Weakly Supervised Human-Object Interaction Detection in Video via Contrastive Spatiotemporal Regions
本篇论文收录于ICCV2021,主要介绍了通过弱监督学习来检测视频中人和对象的交互,论文作者制作了一个网页以介绍论文,包括论文,数据集和代码的下载,地址如下:
https://shuangli-project.github.io/weakly-supervised-human-object-detection-video
以下是本人对这篇论文的大致翻译及粗浅理解,作为一个小白,难免有不少错漏之处,敬请包涵与指正。
摘要
引入了一种弱监督对比损失,该损失旨在将视频中的时空区域与动作和物体词汇共同联系起来,并鼓励将移动物体的视觉外观时间连续性作为一种自监督形式,引入了一个包含超过6.5k个视频的数据集,其中包括人-物交互注释,这些注释是由与视频相关的句子描述半自动整理出来的。
一、介绍
本文研究了视频中弱监督的人-物交互检测问题。给定一个视频序列,如图1所示,系统在没有边界框监督的情况下,除了识别人类所采取的动作(“清洗”),还必须正确识别和定位场景中的人和交互对象(“自行车”)。虽然最近在从数亿张字幕图片或视频中学习视觉语言表示方面取得了令人印象深刻的进展,但学习到的表示专注于对给定语言查询的整个图像或视频进行分类或检索。我们的任务更具挑战性,因为它需要模型正确地检测视频多帧中的人和物体边界框。

图1在上图中,系统能在给定的视频中检测到“人清洗自行车”,以一种弱监督的方式,即在训练时不需要边界框注释。
人物交互检测主要是在静止图像的背景下进行的。然而,它们一般是发生在一段时间内的时间事件。随着时间的推移,“饮”或“推”等互动会发生在人和物体之间,使视频成为研究这个问题的自然方式。
现有的基于视频的方法主要依赖于强大的边界框监督和访问完全注释的视频数据集。然而,依赖于强有力的监督却有明显的缺陷。首先,鉴于视频中有大量的帧,详尽地注释视频中对象的空间位置是很耗时的。其次,由于对象和行动的潜在开放词汇表以及人-对象交互的组合性质,缩放到大量可能的交互并获得足够数量的地面真实边界框是具有挑战性的。第三,交互通常遵循长尾分布,常见的人-对象交互比其他发生得频繁得多。虽然监督学习通常更倾向于常见的交互,但一个鲁棒的人-对象交互检测系统应该在常见和罕见的交互上表现得同样好。
在这项工作中,我们试图利用来自自然语言句子描述的带有动词和名词短语标注的视频,以学习以弱监督的方式检测视频中的人-对象交互。这种方法是有利的,因为获得视频级注释的成本明显低于视频中的边界框。利用这些数据,可以将训练扩展到更多的视频和对象和动作的词汇表。
我们的任务是具有挑战性的,因为我们不知道训练视频中的动词-宾语查询和时空区域之间的对应关系。系统必须学会在没有空间边界框监督的情况下建立这些关系。因此,我们提出了一个时空区域的对比损失,以检测人机交互的视频。我们的损失以一种弱监督的方式将候选时空区域与动作和物体词汇表共同联系起来,并利用关于运动物体的时间连续性的线索作为一种自我监督的形式。这样的公式允许我们能够处理语言查询的开放词汇表,这在人-物交互中特别可取,因为罕见和未见过的动作和对象组合非常多。
我们的论文有三个主要贡献:(1)我们提出了一种集成人类和物体时空信息的方法,用于视频中弱监督的人物交互检测。我们的方法不需要手动的边界框注释。(2)我们提出了一个时空区域的对比损失,它利用了来自视频标题的弱动词-宾语监督和来自视频中时间连续性的自我监督。它允许以零次学习的方式检测罕见和未见过的人-物交互。(3)我们引入了一个新的超过6.5k个视频的数据集来评估视频中的人-对象交互。我们证明了比任务中采用的弱监督baseline有更好的性能。我们将公开该数据集,以促进进一步的研究。
二、相关工作
最接近我们的方法是在建模视频和自然语言,视觉关系检测,和人机交互检测方面的工作。
视频和自然语言。之前的工作已经着眼于为任务联合建模视频和自然语言,如字幕、电影问题回答和短片检索。更相关的是旨在更精细地“挖掘”或调整自然语言的工作。例如,包括从未修剪的视频中检索时刻,使用对齐的指令从视频中学习,以及将自然语言与视频中的(时空)时间区域对齐。自然语言由于大量的开放词汇和复杂的交互,构成了严峻的挑战。
视觉关系检测。过去的工作研究了在单张静态图片中检测主题-谓词-对象视觉关系,这一工作线已经扩展到强监督学习。最接近我们的方法是研究弱监督视觉关系检测,其中一个模型被训练以使用在图像水平上可用的三元注释。与我们不同,Peyre等人利用预先训练过的对象检测器的固定词汇表,并使用判别聚类模型学习关系。Peyre等人是对开放语言进行建模,但只适用于强监督设置和静态图像。
人-物交互检测。人-对象交互检测是一种以人为中心的关系检测。Hoi是一个对于更深入的视觉理解十分重要的研究课题。一些数据集,如HICO-DET和V-C-COCO,已经在该领域被提出。将新的Hoi检测表示为一个零镜头学习问题。然而,这些方法都是基于静止图像的,在检测动态的人机交互方面存在困难。它们要么依赖于边界框注释,要么依赖于预先训练过的对象检测器,这在视频中表现糟糕。
三、学习对比时空区域
我们以弱监督的方式解决了检测视频中的人物交互(HOIs)的问题。由于获得用于监督学习的ground truth边界框成本昂贵且耗时,我们试图从一个视频集合中学习,其中在训练过程中只为整个视频片段提供动词-宾语短语注释。因此,我们提出了一个弱监督框架,它包含了空间和时间信息来检测视频中的HOIs。整个训练步骤如图2所示。给定一个视频片段和一个动词-宾语查询,对于每一帧,我们首先提取一组特征。这些特征包括片段中的动词-对象查询、帧和人/对象区域。这组特征通过一个区域注意模块,该模块为框架输出两个特征——一个人类注意力特征和一个对象注意力特征,它将注意力集中在与动词-对象查询更相关的区域上。这些特征,以及来自其他帧的动词-宾语特征和物体区域特征,都被传递到我们的弱监督对比损失中。
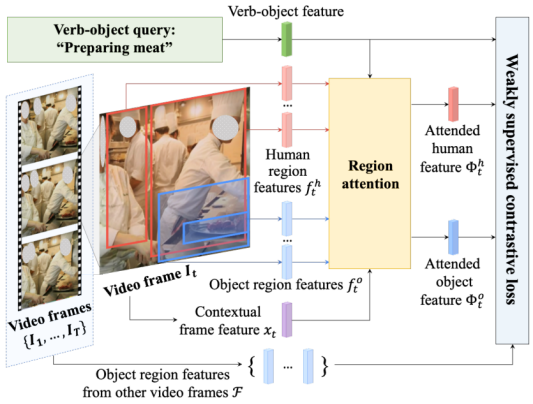
图2训练概述。给定一个视频片段和一个动词-对象查询,对于每一帧,我们首先提取它的人和对象区域特征。人/对象特征聚合进一个区域注意模块中,以关注与查询更相关的区域。利用人类注意力特征、对象注意力特征、动词-对象查询特征和其他帧的对象区域特征来计算弱监督对比损失。
1.弱监督对比损失
以弱监督的方式从语言标签中学习具有挑战性,因为系统必须自动识别,并将视频时空区域与提供的短语注释关联起来。此外,hoi通常遵循长尾分布。应用常用的分类损失是不够的,因为它需要一个固定的词汇表,且每个类的样本数量接近。此外,分类损失最大限度地提高了正确类的概率,同时抑制了所有其他类,这不适用于不太常见或没见过的对象和动词。最后,具有相似含义的单词没有明确地映射到特征空间的附近位置。
为了解决这些问题,我们引入了一个对比时空损失来学习共享的视觉语言嵌入,如图3所示。我们的损失利用了与每个训练视频相关的短语注释和关于运动对象的时间连续性的线索。我们的培训损失包含了三个见解。首先,我们学习将可能的人类和对象区域的视觉表示映射到输入动词-对象查询的相应嵌入表示,并与词汇表中其他非相关单词的嵌入表示进行对比。其次,我们鼓励时空区域在视频中保持时间一致。第三,我们在我们的模型中应用对比损失,使它能够在测试期间检测到新的未见过的人-物交互。
我们建立在对比损失的基础上,它旨在促使单位长度特征的正对接近(用点积测量),负对在特征空间中距离很远。
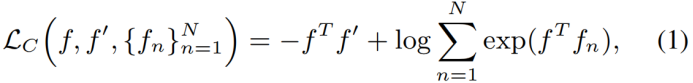
其中f为锚定特征, 为正特征,
为正特征, 为N个负特征。基于方程(1),我们提出了一种弱监督语言嵌入对齐损失来对齐时空区域与输入动词-宾语查询,以及一种自监督时间对比损失,以鼓励目标区域的时间连续性.
为N个负特征。基于方程(1),我们提出了一种弱监督语言嵌入对齐损失来对齐时空区域与输入动词-宾语查询,以及一种自监督时间对比损失,以鼓励目标区域的时间连续性.
弱监督的语言嵌入对齐损失。给定一个视频帧,我们提取它的人和目标区域建议特征,fht和fto。让e作为输入视频的ground truth动词-对象标签的语言嵌入特征。我们试图将相关的人/对象区域与ground truth动词-对象标签对齐。由于只有帧级(或视频级)动词对象标签可用,我们也寻求在每个帧中学习一个全局的人/对象特征,它与一组负面的语言嵌入特征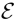 形成对比,这些特征
形成对比,这些特征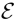 覆盖了不包括ground truth动词对象标签的词汇。
覆盖了不包括ground truth动词对象标签的词汇。
为了执行对齐,我们提出了一个区域注意模块,该模块分别计算每个人和对象区域建议的注意得分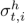 和
和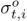 ,以测量它们与动词-对象查询的相关性。我们通过将帧It中的人类区域特征汇总为其注意分数σth的加权平均值,获得了一个人类注意力特征Φht
,以测量它们与动词-对象查询的相关性。我们通过将帧It中的人类区域特征汇总为其注意分数σth的加权平均值,获得了一个人类注意力特征Φht
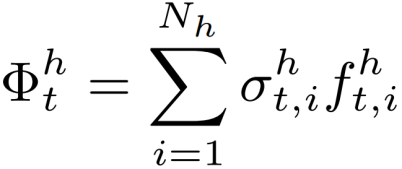
其中Nh是候选人类区域的数量。对象注意力特征Φot也有类似的形式。特征注意力“柔和地”选择少量候选人/物区域作为目标,得分较高的区域对注意力特征的贡献更大。
我们将语言嵌入对齐损失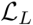 定义为一帧中的注意特征与目标标签的对齐,同时与动词或对象负特征集进行对比。根据方程(1)中对比损失的一般表达式,我们将帧It中的语言嵌入对齐损失定义为给定参与的人/对象、语言和负特征的对比损失的总和
定义为一帧中的注意特征与目标标签的对齐,同时与动词或对象负特征集进行对比。根据方程(1)中对比损失的一般表达式,我们将帧It中的语言嵌入对齐损失定义为给定参与的人/对象、语言和负特征的对比损失的总和
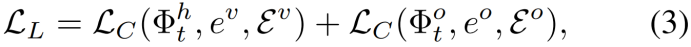
其中,ev和eo分别为目标动词和宾语特征,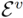 和
和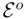 分别为负动词和负宾语特征集。更具体地说,我们重写了公式(1):
分别为负动词和负宾语特征集。更具体地说,我们重写了公式(1):
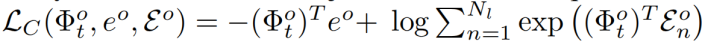
其中Φot是对象注意力特征,与公式(2)所示的人类注意力特征具有相似的形式,eo是目标对象特征,Nl是负特征集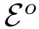 中负样本的数量。人类项也有类似的形式。我们在下图(a)中显示了此损失(仅限对象项)。“区域注意”模块为视频帧输出一个“人/对象注意力特征”。这个“人/对象注意力特征”与帧对应的语言标注中的动词/宾语形成正对。
中负样本的数量。人类项也有类似的形式。我们在下图(a)中显示了此损失(仅限对象项)。“区域注意”模块为视频帧输出一个“人/对象注意力特征”。这个“人/对象注意力特征”与帧对应的语言标注中的动词/宾语形成正对。
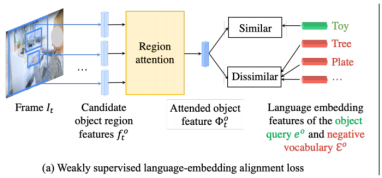
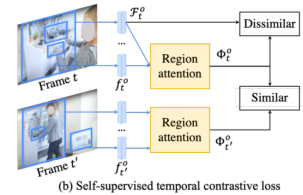
图3:弱监督的对比损失。我们的损失将视频中的时空区域的特征联合对齐为(a)输入动词-对象查询的语言嵌入特征,以及(b)可能包含目标对象的其他时空区域。此图仅显示了对象区域。同样的机制也适用于人类区域。
自我监督的时间对比损失。我们试图鼓励运动物体的时间连续性。我们还试图将我们学习到的物体特征与一组消极的视觉特征对应的可能区域进行对比。让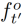 成为同一视频的另一帧的一组特征,注意力得分为
成为同一视频的另一帧的一组特征,注意力得分为 。我们将时间对比损失
。我们将时间对比损失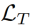 定义为在一帧中对象注意力特征
定义为在一帧中对象注意力特征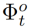 与另一帧中的对象注意力特征
与另一帧中的对象注意力特征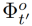 的对齐,同时与It帧中的负特征集
的对齐,同时与It帧中的负特征集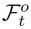 进行对比。根据方程(1)中的对比损失,我们将时间对比损失定义为:
进行对比。根据方程(1)中的对比损失,我们将时间对比损失定义为:
![]()
注意,这里的注意分数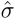 与用于语言嵌入对齐损失的soft注意分数σ不同。在时间对比损失中,我们让
与用于语言嵌入对齐损失的soft注意分数σ不同。在时间对比损失中,我们让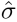 为hard注意分数,其中只有一个对象区域得分为1,而同一帧中的其他区域得分为0。在实践中,我们让soft注意得分最高的对象区域具有hard注意得分
为hard注意分数,其中只有一个对象区域得分为1,而同一帧中的其他区域得分为0。在实践中,我们让soft注意得分最高的对象区域具有hard注意得分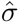 =1,这是动词-对象查询中描述的最有可能的目标对象。对于负特征集
=1,这是动词-对象查询中描述的最有可能的目标对象。对于负特征集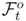 ,我们从帧中剩余的对象区域中随机选择没有被hard注意选择的。直觉是,不同帧得分最高的目标对象应该随着时间一致移动,但应该不同于同一帧中的其他对象。我们在图3(b)中说明了这种损失。
,我们从帧中剩余的对象区域中随机选择没有被hard注意选择的。直觉是,不同帧得分最高的目标对象应该随着时间一致移动,但应该不同于同一帧中的其他对象。我们在图3(b)中说明了这种损失。
完全弱监督的对比损失 我们将每一帧的最终损失定义为语言嵌入对齐和时间对比损失的总和
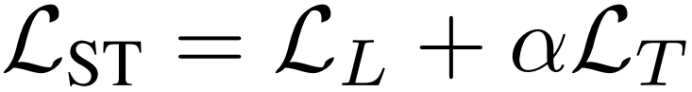
其中,α是一个超参数。当一个柔和选择的人/对象区域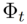 对应的特征与语言嵌入特征e和另一帧中类似的时空区域
对应的特征与语言嵌入特征e和另一帧中类似的时空区域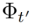 对齐时,我们的损失被最小化。
对齐时,我们的损失被最小化。
2. 特征学习
在本节中,我们将简要介绍对象特征、上下文框架特征和图2中使用的人/对象注意力特征。有关不同类型特性的更多细节,请参见补充材料。
人所引导的物体特征学习 为了获得候选对象区域的特征,我们首先使用Faster R-CNN在每个视频帧中提取对象位置建议。我们在Faster R-CNN特征金字塔网络(FPN)的所有层上应用ROI池化来提取对象区域建议的特征描述符。每个对象区域建议都有一个特征描述符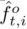 和一个边界框
和一个边界框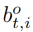 ,如图4所示。
,如图4所示。
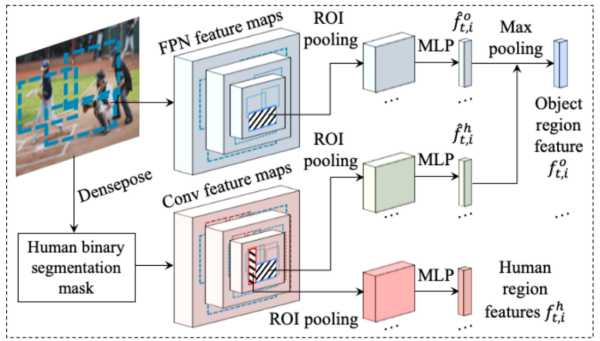
图4:提取人体/物体特征的示意图。我们学习卷积滤波器以编码Densepose分割掩码到中间特征。我们结合FPN特征图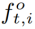 和人类conv特征图
和人类conv特征图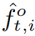 的特征。的ROI池化特征,得到每个对象区域
的特征。的ROI池化特征,得到每个对象区域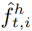
人物交互与人物和物体特征高度相关。我们假设人类和物体区域的空间共现有助于消除相互作用的物体的歧义。为了更有效地编码人-对象交互,我们将来自DensePose产生的人分割掩模的知识整合到对象建议特征中。我们使用ROI池从给定对象提议边界框的对象分割掩码中提取一个特征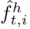 。我们对FPN特征映射和人类特征映射中的对象区域特征应用max pooling操作,以获得最终的对象建议特征
。我们对FPN特征映射和人类特征映射中的对象区域特征应用max pooling操作,以获得最终的对象建议特征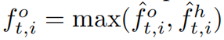 。
。
上下文帧特征学习。 人物互动是时间事件,发生在一段时间内。为了利用整个视频中的时间信息,我们使用一个软注意模块来学习每一帧的上下文特征表示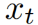 。给定将帧通过小网络获得的帧特征
。给定将帧通过小网络获得的帧特征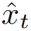 ,我们将
,我们将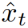 发送到嵌入层,生成一个“查询”特征向量
发送到嵌入层,生成一个“查询”特征向量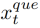 。对于同一视频中所有帧{x1,···,xT}的特征,我们使用两个不同的嵌入层来得到“键”
。对于同一视频中所有帧{x1,···,xT}的特征,我们使用两个不同的嵌入层来得到“键”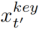 和“值”
和“值”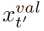 向量。我们计算“查询”和“键”的内乘积,得到当前帧和同一视频中每个帧的相似性得分
向量。我们计算“查询”和“键”的内乘积,得到当前帧和同一视频中每个帧的相似性得分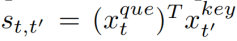 。然后对相似度分数应用一个softmax层,以归一化每一帧与当前帧的相似度。上下文帧特征是帧“值”特征的加权平均值得到的。
。然后对相似度分数应用一个softmax层,以归一化每一帧与当前帧的相似度。上下文帧特征是帧“值”特征的加权平均值得到的。
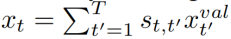
人/物区域注意力特征学习 区域注意模块计算人/物区域建议的注意分数,以衡量它们与给定的动词-对象查询的相对相关性(补充部分中的图3)。对于该帧中的每个人类区域,我们首先将其特征表示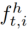 与上下文框架特征xt和动词-对象查询特征连接起来,然后通过一个小网络获得分数。我们将softmax函数应用于该帧中所有人类区域的分数,并得到最终的人类注意力分数
与上下文框架特征xt和动词-对象查询特征连接起来,然后通过一个小网络获得分数。我们将softmax函数应用于该帧中所有人类区域的分数,并得到最终的人类注意力分数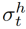 。同样,在所有对象区域上应用softmax函数后,每个对象区域都有一个对象注意得分
。同样,在所有对象区域上应用softmax函数后,每个对象区域都有一个对象注意得分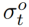 。使用注意力分数通过公式(2)聚合人/物特征。
。使用注意力分数通过公式(2)聚合人/物特征。
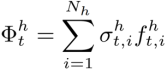
3. 训练目标
除了弱监督对比损失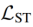 外,我们还提出了稀疏损失
外,我们还提出了稀疏损失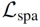 和分类损失
和分类损失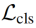 。我们对两帧的最后训练损失是所有损失的总和。
。我们对两帧的最后训练损失是所有损失的总和。
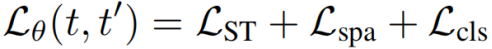
接下来我们将描述稀疏性和分类损失。
稀疏性损失。因为通常很少会有人类和物体经历输入查询中给出的动作和宾语,我们试图鼓励人类和对象建议的注意分数对单个建议实例都高,对每帧中所有其他建议的注意分数都低。为了实现这种效果,我们引入了一个稀疏性损失,它被定义为人类和物体注意分数的负对数l2范数的和:
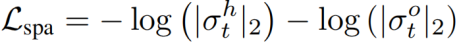
分类损失。弱监督的对比损失和稀疏性损失使我们的模型能够在给定动词-对象查询时定位对象和人。为了使我们的模型检索并定位跨视频的语言输入,我们添加了一个分类损失来预测当前视频是否包含动词宾语查询中描述的交互。在训练阶段,每个视频都有一个ground truth动词对象标签,我们给它们一个y=1的标签。我们从整个词汇表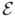 的语言特征中随机选择一个负的动词-对象标签,并为视频分配一个y=0的标签和所选择的负的动词宾语标签。该帧处的分类损失为:
的语言特征中随机选择一个负的动词-对象标签,并为视频分配一个y=0的标签和所选择的负的动词宾语标签。该帧处的分类损失为:
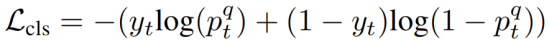
其中 是输入视频帧It的可能性,它包含动词-宾语查询q。这里的xt是帧It的上下文帧特征。
是输入视频帧It的可能性,它包含动词-宾语查询q。这里的xt是帧It的上下文帧特征。
4.推断
在推理过程中,给定一个视频框架,我们随机选择一个动词-对象查询q,并计算它们的二进制分类分数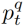 ,如式(8)所示。
,如式(8)所示。
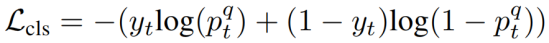
我们鼓励视频帧和动词宾语查询的匹配对在训练过程中具有更高的概率,分数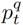 能够评估推理过程中动词宾语查询出现在给定帧中的概率。我们还有一个针对每个人或对象区域提案的注意分数
能够评估推理过程中动词宾语查询出现在给定帧中的概率。我们还有一个针对每个人或对象区域提案的注意分数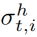 或
或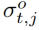 ,表示它们与给定的动词-对象查询的相关性。因此,对于每个人-对象对,我们计算它们的置信度得分为
,表示它们与给定的动词-对象查询的相关性。因此,对于每个人-对象对,我们计算它们的置信度得分为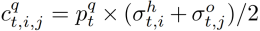 。对于HOI检测,我们预测人和物体的边界框及其Hoi标签。对于每一个视频帧,我们输入数据集中出现的所有可能的动词-对象标签,并选择具有最高置信度的动词-对象标签作为每对人类和对象区域的Hoi标签预测结果。
。对于HOI检测,我们预测人和物体的边界框及其Hoi标签。对于每一个视频帧,我们输入数据集中出现的所有可能的动词-对象标签,并选择具有最高置信度的动词-对象标签作为每对人类和对象区域的Hoi标签预测结果。
四、人-物交互视频数据集
现有的人-对象交互数据集要么关注分类,要么关注静态图像中的检测。然而,人物交互是一个时间过程,它在视频数据中更自然地完成。目前的视频数据集,如Charades、EpicKitchens、VidVRD、VidOR和YouCook,不适合人物交互检测。首先,它们中的大多数都没有人类的边界框注释。其次,对场景中的所有对象都进行了注释,带注释的对象不一定会与人类交互。此外,EpicKitchens和YouCook没有三元人类-动作-对象标签。VidVRD和VidOR用于视觉关系检测,这些关系不一定以人为中心。因此,它们不能直接用于评估基于视频的人-对象交互检测。
相反,为了研究视频中的人机交互问题,我们收集了一个大量、多样化的人类与公共对象交互的视频数据集(V-HICO)。我们的数据集有各种各样的操作和交互对象。我们的数据集比EpicKitchens(432)和YouCook(2,000)有更多的视频(6,594),每个视频都包含人与对象的交互作用。此外,与专注于家庭或厨房场景的Charades, EpicKitchens和YouCook相比,新的数据集在更多样化的户外场景中更具挑战性。
我们的V-HICO数据集包含5297个训练视频、635个验证视频、608个测试视频和54个看不见的人-物体交互的测试视频。为了测试模型在常见的人对象交互类上的性能,并泛化到新的人对象交互类,我们提供了两个测试分割,第一个在训练分割中具有相同的人对象交互类,而第二个则由看不见的新类组成。我们的训练集包括193个对象类和94个动作类。在训练集中有653个动作对象对类。看不见的测试集包含51个对象类和32个动作类和52个动作-对象对类。所有的视频都标有人类动作和相关对象的文本注释。测试集和看不见的测试集包含人框和对象边界框的注释。
我们的“看不见的”测试集(51个看不见的对象类)包含两个类存在于MSCOCO对象词汇表中,8个存在于OpenImages中,34个存在于可视化基因组中。我们使用在MSCOCO上预训练的对象检测器,表明在预训练过程中只看到了2个对象类。此外,我们的整个数据集总共有244个对象类。其中156个不存在于MSCOCO或OpenImages中,例如,“标枪”,因此不能使用在这些数据集上预先训练过的探测器来检测到。对象分布是长尾的,许多对象在公开可用的对象数据集中没有注释的训练数据。我们的模型提供了一种方法,可以在不依赖边界框注释的情况下放大到一大组对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号