络。由于我们考虑了多标签分类的情况,所以我们使用二进制交叉熵:
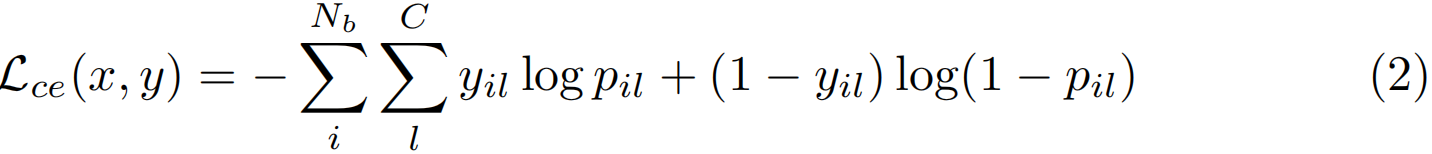
请注意,我们将pil定义为第i个bag接受lth标签的bag级别概率,该概率使用公式1获得,Nb是小批量中的bag数量。
聚集 聚合函数g(·)可以自然地在神经网络中实现,作为网络所有输出的全局池化函数。常见的置换不变池化函数分别包括max pooling、广义平均池化和LSE pooling(最大函数的光滑和凸近似):
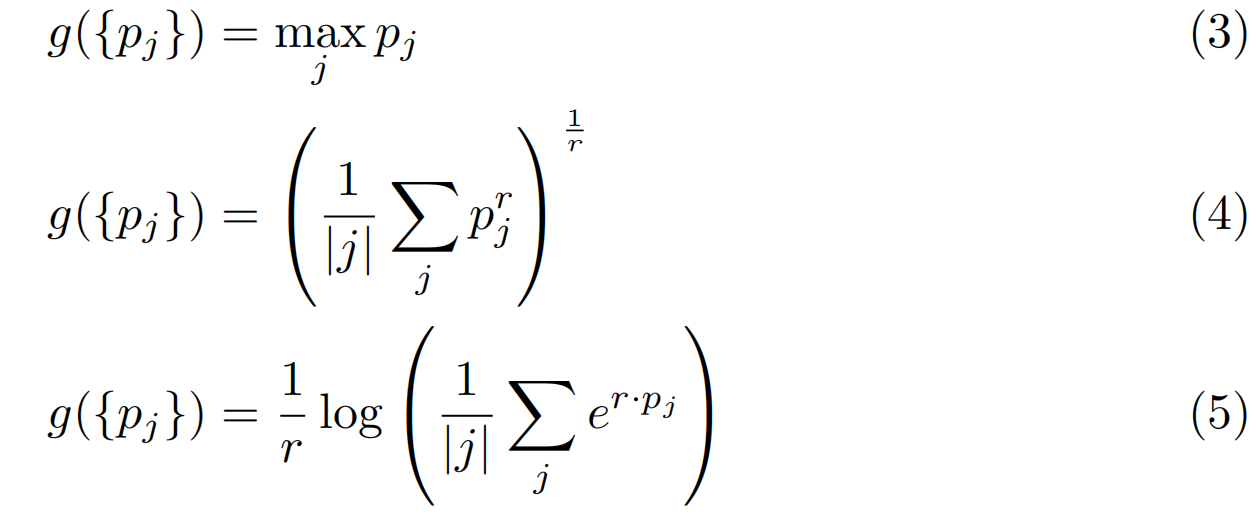
Max pooling仅考虑bag中得分最高的示例,因此自然符合MIL假设,即bag中至少有一个示例具有指定的bag级别标签。此外,它还可以对bag中没有bag级别标签的示例更具健壮性。然而,在诸如弱监督分割[36]、对象识别[45]和医疗成像[24]等应用中,平均池化和LSE池化被采用,其中bag中的多个示例通常具有bag级别标签。请注意,这两个函数的超参数r值越高,其“峰值”越大,越接近最大值。对于我们的场景(将在下一节详细介绍),我们发现最大池化是最合适的。
3.2 作为多示例学习的弱监督时空动作识别
我们的目标是学习一个模型,在只给出视频级别标注的情况下,在空间和时间上识别和定位动作。为了实现这一点,我们利用了一个在大型图像数据集(即Microsoft COCO[26])上训练过的person检测器。具体地说,我们在训练视频上运行一个person检测器,并创建person tubelet,这些person tubelet是视频中K个连续帧上的person检测。因此,我们的多示例学习bag由视频中的所有tubelets组成,并用我们作为监督的视频级别标签进行标注,如图2所示。请注意,每个视频clip的bag大小都不同,因为bag大小由视频长度和检测到的人数决定。
如图2所示,我们用于此任务的网络体系结构是一个Faster-RCNN[12]型检测器,它已被暂时扩展。给定K帧的视频clip,以及在我们的案例中为person检测的提议,网络根据K帧的时间上下文对每个提议的中心帧处发生的动作进行分类,并给定了其周围的K-1帧的时间上下文。
注意,时空定位任务是有效分解的:模型的空间定位能力取决于person检测的质量。
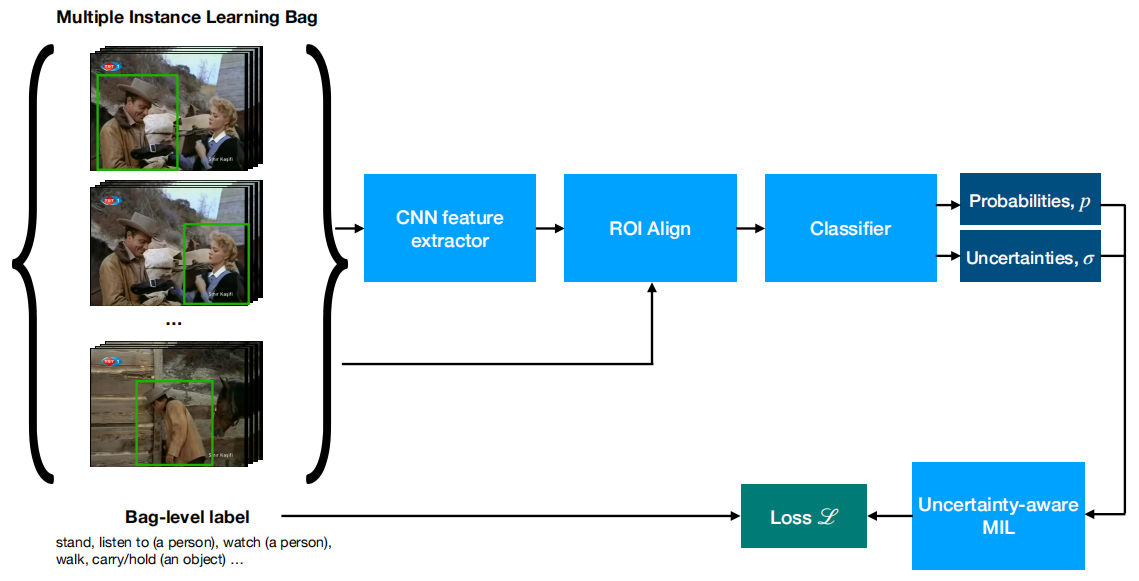
图2。我们使用多示例学习以弱监督方式训练动作检测器的方法概述:每个bag由从视频clip中提取的所有tubelets组成。这些tubelets是使用现成的person检测器获得的,该检测器未在感兴趣的数据集上进行训练。这些tubelets作为Faster-RCNN型检测器的建议,在rgb图像序列上运行。然后将bag中每个tubelets的预测汇总在一起,并与bag级标签进行比较。网络产生的不确定性估计用于补偿训练期间bag级标签中的噪声。
检测。另一方面,时间定位是通过视频连接person tubelets来实现的,这在文献[19,41,52,6]中很常见,因为这种方法可以扩展到任意长的视频。我们使用与Kalogeiton等人[19]相同的算法,该算法基于连续帧上边界框之间的空间交集(IoU),贪婪地将小时间窗口内的检测连接在一起。
最后,请注意,对于由T帧组成的视频,bag可以由T-K+1个person tubelets组成,如果在视频的每一帧上检测到一个人,并且从每一帧开始一个tubelet。由于内存限制,将整个bag安装到GPU上进行训练是不可行的。因此,我们在训练期间从每个bag中统一采样示例,同时仍保留原始bag级别标签。这会在问题中引入额外的噪声,如下所述。
3.3 标签噪音和违反标准MIL假设
在我们的场景中,通常违反标准MIL假设,即bag中至少有一个示例被分配了bag级别标签。这有两个主要因素:首先,由于计算限制,我们不能一次处理整个bag,而是必须从bag中采样示例。因此,有可能对不含任何具有标记动作的tubelets的bag进行采样。发生这种情况的可能性与标记动作的持续时间与总视频长度的比率成反比。其次,在弱监督场景中,我们使用未在感兴趣的视频数据集上训练的person检测器。因此,检测器可能会出现故障,特别是当检测器的训练分布和视频数据集之间存在较大的域间隙时。假阴性(对现场person的检测缺失)是一个特殊问题,因为bag中可能没有与标记动作对应的单个person tubelets。
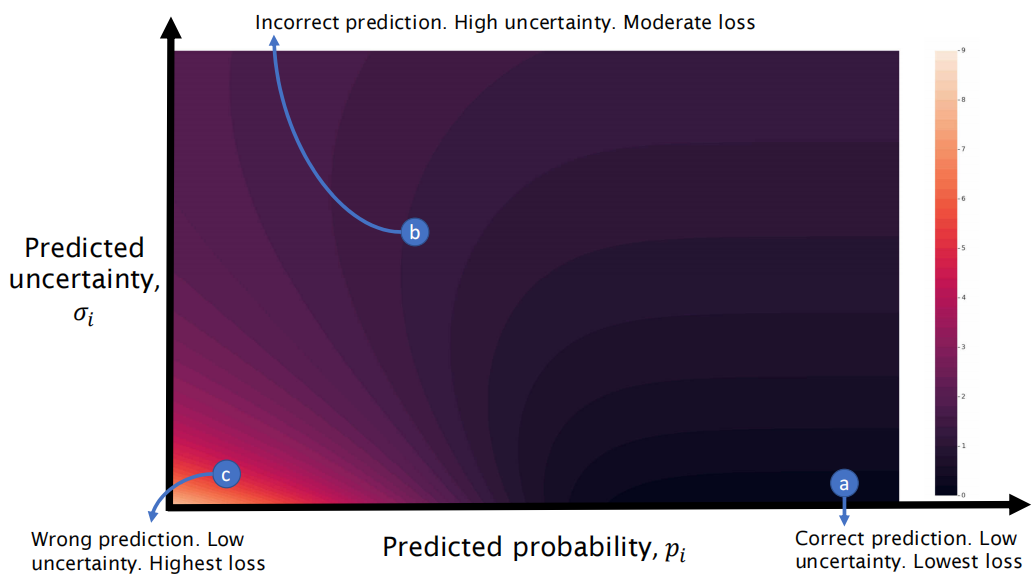
图3。基于不确定性损失的损失面(等式6)。本例中的ground-truth二进制标签为1。因此,当网络预测高概率和低不确定性(点“a”)时,损失最小化。但是,做出具有高度不确定性的错误预测不会受到太大的惩罚(点“b”),并且适用于输入bag有噪声且任何tubelets中都不存在bag标签的情况。最后,预测不确定度较低的错误标签受到的惩罚最大(c点)。
因此,存在某些情况下没有实际带有bag级标签的tubelets。为了处理这些情况,受[22,32]的启发,我们修改了网络,以额外预测bag中所有tubelets的每个二进制标签的不确定性σ∈![]() 。直观地说,为了最大限度地减少训练误差,网络可以预测不确定性较低的bag级标签,也可以预测不确定性较高的bag级标签,以避免在任何tubelets中都不存在bag级标签的情况下,因噪声bag而受到严重惩罚。最终损失与原始交叉熵一起定义为:
。直观地说,为了最大限度地减少训练误差,网络可以预测不确定性较低的bag级标签,也可以预测不确定性较高的bag级标签,以避免在任何tubelets中都不存在bag级标签的情况下,因噪声bag而受到严重惩罚。最终损失与原始交叉熵一起定义为:
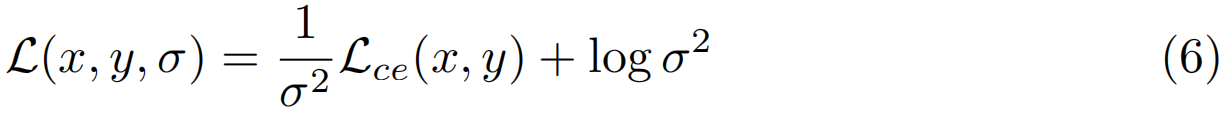
如[23]所示,这对应于假设温度为σ2的网络输出上的Boltzmann分布,并近似最小化其对数可能性。
该概率损失的损失面如图3所示。请注意,当预测标签正确且不确定性较低时,损失是如何最低的。但是,如果预测的标签不正确且不确定度较高,则损失不会太大。这与标准的交叉熵损失形成对比,后者严重惩罚了错误的预测。
3.4 网络体系结构与实现
我们的动作检测器类似于Fast RCNN[12],使用基于ResNet-50 backbone[16]的SlowFast[9]视频网络体系结构,并在Kinetics[20]上进行了预训练。如第3.2节所述,我们使用经过Detectron训练的Faster-RCNN检测模型中获得的区域建议[13]。使用RoIAlign[15]从“res5”的最后一个特征图中提取兴趣区域特征[12]。我们之所以选择这种架构,是因为它很简单,并且在完全监督的环境下,在AVA数据集[14]上取得了最先进的结果[9]。请注意,我们的网络没有使用其他视频架构中常见的附加光流输入(可被视为附加监督源)[5,19,41,6]。
我们对于每个tubelet的数据集定义的C类二进制标签的每一个预测不确定性σ∈ RC。当我们使用最大池化来聚合tubelet预测时,我们选择与所选tubelet对应的不确定性预测来计算损失。对于数值稳定性,我们使用我们的网络预测![]() ,使用“softplus”,
,使用“softplus”,![]() ,激活函数以确保positive。然后我们计算
,激活函数以确保positive。然后我们计算![]() ,并避免被0除的可能性,如果我们直接用网络预测σ2,则可能出现这种情况。
,并避免被0除的可能性,如果我们直接用网络预测σ2,则可能出现这种情况。
我们使用同步随机梯度下降(SGD)训练我们的网络,使用8个GPU,每个GPU4个批量大小。在我们的例子中,batch的每个元素都是来自多示例学习的一个bag。每个bag最多取样4个tubelets。每个tebelet本身由16个帧组成。
4 实验
4.1 实验设置
我们在UCF101-24和AVA上评估我们的方法,详情如下。请注意,其他视频数据集,如THUMOS[18]和ActivityNet[4]不适合时空定位,因为它们缺少边界框标注。
UCF101-24:UCF101-24是UCF101[43]数据集的一个子集,由24个带有时空定位标注的动作类组成,作为人类的边界框标注发布。尽管每个视频只包含一个动作类,但它可能包含多个执行不同时空边界动作的个体。此外,视频中也可能有人没有执行任何标签动作。按照标准惯例,我们使用[41]的修正标注,并报告数据集第一次分割的视频级(视频AP)平均精度。为了评估视频AP,我们使用[19]的算法将tubelet连接在一起。
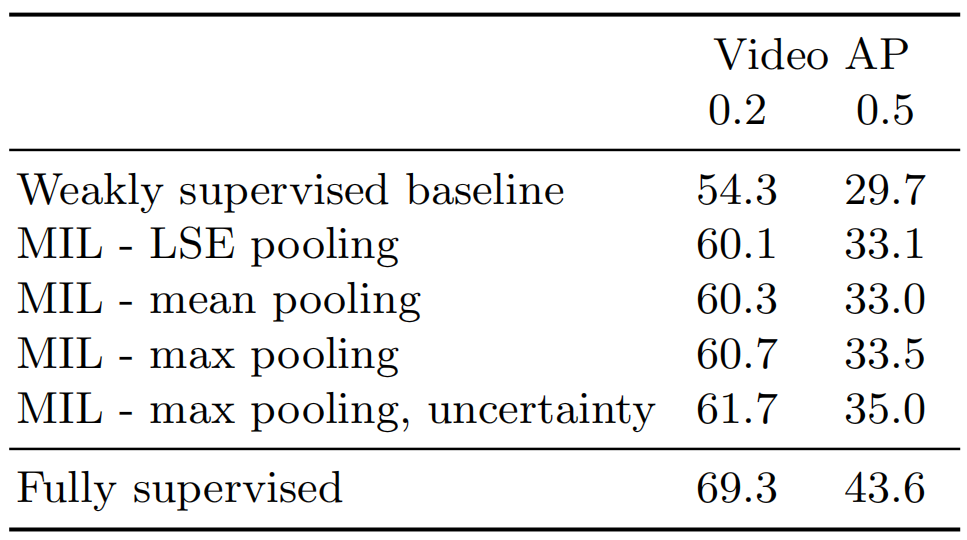
表1。在UCF101-24验证集上对我们方法的不同变体进行消融研究。我们报告了IoU阈值分别为0.2和0.5的视频mAP。
AVA[14]:该数据集由430个15分钟的电影视频clip组成。80个原子视觉动作在视频中为所有人进行了详尽的标注,其中一个人经常同时执行多个动作。数据集在视频中每秒标注关键帧。按照标准实践,我们使用v2.2标注报告IoU阈值为0.5的帧AP。
4.2 UCF101-24的实验研究
我们首先在UCF101-24数据集上对我们的模型进行消融研究。我们丢弃了整个未裁剪视频的时空标注,因此我们的多示例学习bag包含来自整个视频的tubelets。
消融实验 表1列出了我们方法的不同变体:最基础的baseline是不执行任何多示例学习,并且简单地以完全监督的方式进行训练,假设tubelets的标签是视频级别的标签。如第一行所示,此方法执行得最差,因为假定的tubelet级标签通常不正确。多示例学习的使用提高了结果,各种聚合函数的性能类似。然而,Max pooling的性能最好,我们相信这是因为Max操作最适合处理我们的tubelets中存在的噪声,如第3.3节所述。请注意,对于平均值和LSE池化,我们设置r=1。最后,引入基于不确定性的损失函数进一步改善了结果,在阈值为0.5时获得35.0的视频mAP。这是我们完全监督基线实现的性能的80%。
UCF101-24上的person检测 请注意,对于我们的弱监督实验,用于训练的person tubelets是从一个Faster-RCNN[37]person检测器获得的,该检测器仅在Microsoft COCO[26]上训练过。COCO和UCF之间存在显著的域差距,UCF上的人物框标注协议也与COCO的不一致(例如,骑马的人的边界框通常包括UCF中的马)。当使用0.5的IoU阈值表示正确匹配时,我们在培训期间使用的person检测与ground-truth person框相比,召回率仅为46.9%,这一事实反映了这些差异。此外,我们的人体tubelets在训练集上的精确度仅为21.1%。导致这种情况的一个主要因素是UCF动作标注并非详尽无遗——视频中可能有人根本没有贴标签,因为他们没有执行标签动作。然而,这些人仍将被COCO培训的检测person检测到,并在评估期间被视为假阳性。
事实上,我们能够用这些标注来训练我们的模型,这证明了我们的多示例学习方法能够处理训练集中的标签噪声。UCF101-24数据集标签中的不一致性在补充文件中进一步详细说明,Ch'eron等人之前也注意到了这一点。[6]。
对于我们的完全监督基线的训练来说,人身检测中的噪声不是问题,因为除了预测框外,它还使用ground-truth框进行训练。在这种情况下,由于我们有框级别的监督,在完全监督的训练期间,IoU大于0.5且具有ground-truth检测的预测检测被分配ground-truth 边界框的标签,或者负标签。
由于本文的目的不是为了开发更好的人体检测器或追踪器来构建人体tubelets,因此我们使用Ch'eron等人[6]公开发布的Faster-RCNN检测器来进行UCF101-24验证集的所有评估。该检测器最初在COCO上进行训练,然后使用Detectron在UCF101-24训练集上进行微调[13]。
tubelets 取样的效果对于我们使用的长度为K=16的tubelets,UCF101-24数据集中的每个视频平均有33.1个tubelets。在计算中,我们只考虑具有小于0.5的时空IOU的tubelets柱。如果我们从视频的每一帧中计算一个,就会得到更多的tubelets。
由于我们最多可以在16GB Nvidia V100 GPU上安装16个tubelets,因此很明显,有必要对每个bag子中的tubelets进行取样。请注意,UCF视频通常有大量的tubelets,因为视频中经常有许多人没有被标记为执行动作。如前一小节所述,这也是一个重要的噪声源。
表2显示了更改批次大小(bag数)和每个bag采样的tubelets数的效果,以便最大限度地利用GPU内存。我们可以看到,不确定性损失在所有情况下都有帮助,并且随着批量的减少,精度会降低。我们认为,这是由于当更多的tubelets来自同一视频时,批量归一化统计数据过于相关。
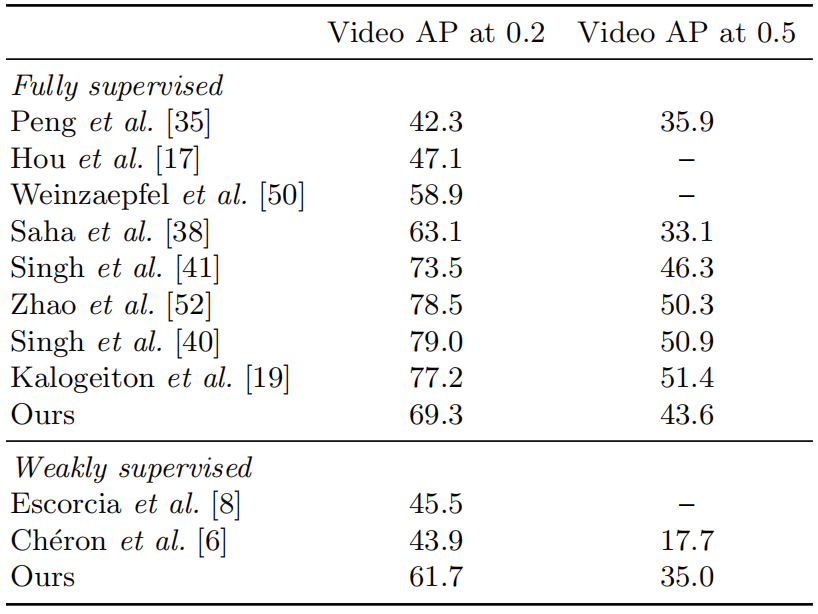
与最新技术的比较 表3将我们的结果与最新技术进行了比较。表的下半部分显示,我们的性能大大优于以前的弱监督方法。上半部分显示我们的完全监督基线与完全监督的最新技术相比也具竞争性,尽管这不是这项工作的主要目标。与我们的方法相比,完全监督的方法是基于动作检测器的,该检测器通过网络直接预测人物建议,因此能够更有效地处理UCF101-24数据集的人物标注特性。在下一节中,我们在AVA实验中没有观察到任何person检测问题。
表2。每个训练批次中bag数量对准确性的影响(视频AP为0.5)。不确定性损失提高了所有场景中的准确性。虽然bag数量较少,但体积较大,可以减少取样带来的噪音,同时也会导致batch归一化数据过于相关,降低准确性。

表3。在完全监督和弱监督情况下,与UCF101-24数据集上的最新方法进行比较。
定性结果 图4显示了我们方法的定性结果。前两行显示了我们方法的成功案例,其中tubelets检测和连接表现良好。第三排显示了一个失败案例,因为绿色跑道代表的篮球运动员实际上没有执行“篮球扣篮”动作。根据UCF101-24标注,只有用蓝色轨迹表示的玩家执行此操作。因此,此视频clip是一个视频示例,其中有许多人没有执行视频标注的动作,对于我们的弱监督方法来说尤其具有挑战性。第四行显示了一个不同的故障案例作为错误

图4。UCF101-24的定性示例。请注意,边界框的颜色取决于轨迹的标识。动作标签和tube分数从边界框的左上角开始标记。文中还包括进一步的讨论。
在线tubelet链接算法(我们使用了与[19]相同的方法)使得两个骑车人在相互遮挡后的身份发生了变化。
4.3 AVA实验
在本节中,我们报告了我们所知的关于AVA的第一个弱监督动作检测实验[14]。AVA数据集在15分钟视频clip中标记关键帧,其中每秒钟对每个关键帧进行一次采样(即以1 Hz的频率)。AVA数据集的评估协议测量动作检测模型在给定关键帧周围时间上下文的情况下对关键帧中发生的动作进行分类的能力。
我们通过将N个连续关键帧的标注组合成单个clip级标注来控制弱监督动作识别问题的难度。这实际上意味着我们正在从原始AVA视频中获得N秒子clip的clip级别标注。随着N的增加,弱监督问题变得更加困难,因为子clip变长,并且每个子clip中观察到的标签数量增加。注意,当N=1时,仅测试模型的空间定位能力,如在训练期间,不知道哪一个子clip级标签对应于MIL bag中的每个人tubelets。当N>1时,子clip级别标签可以对应clip中不同关键帧处的零个,一个或多个person Tubelet,因此这是一项更困难的任务。由于AVA视频clip由900秒组成,N=900表示在整个15分钟视频中丢弃时空标注的最极端情况
表4。我们的方法在AVA数据集上的结果与IoU阈值为0.5的帧映射有关。我们改变子clip的长度,从中提取clip级别的标注,以控制弱监督问题的难度。FS表示表示表示性能上限的完全监督基线。900秒的子clip是整个AVA视频clip。

表5。AVA数据集上最先进的全监督方法。

表4显示了我们的模型在此设置下的结果。正如预期的那样,子clip越短,我们的方法的性能越高。对于N=1和N=5,我们的方法分别获得了90%和72%的完全监督性能,这表明如果视频片段在短时间间隔内进行标注,则训练动作识别模型不需要边界框级标注。可以理解,N=900的结果是最差的,因为这是最困难的设置,我们在整个15分钟clip中使用视频级别的标注。
图5进一步分析了表4所示的不同监督级别的每个类别结果。正如预期的那样,更强的监督水平(更短的子clip持续时间)会导致更好的每类准确性。但是,某些动作类比其他动作类受较弱标签(较长的子clip)的影响更大。这方面的例子包括“唱到”和“听到”,这表明与完全监督的基线相比,与其他类有更大的差异。此外,一些类,如“手表(人)”、“起床”、“关上(如门、盒子)”和“拍手”,在使用子clip进行训练时表现合理(N≤ 10) ,但当使用较长的子clip进行训练时,效果要差得多。
最后,我们将我们的完全监督基线与图5中的最先进baseline进行了比较,注意,我们的弱监督结果来自10秒的子clip(表4)优于AVA数据集[14]引入的原始全监督基线,该数据集使用RGB和光流作为输入。另一方面,我们的模型只使用RGB作为输入模态。我们的SlowFast模型的表现类似于原始作者发布的结果[9]。注意,我们没有使用非局部[49]、测试时间增加或集成,这些都是提高性能的补充方法[9]。我们可以看到,与上一节中的UCF数据集相比,我们的person检测器在AVA上是准确的,因此,使用person tubelets作为建议的快速RCNN类型检测器可以实现最先进的结果。
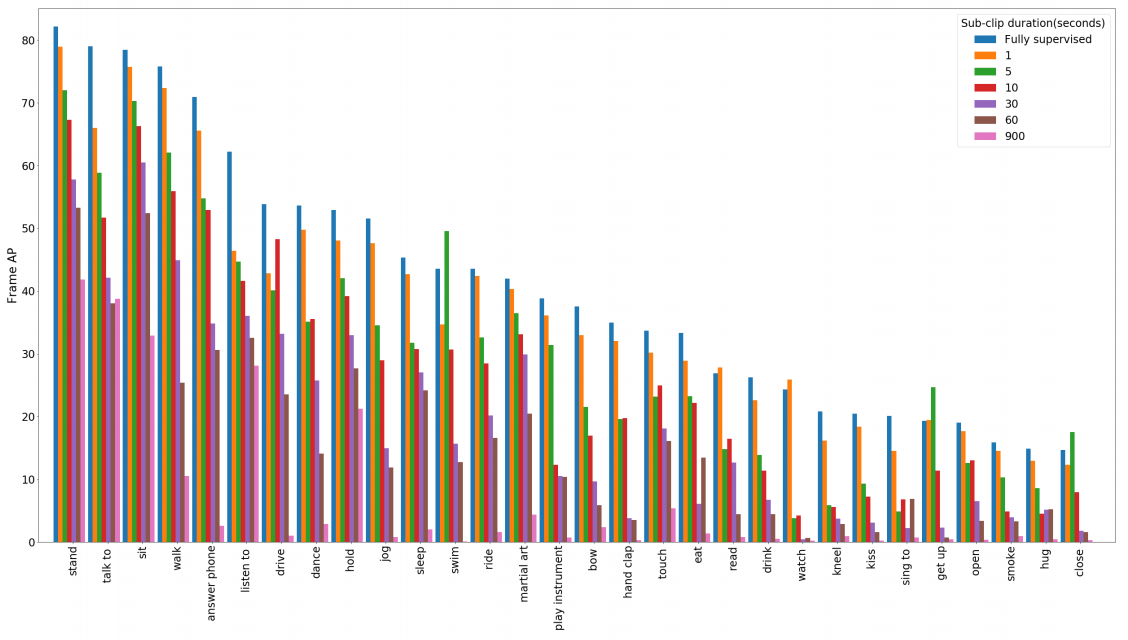
图5。在不同监督级别下(子clip持续时间越长,监督越弱),AVA数据集上的每类结果(帧AP)。为清楚起见,显示了使用完全监督模型排名的前30个类。正如所料,动作类课程受益于更强的监督,而一些课程,如“观看”、“起床”和“关闭”,很难从长的子clip中学习。
5 结论和今后的工作
提出了一种基于多示例学习的弱监督时空行为检测方法。我们的方法结合了网络做出的不确定性预测,这样它可以更好地处理我们bag中的噪声,并通过预测无法正确分类的噪声bag的高不确定性来违反标准MIL假设。我们在UCF101-24数据集上实现了弱监督方法的最新结果,并在唯一的大规模动作识别数据集AVA上报告了第一个弱监督结果。我们对视频子clip标注时间间隔的准确性权衡分析也将有助于未来的数据集标注工作。
未来的工作是合并额外的噪声源,弱标记数据,例如可以从互联网搜索引擎中爬取数据。
LSE Pooling:其定义为:
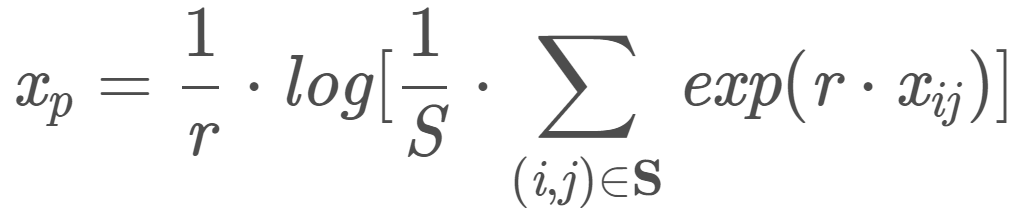
其中, xij 表示在 ( i , j ) 的激活值, ( i , j ) 是池化区域 S的一点并且 S = s × s 是池化区域 S 总点数, r是超参数。
6.补充知识
在时序行为检测中,bag指的就是一个clip视频,instance指的就是tubelet。
