Spark on Yarn with HA
Spark 可以放到yarn上面去跑,这个毫无疑问。当Yarn做了HA的时候,网上会告诉你基本Spark测不需做太多的关注修改,实际不然。
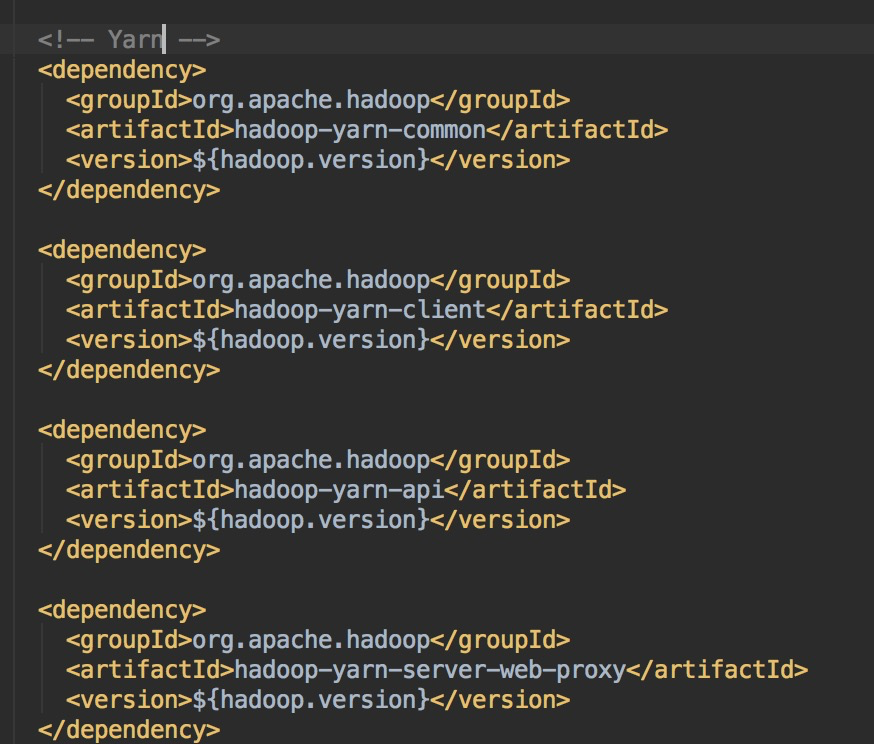
除了像spark.yarn开头的相关配置外,其中一个很重要的坑是spark-yarn依赖包的Hadoop版本问题。Spark1.6.x的spark-yarn默认的Hadoop是2.2.0,而现在大部分的Hadoop2应该都升到了2.6或2.7,在没做HA的时候,这部分yarn api是兼容的,然而yarn做了HA后,依赖旧版本的yarn api不会去自己找 yarn.resourcemanager.hostname.xx 这样的ha配置,而是只会找yarn.resourcemanager.hostname ,导致无法适应Yarn RM的HA切换。
如果hostname是standby,则会一直Connecting to ResourceManager 然后Retrying connect to server 很多次,一直卡着。

实际处理也很简单从spark-yarn中exclude掉yarn相关的依赖,在pom.xml外层手动依赖对应Hadoop版本的yarn组件即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号