

python学习笔记及作业(函数,内置模块,模块与包)
1.作业
爬取内容牛超的poping 视频并存入本地
import requests res = requests.get('http://f.us.sinaimg.cn/001lksTilx07uuNOl74Q01041200dBV50E010.mp4?label=mp4_ld&template=640x360.28.0&Expires=1560423944&ssig=seTlndPdIs&KID=unistore,video') print(res.content) with open('牛超的poping视频.mp4','wb')as f: f.write(res.content)
2.课堂笔记
(1)函数的定义方式:有参函数、无参函数、空函数,
空函数的用法很重要,宏观角度,先定义功能,具体算法可稍后实现。
函数的2种嵌套调用方法,函数的名称空间(解释了一个python文件运行时发生的过程,查找函数中某个变量时的过程)
# 今日内容: # 函数剩余部分 # 内置模块 # 模块与包 # 1.函数的定义方式 # 无参函数: 不需要接受外部传入的参数 def foo() print('haha') foo() # 有参函数: 需要接受外部传入的参数,定义多少个参数,就需要传递多少个参数 def login(user,pwd): print(user,pwdw) login('tank','123')#只有这个正确 login('tank','123','111')#多了参数 login('tank')#少了参数 # 有参函数 def max2(x,y): if x>y: print(x) else: print(y) max2(10,30) # 空函数 def func(): pass # pass代表什么都不做 # 这样就可以从宏观的角度定义所有需要写的函数 # 但此时每个函数的功能不可能快速实现,所以定义为空函数供稍后实现 # 2.函数的返回值 ''' 在调用函数时,需要接受函数内部产生的结果, ''' def max2(x,y): if x>y: return x print(x) else: return y print(y) res=max2(10,30) print(res) # 3.函数的对象 ''' 函数的对象指的是函数名指向的内存地址 ''' def func(): pass print(func)# 不加括号的func才是等价于函数名的内存地址 func()# 也就是说调用也就是函数名的内存地址+() #!!!!!!特别好用的一个功能!!!! dict1 ={ '1':func,# !!!!!只有不加()的函数名才是代表内存地址的 '2':func2 } choice=input("请输入功能编号").strip() if choice in dict1: dict1[choice]()# 此时dict[choice]即为返回的函数名+()=即为调用函数 # 4.函数的嵌套 ''' 嵌套定义: 在函数内,定义函数,可以嵌套任意多层 ''' def func1(): print('func1.....') def func2(): print('func2.....') def func3(): print('func2.....') return func3 return func2 ''' 函数嵌套调用: ''' # func2=func1()#嵌套的调用方法一#应为此时返回的是func2的内存地址 # func2()# 这里func2就代表着内存地址+(),就可以开始调用函数func2() # func3=func2() # func3() # 嵌套的调用方法二 def func1(): print('func1.....') def func2(): print('func2.....') def func3(): print('func2.....') func3() func2() func1() # 先调用func1()函数,此时print(‘func1...’), def func2(), func2()作为func1()函数的子语句 # 先执行print(‘func1...’),然后执行def func2()【此时只是对def func2()的定义】等价于无用, # 之后会执行func2(),此时就会开始调用func2() ''' !!!!!!!!!解释了是函数的运行机制!!!!!!! 函数的名称空间 python解释器自带的:内置名称空间 自定义的py文件内,顶着最左边定义的:全局名称空间 函数内部定义:局部名称空间 ''' name='tank' def func1(): print(name)# 该语句的查找情况是:先在func1()函数内部找,然后到全局空间中,即py文件中找,然后再到pyhton解释器中找 def func2(): print('jjj') print(name,'全局打印') func1() # 真正开始运行:先将解释器加载到内存中,py文件加载到内存中,开始调用函数时,再将局部加载到内存中 # 此时开始调用函数,运行到print(name)时, # 该语句的查找情况是:先在func1()函数内部找,然后到全局空间中,即py文件中找,然后再到pyhton解释器中找
(2)部分内置函数模块
time模块
os 模块
sys模块
# time模块 import time# 导入时间模块 # 获取时间戳 print(time.time()) # 等待2秒 time.sleep(2) print(time.time()) # os 模块 # 与操作系统中的文件进行交互 # 判断user2文件是否存在 import os print(os.path.exists('lll.txt'))# 获取的是操作系统里的路径 print(os.path.exists(r'F:\python学习\Day3\user2.txt'))# 获取的是操作系统里的路径 # 获取当前文件的根目录 print(os.path.dirname(_file_)) # sys模块 import sys # 获取python在环境变量中的文件路径 # 我们在运行时可以成功执行,是因为pycharm自动将我们的可执行文件路劲添加到环境变量中 print(sys.path) # 把项目的根目录添加到环境变量中 sys.path.append(os.path.dirname(_file_)) print(sys.path)
json模块
展示将python文件,运行出的结果保存到文件的过程
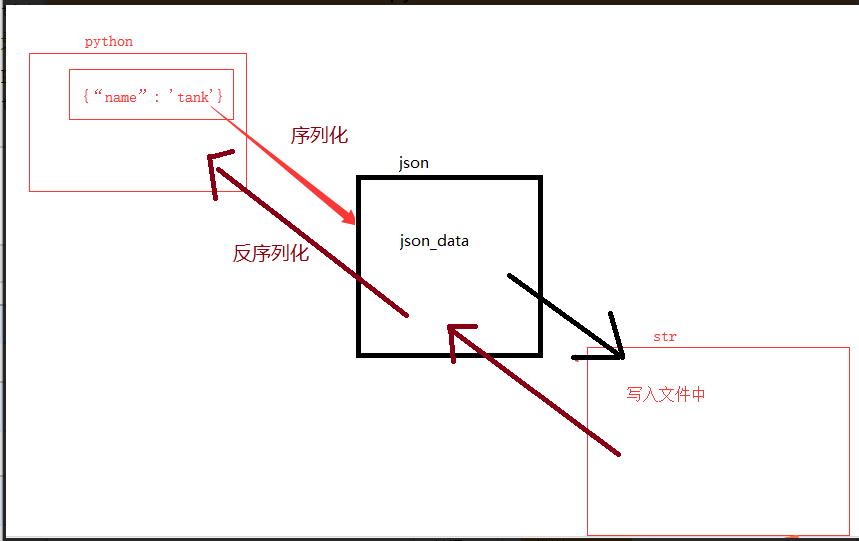
#json模块 # 写入文件的数据需要先将格式转化为字符串,才能写入 # 运行出来的数据可以存入jason文件中,也可以存入数据库中 # dumps 序列化 # json.dump()的运行过程是: # 把字典转化成json数据 # 再把json数据转化成字符串,此时才能将数据存入文件中 import json user_info = { 'name':'tank', 'pwd':'123' } res = json.dumps(user_info) print(res) print(type(res)) with open ('user.json','wt',encoding='utf-8')as f: f.write(res) # loads:反序列化 # json.loads() # 把json文件的数据读到内存中 with open ('user.json','r',encoding='utf-8')as f: res=f.read() user_dict=json.loads(res) print(user_dict) print(type(user_dict)) # dump # dump 自带write功能 user_info ={ 'name': 'tank', 'pwd': '123' } # !!!!转化格式 with open('user_info.json', 'w', encoding='utf-8')as f: json.dump(user_info, f) #load with open('user_info.json', 'r', encoding='utf-8')as f: user_dict=json.load(f) print(user_dict)
(3)模块与包
模块
引用:模块,在Python可理解为对应于一个文件。在创建了一个脚本文件后,定义了某些函数和变量。你在其他需要这些功能的文件中,导入这模块,就可重用这些函数和变量。
一般用module_name.fun_name,和module_name.var_name进行使用。这样的语义用法使模块看起来很像类或者名字空间,可将module_name 理解为名字限定符。模块名就是文件名去掉.py后缀。
模块属性__name__,它的值由Python解释器设定。如果脚本文件是作为主程序调用,其值就设为__main__,如果是作为模块被其他文件导入,它的值就是其文件名。
每个模块都有自己的私有符号表,所有定义在模块里面的函数把它当做全局符号表使用。模块可以导入其他的模块。通常将import语句放在模块的开头,被导入的模块名字放在导入它的模块的符号表中。
包
引用:通常包总是一个目录,可以使用import导入包,或者from + import来导入包中的部分模块。包目录下为首的一个文件便是 __init__.py。然后是一些模块文件和子目录,假如子目录中也有 __init__.py 那么它就是这个包的子包了。
在创建许许多多模块后,我们可能希望将某些功能相近的文件组织在同一文件夹下,这里就需要运用包的概念了。包对应于文件夹,使用包的方式跟模块也类似,唯一需要注意的是,当文件夹当作包使用时,文件夹需要包含__init__.py文件,主要是为了避免将文件夹名当作普通的字符串。__init__.py的内容可以为空,一般用来进行包的某些初始化工作或者设置__all__值,__all__是在from package-name import *这语句使用的,全部导出定义过的模块。
# import 模块名 # 放很多文件的及文件夹的名字 import B # from # 导入B模块的a文件 from B import a
a文件中函数如下:
模块属性__name__,它的值由Python解释器设定。如果脚本文件是作为主程序调用,其值就设为__main__,如果是作为模块被其他文件导入,它的值就是其文件名。注意以下写法很重要!!!
print('a') def func1(): print('kkkkkk') print(__name__) # 一般来说,测试某个功能的函数写法 # 都是如下的,这样做的目的是避免 # 其他函数调用该模块时会直接执行里面的函数体 if __name__=='__main__': func1()
