
微服务架构会面临哪些技术问题?
服务治理和负载均衡
微服务架构广泛应用在超高并发系统中,中后台服务集群的规模着实不小。就拿淘系的下单接口来说,一个下单指令要调用近二十个后台微服务协同完成任务(可能现在更多了),而在双11这类业务场景下,核心链路的一个微服务背后的虚机数量都有近万台。
因此,服务与服务之间的调用,就成了微服务架构需要解决的第一个问题。与此同时,大规模集群中虚机的上线下线是每天的日常任务,集群的扩容缩容也很常见,我们的微服务架构需要探知到集群中各个服务节点的状态变化,这样就知道哪些节点是可以正常提供服务的。我们管这个领域叫做服务治理
与服务治理搭档的还有负载均衡,面对茫茫多的服务器,如何将海量用户请求分发到不同的机器。考虑到有的机器性能比较弱,或者机房带宽不大,网络响应慢,如何根据实际情况动态地分发服务请求?这个领域就是负载均衡需要解决的事情。
熔断降级
若你依赖的服务长时间响应失败或者超时错误次数频增,你是否就要考虑估计你的下游服务生病了,或者处理算力不够了,我们就要像参考电路板熔断器一样,我就不去调用你了,这种机制我们把它叫做“熔断”,基于熔断保护下游,给下游一个喘息的机会,一旦熔断之后我们还要间歇性的去观察下游是否恢复了,因为熔断非常态,正常服务才是我们的诉求,我们还需要提供说我间歇性的访问下你,比如每个2秒钟访问你一次,如果连续三次都没有异常,则判断你已经恢复了,我关闭熔断处理策略。在熔断的过程中我们需要定义一种异常,这种异常比如我们可以用一个特殊的错误码,一种特殊的异常,或者就是一个null的返回,我们对应的服务消费要基于这个错误码做到可降级,比如我们的商品销量获取,如果服务不可用我们就可以展示一个默认的销量,或者隐藏掉销量的展示,不要把系统错误抛给前端。hystrix框架提供给我们和好的服务隔离和熔断机制,结合dubbo的插件式编程方式做很好的融合
服务通信
隔离开系统之后,本来进程内的调用就要改成进程之间的调用了,进程之间的调用最常用的方式就是网络通信,而远程的网络通信调用函数的方式就是RPC(Remote Process Call)远程过程调用,其并非是一个简单的网络通信过程,在java中依靠接口代理的通信机制使用服务消费方在进程内可以像调用本地函数一样去调用服务提供方的代码,其中间层由dubbo的服务代理机制负责搞定。
对,RPC通信框架使得服务调用就这么简单
服务注册及发现,解决了服务通信的网络问题,大家不要忽略了,我的服务消费方怎么知道提供方的ip地址和端口,然后连接上去做服务通信的,dubbo结合zookeeper的注册和发现的通信能力做到了这一点
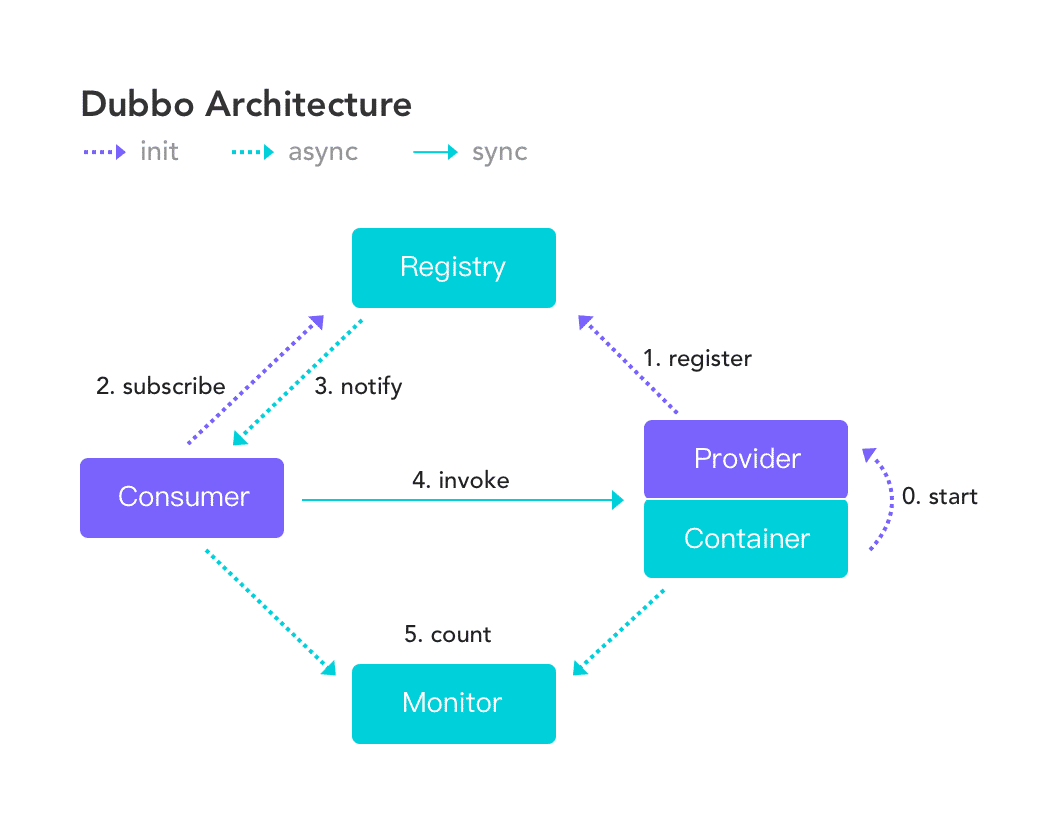
服务提供方启动后将自己的ip,端口及可以提供的demoService的接口签名注册到zookper的注册中心上
服务消费方启动后通过自己的reference服务依赖引用列表从注册中心找到了提供demoService接口签名的接口服务提供方,也就是我们的服务提供方的ip和端口
当consumer要调用对应的demoService服务时通过本地存储的提供方ip和端口连接到provider并进行服务调用后获得返回
当provider产生问题,例如异常退出后,由于和zookeeper注册中心之间的心跳丢失,注册中心判定provider死亡会主动通知关注demoService的服务消费方consumer,consumer于是就将对应的provider ip和端口及连接提出
发送方和接收方定义将服务调用量发送给monitor监控器做服务健康监控负载均衡
在上图服务注册和发现中其实我们的provider和consumer在分布式环境下是多台的,因此我们的consumer可以通过注册中心拿到一批provider的ip和端口,当发生服务调用时可以在本地存储的provider列表上做负载均衡策略,比如可以轮训或随机的取下一次调用的provider的连接,由于上述第4步的存在,若某台provider故障则consumer会立马通过注册中心感知到并将provider踢出对应的列表,当provider恢复后又会到注册中心注册,consumer又可以得到通过将provider加回。
服务容错
地盘大了难免杂事不断,集群中难免有那么几台机器跑着跑着就慷慨就义了。那么对于其它的服务调用者来说,如果不巧正好调用到了这些挂掉的机器,那自然会获得到失败的Response。面对这种情况,后台服务可有另一条路走?
在高并发场景下,有的服务会承担较大的访问请求,这有可能导致响应时间过慢,甚至会响应超时。那调用方在超时后经常会发起重试,这样会进一步增加下游应用的访问压力,进而导致一个恶性循环。那么面对这种情况,我们有解决方案吗?
以上就是微服务领域中降级和熔断技术需要解决的问题,我们管这些叫做服务容错。
配置管理
大家平时在项目中都怎么管理配置项呢?使用配置文件?如果我有一个业务场景,需要随时调整配置,这种配置文件的管理方式可能就玩不转了,我们总不能每次改配置的时候都要重启机器吧。
那么把配置项存到数据库里?可以倒是可以,但是访问量增加的时候也会将压力传导到数据库,数据库往往是比较弱不禁风的一环,很可能被压垮。那么放到缓存里?这一定程度上解决了性能问题,不过在某些业务场景下还是不好用,比如我希望给不同服务器配置不同属性值,指定name属性在某100台机器中的值是张三,在剩余机器中的值是李四。
以上问题在微服务领域也不是什么大问题,服务配置管理就是专门解决这类问题的利器。
服务网关
我们的系统对外提供的网络访问入口只有一个,这通常就是一个域名网址。但是这套系统后面的服务器可有千千万,那么在微服务架构下,是如何将用户请求转发到每个不同的服务器上的呢?这就是服务网关需要解决的事情。
前面我们学习过Nginx网关,大家也应该了解了网关的含义,不过在微服务领域里,网关层会更加智能一些,它会感知服务器上下线的变化。欲知微服务网关如何与服务治理搭配使用,且听下回分解。
网关接入系统负责接收对应的web请求,转发给对应后面的业务服务系统处理对应的业务并接收返回转发给前端。后面的业务服务系统各司其职,每个系统只负责自己业务范围内的职责,比如商品系统仅服务商品相关的服务,创建,更新,查询,上下架等整个的生命周期并被购物车系统依赖,服务系统之间的逻辑关系清晰,且不同系统间只能通过对方提供的接口做访问,管理方便,每个系统拥有自己独立部署服务器,拥有自己的存储数据库,故障可隔离,配合日志,消息,监控,配置中心等分部署微服务下的配合组件做到一个可监控,可隔离,又可通信的服务体系。
调用链路追踪
前面提到一个淘系下单场景会调用一连串的微服务,我们YY这么一个线上故障,有个用户买了两只大猪蹄子,结果东西送到家变成了两只鸡爪子。店小二说没发错货啊不信自己看订单,打开一看还真是,下单的时候选的猪蹄子,下单以后就成了鸡爪子。
上面这个问题出在整个下单链路哪个环节呢?是订单中心搞错了商品ID,还是购物车页面传了错误ID给订单系统,或者说搜索页面一键下单功能没取到正确的ID?迷雾迷雾在迷雾,怎么拨开迷雾见真相?
调用链追踪,从前到后整个调用链路全景数据展现,用事实说话,从此甩锅更加精准!
消息驱动
消息驱动是老朋友了,相信大家在项目中也经常使用消息中间件。我们试想这样一个场景,双11当天24点0分0秒一过,数万万的败家亲们一拥而上,下单接口调用量飙升,就快到了崩溃边缘。那我们后台的订单服务如何才能顶住这一波波攻势?亲,消息驱动组件加上限流组件来做削峰填谷了解一下?
不仅如此,微服务各个系统之间的解耦也可以用消息组件来实现。其实消息驱动在微服务里的实现也就是多做了几层抽象,调用起来更加方便,个中滋味还请同学们亲身体验。
限流
再厉害的系统也有性能瓶颈,强如阿里打造的双十一也抵不住全国剁手族齐上阵,限流是最经济高效,在源头处消减系统压力的手段。微服务的后台服务节点数量庞大,单机版限流远不能解决问题,我们需要在服务器集群这个范围内引入分布式限流手段。
监控
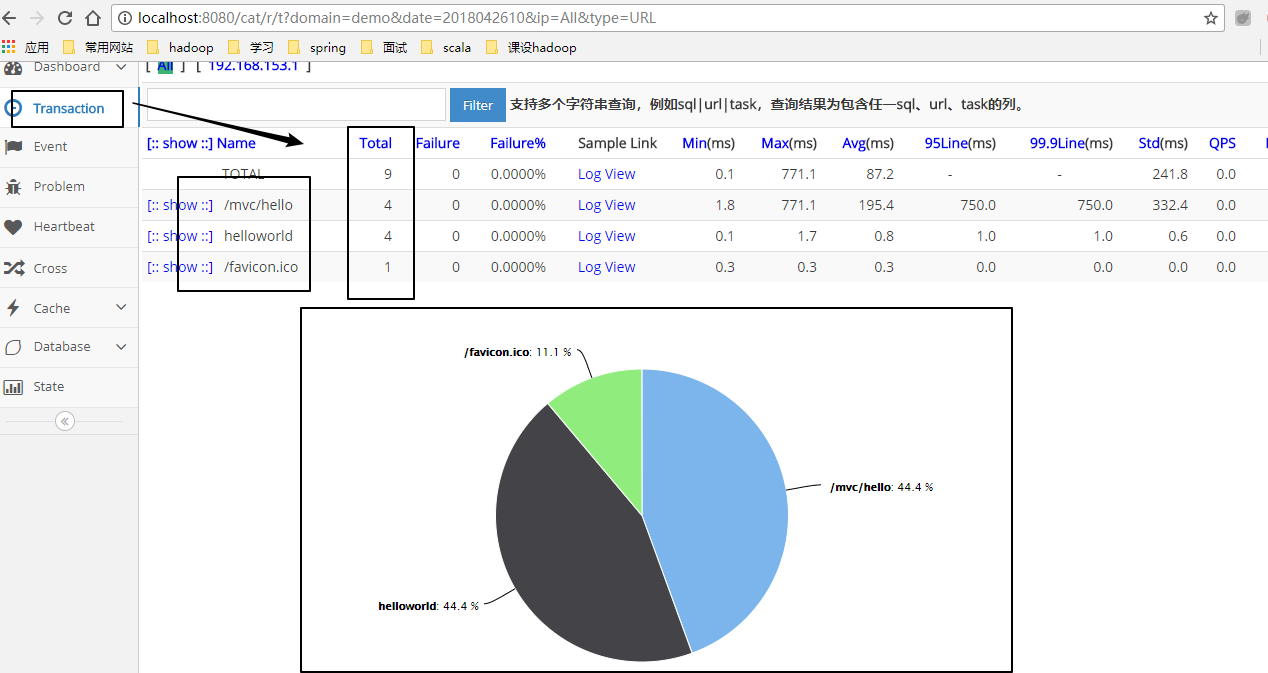
我们需要一套监控体系配合我们的微服务健康度检查,在出现问题的时候可以快速定位问题,甚至于做到提前发现问题,防患于未然,dubbo自身的monitor并不能提供给我们太好的支持,在这里我建议大家看一下点评开源的cat监控组件,结合dubbo的插件式编程方式,将每一个服务调用以打点的方式打到cat上,并提供给我们一种可视化的监控展现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号