

缓存一致性如何保障
缓存在现代应用程序中被广泛使用,用于提高性能和降低对后端数据存储系统的负载。然而,使用缓存也带来了一个重要问题:缓存一致性。在分布式系统中,缓存一致性成为了一个挑战,因为我们需要确保缓存中的数据与后端数据存储系统的数据保持同步,以避免数据不一致的情况发生。
Cache Aside Pattern(先写库再删缓存)
Cache Aside Pattern 是一种常见的缓存设计模式,用于在应用程序中有效地利用缓存来提高性能和降低对后端数据存储系统的负载。该模式的核心思想是将缓存视为数据检索的副本,并在需要访问数据时先查询缓存。如果缓存中存在所需数据,则直接从缓存中获取;如果缓存中不存在所需数据,则从后端数据存储系统(如数据库)中获取,并将数据添加到缓存中以供下次使用。
读取数据时:
- 应用程序首先查询缓存,检查所需数据是否已经存在于缓存中。
- 如果缓存中存在数据,则直接返回缓存中的数据。
- 如果缓存中不存在数据,则从后端数据存储系统中获取数据,并将数据添加到缓存中,以便下次访问时能够直接从缓存中获取。
写入/更新数据时:
- 应用程序首先更新后端数据存储系统中的数据。
- 然后,应用程序使缓存中与被更新数据相关的缓存项失效,以保持缓存中的数据与后端数据存储系统的一致性。
更新缓存时,不使用更新,而是删除
删除缓存:在数据更新完成后,即刻删除对应的缓存项。这样做是为了确保下一次使用该数据时,会从后端数据存储系统读取最新的数据而不是过期的缓存值。

为什么不可以先更新缓存,再更新库
并发操作导致数据不一致:假设有多个同时请求需要修改同一个数据项,如果先删除缓存再写数据库,可能会导致并发操作之间的数据不一致。这是因为在删除缓存的时间窗口内,其他请求可能会读取到旧的缓存值,而不是最新的数据库值。
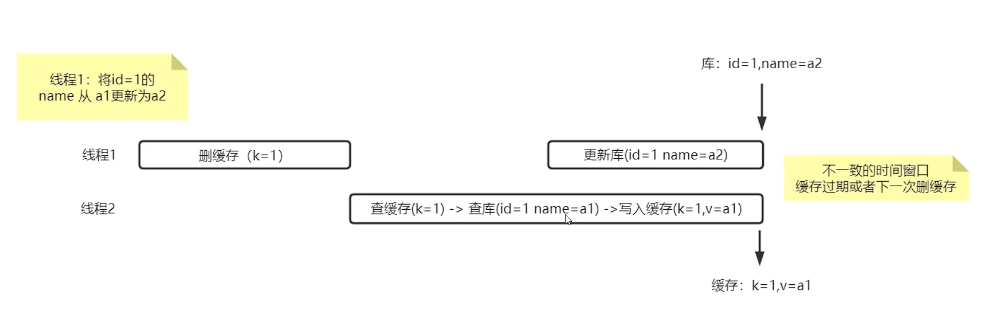
应该先更新库,再更新缓存
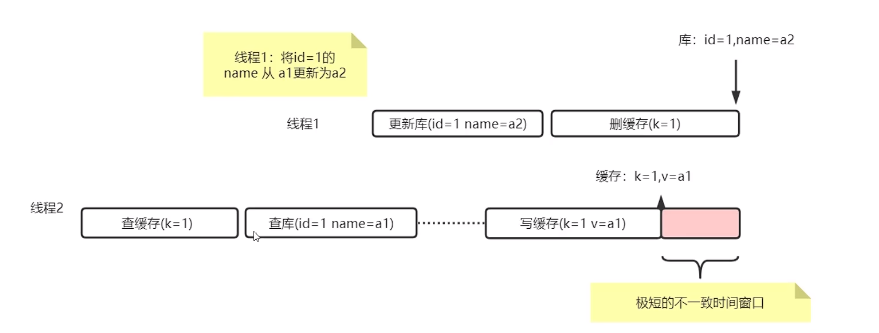
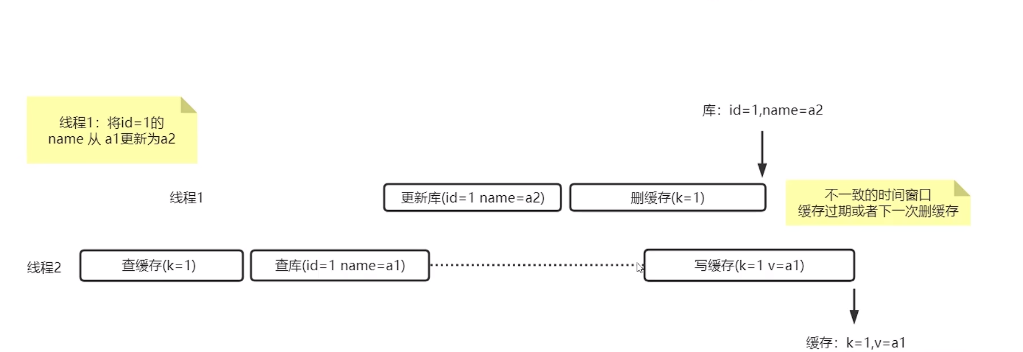
就算先更新库,再更新缓存,还是会有极端情况出现导致不一致
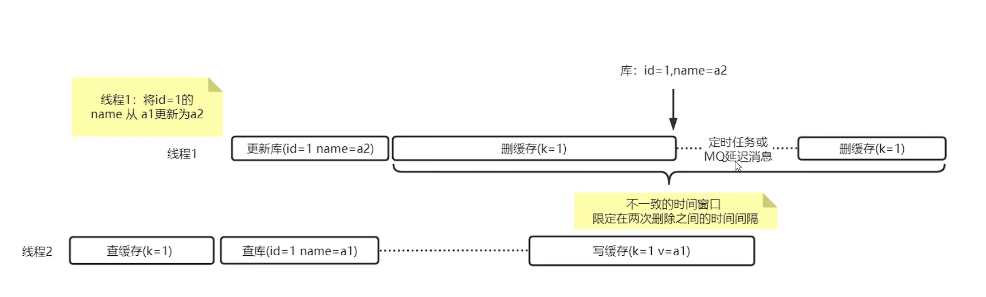
解决方案,延迟双删
最后总结
- 要保证缓存与数据库强一致,最好的办法是分布式锁,但那样并发性能就完蛋。
- Cache Aside Pattern + 延迟双删无锁方案只能在保证并发的前提下尽可能减少不一致的可能。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY