
浅析REGEXP_SUBSTR,PRIOR,CONNECT BY
业务场景
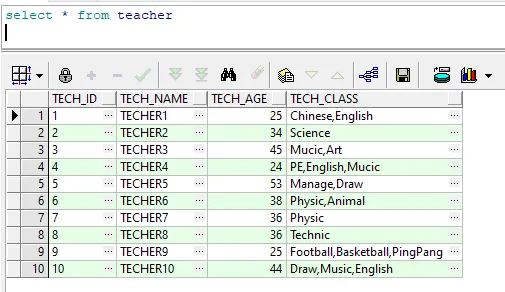
teacher表中的tech_class字段存储的是每个老师所教授的课程,课程之间以英文逗号分隔。现在要用语句统计每个课程对应的教师数量。语句及效果如下:

语句其实很简单,各种博客或者gpt都有不错且可行的解决方案,我们主要来理解下这段语句的执行原理,更好的学习。
part1 REGEXP_SUBSTR
具体语法这里不再赘叙,我们从单个例子入手看看效果:
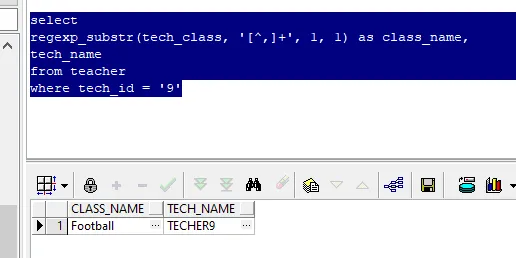
REGEXP_SUBSTR可以将字段字符串根据所给正则表达式匹配并拆分(注意不是分割,但效果上等同于分割)。
最后一个参数代表要取出第几个匹配的结果:

那为什么这里要使用LEVEL?LEVEL是什么?
关于LEVEL的官方解释 具体如图:

使用之前要注意,官方文档里有句话:
To define a hierarchical relationship in a query, you must use the CONNECT BY clause.
所以关于connect by,你可以先往后看。
使用LEVEL后的效果:
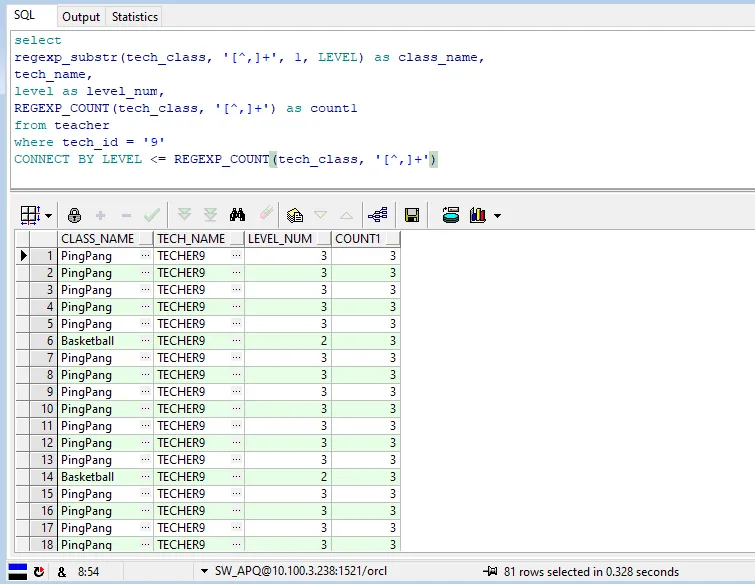
LEVEL是一个在CONNECT BY子句中使用的伪列,它代表当前递归层次的级别。在每次递归调用中,LEVEL的值会增加1。在这个例子中,LEVEL的值会从1开始,一直到tech_class中逗号分隔的子串的数量——3。
为什么这样会有81条?我们的预期结果其实是3条。让我们继续探究......
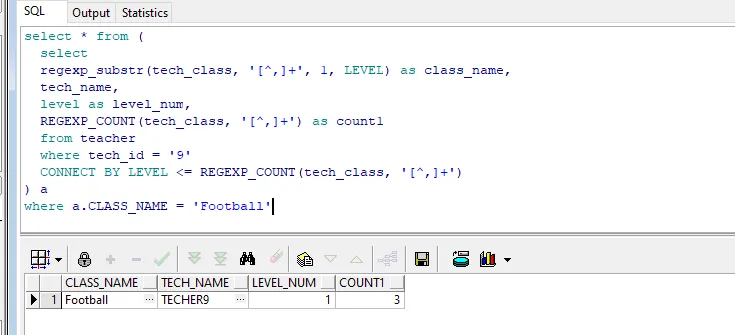
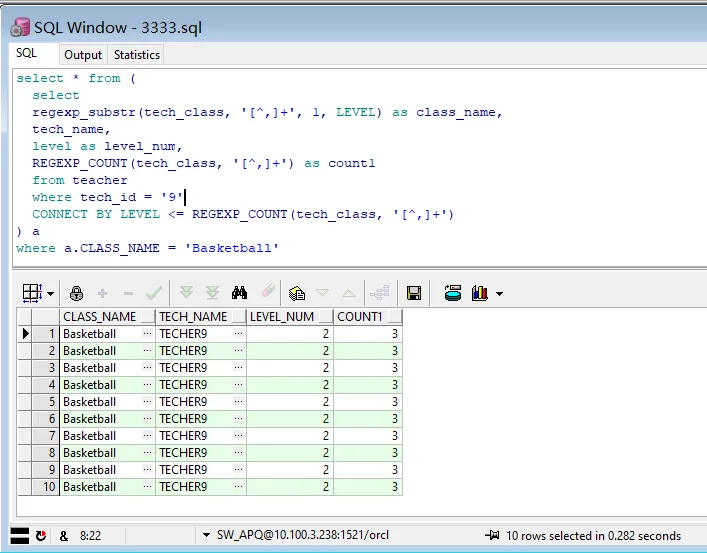

Football是字段里的第一个值,只有1条;Basketball是字段里的第二个值,有10条;PingPang是字段里的第三个值,有70条!貌似越往后数据重复越多,而且次数增长的可怕,但很难发现出有什么规律。检索后基本确定出现重复数据是因为在递归过程中,regexp_substr函数没有正确移动到下一个匹配项,而是重复移动到了Basketball或者PingPang,至于它底层是什么重复移动的,额我也没搞明白....。
对此我们需要添加prior确保每次递归时都能正确提取。
part3 prior
关于prior的简单介绍
connect by中加prior可以限定父子的对应关系,限定递归路径。这里对同条记录进行递归:

加sys_guid()是为了保证层次查询,存在循环时,不出现无限递归。它为每行生成一个唯一标识,从而避免无限循环。
Part3 connect by
CONNECT BY的官方文档--分级查询
connect by常常结合prior一起实现父级查询。因此connect by LEVEL prior一般都一起出现。
附
最后再次附上针对原始的业务需求的完整的语句及输出:
select
regexp_substr(tech_class, '[^,]+', 1, LEVEL) as class_name,
tech_name
from teacher
CONNECT BY LEVEL <= REGEXP_COUNT(tech_class, '[^,]+')
and prior tech_class = tech_class
and prior sys_guid() is not null
order by class_name



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 本地部署 DeepSeek:小白也能轻松搞定!
· 传国玉玺易主,ai.com竟然跳转到国产AI
· 自己如何在本地电脑从零搭建DeepSeek!手把手教学,快来看看! (建议收藏)
· 我们是如何解决abp身上的几个痛点
· 如何基于DeepSeek开展AI项目