JavaScript js调用堆栈(二)
本文主要介绍JavaScript的内存空间

var a = 20; var b = 'abc'; var c = true; var d = { m: 20 }
首先需要对栈(stack),堆(heap),与队列(queue)有一定的了解:
- 栈(stack)
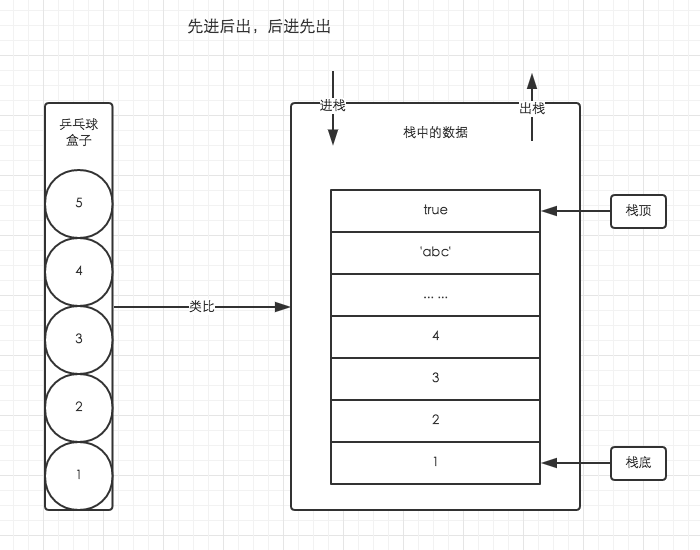
-
堆数据结构
堆数据结构是一种树状结构。它的存取数据的方式,则与书架与书非常相似。
书虽然也整齐的存放在书架上,但是我们只要知道书的名字,我们就可以很方便的取出我们想要的书,而不用像从乒乓球盒子里取乒乓一样,非得将上面的所有乒乓球拿出来才能取到中间的某一个乒乓球。好比在JSON格式的数据中,我们存储的key-value是可以无序的,因为顺序的不同并不影响我们的使用,我们只需要关心书的名字
-
队列
在JavaScript中,理解队列数据结构的目的主要是为了清晰的明白事件循环(Event Loop)的机制到底是怎么回事。
队列是一种先进先出(FIFO)的数据结构。正如排队过安检一样,排在队伍前面的人一定是最先过检的人。用以下的图示可以清楚的理解队列的原理。

变量对象与基础数据类型:
JavaScript的执行上下文生成之后,会创建一个叫做变量对象的特殊对象(上一篇已总结),JavaScript的基础数据类型往往都会保存在变量对象中,即保存在栈内存中,因为这些类型在内存中分别占有固定大小的空间,通过按值来访问。
JavaScript中有5种基础数据类型,分别是Undefined、Null、Boolean、Number、String、Symbol。基础数据类型都是按值访问,因为我们可以直接操作保存在变量中的实际的值。引用数据类型与堆内存:
我们可以结合以下例子与图解进行理解:
var a1 = 0; // 变量对象 var a2 = 'this is string'; // 变量对象 var a3 = null; // 变量对象 var b = { m: 20 }; // 变量b存在于变量对象中,{m: 20} 作为对象存在于堆内存中 var c = [1, 2, 3]; // 变量c存在于变量对象中,[1, 2, 3] 作为对象存在于堆内存中

因此当我们要访问堆内存中的引用数据类型时,实际上我们首先是从变量对象中获取了该对象的地址引用(或者地址指针),然后再从堆内存中取得我们需要的数据。
在计算机的数据结构中,栈比堆的运算速度快,Object是一个复杂的结构且可以扩展:数组可扩充,对象可添加属性,都可以增删改查。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。所以查找引用类型值的时候先去栈查找再去堆查找。对于这种,我们把它叫做按引用访问。
几个问题
var a = 20; var b = a; b = 30; // 这时a的值是多少?
var m = { a: 10, b: 20 } var n = m; n.a = 15; // 这时m.a的值是多少
var m = { a: 10, b: 20 } var n = m; m= null; // 这时n的值是多少
这三个问题的答案分别是:20, 15, { a: 10, b: 20 }
- 问题一:a、b都是基本数据类型,它们的值是存储在栈中的,a、b分别有各自独立的栈空间,所以修改了b的值以后,a的值并不会发生变化。
- 问题二:m、n都是引用类型,栈内存中存放地址指向堆内存中的对象,引用类型的复制会为新的变量自动分配一个新的值保存在变量对象中,但只是引用类型的一个地址指针而已,实际指向的是同一个对象,所以修改
n.a的值后,相应的m.a也就发生了改变。 - 问题三:首先要说明的是
null是基本类型,m = null之后只是把m存储在栈内存中地址改变成了基本类型null,并不会影响堆内存中的对象,所以n的值不受影响。
JavaScript的内存生命周期
- 分配你所需要的内存
- 使用分配到的内存(读,写)
- 不需要时将其释放,归还
为了便于理解,我们使用一个简单的例子来解释这个周期。
var a = 20; // 在内存中给数值变量分配空间 alert(a + 100); // 使用内存 a = null; // 使用完毕之后,释放内存空间
第一步和第二步我们都很好理解,JavaScript在定义变量时就完成了内存分配。第三步释放内存空间则是我们需要重点理解的一个点。
JavaScript有自动垃圾收集机制,那么这个自动垃圾收集机制的原理是什么呢?其实很简单,就是找出那些不再继续使用的值,然后释放其占用的内存。垃圾收集器会每隔固定的时间段就执行一次释放操作。
a = null其实仅仅只是做了一个释放引用的操作,让 a 原本对应的值失去引用,脱离执行环境,这个值会在下一次垃圾收集器执行操作时被找到并释放。而在适当的时候解除引用,是为页面获得更好性能的一个重要方式。
在局部作用域中,当函数执行完毕,局部变量也就没有存在的必要了,因此垃圾收集器很容易做出判断并回收。但是全局变量什么时候需要自动释放内存空间则很难判断,因此在我们的开发中,需要尽量避免使用全局变量。
附:

1、标记清除法:
JavaScript最常用的垃圾收集方式。当变量进入环境时,这个变量标记为“进入环境”;而当变量离开环境时,则将其标记为“离开环境”。可以使用一个“进入环境”的变量列表及一个“离开环境”的变量列表来跟踪变量的变化,也可以翻转某个特殊的位来记录一个变量何时进入环境及离开环境。
2、引用计数法:
不太常见的垃圾收集策略。引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型值赋给该变量时,则该值的引用次数就是1;如果同一个值又被赋给另一个变量,则该值的引用次数加1;如果包含对该值引用的变量又取得了另外一个值,则该值的引用次数减1。当该值的引用次数变为0时,则可以回收其占用的内存空间。当垃圾回收器下一次运行时,就会释放那些引用次数为0的值所占用的内存。
参考:
https://www.jianshu.com/p/996671d4dcc4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号