
SIMD---SSE系列及效率对比
SSE(即Streaming SIMD Extension),是对由MMX指令集引进的SIMD模型的扩展。我们知道MMX有两个明显的缺点:
- 只能操作整数。
- 不能与浮点数同时运行(MMX使用FPU寄存器作为别名)。
而SSE则解决了这个问题,SSE引进了8个专用的浮点寄存器MMX0~MMX7。后来Intel又陆续推出了SSE2、SSE3、SSE4,这使得SSE指令系列同时拥有了浮点数学运算功能和整数运算功能,因此早先的MMX指令就显得有点多余了(虽然可是并行执行SSE、MMX指令来提高性能)。
SSE系列功能特点
SSE1
- 添加8个128位寄存器XMM0~MMX7.
- 操作4个单精度浮点数。
- 支持打包(Packed)和标量(Scaler)操作。
SSE2
- 添加整数向量运算,提升运行性能。
- 支持双精度浮点向量运算。
- 打包类型取消限制,支持8位、16位、32位、64位,包括整数和浮点数。
- 添加缓存控制指令。
- 添加浮点数到整数的转换指令
SSE3
- 寄存器内水平操作,例如打包在一个128位MMX寄存器内的2个64位整数,可以利用新指令对这两个整数进行算数运算。
- 多线程优化指令,在超线程下提高性能。
SSSE3
- 打包整形数据的运算加速。
SSE4
SSE4包含两个子集:SSE4.1和SSE4.2,并兼容以前的64位和IA-32指令集架构。值得指出的是SSE4增加了:1)STTNI(String and Text New Instructions)指令来帮助开发者处理字符搜索和比较,旨在加速对XML文件的解析;2)CRC32指令,帮助计算循环冗余校验值。
SSE效率对比
这里我们就只简单比较下这两个指令集的计算效率,其他功能就不在本次考虑范围内了。像前一篇博客一样,我们同样用对10000000个字符进行加操作来进行对比操作。这里我们全部用Intrinsics来对比,方便编写,不用考虑调用约定。
整数计算 Mmx vs Sse
因为整数操作只在SSE2中支持,所以实际上我们用的是sse2指令。
mmx代码:
void calculateUsingMmx(char* data, unsigned size)
{
assert(size % 8 == 0);
__m64 step = _mm_set_pi8(10, 10, 10, 10, 10, 10, 10, 10);
__m64* dst = reinterpret_cast<__m64*>(data);
for (unsigned i = 0; i < size; i += 8)
{
auto sum = _mm_adds_pi8(step, *dst);
*dst++ = sum;
}
_mm_empty();
}
sse代码:
void calculateUsingSseInt(char* data, unsigned size)
{
assert(size % 16 == 0);
__m128i step = _mm_set_epi8(10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10);
__m128i* dst = reinterpret_cast<__m128i*>(data);
for (unsigned i = 0; i < size; i += 16)
{
auto sum = _mm_add_epi8(step, *dst);
*dst++ = sum;
}
// no need to clear flags like mmx because SSE and FPU can be used at the same time.
}
浮点计算 Asm vs Sse
由于MMX指令集不包含浮点指令,因此我们x86浮点指令来对比,同样对10000000个flaot值进行加操作。
Asm代码:
void calculateUsingAsmFloat(float* data, unsigned count)
{
auto singleFloatBytes = sizeof(float);
auto step = 10.0;
__asm
{
push ecx
push edx
mov edx, data
mov ecx, count
fld step // fld only accept FPU or Memory
calcLoop:
fld [edx]
fadd st(0), st(1)
fstp [edx]
add edx, singleFloatBytes
dec ecx
jnz calcLoop
pop edx
pop ecx
}
}
Sse代码:
void calculateUsingSseFloat(float* data, unsigned count)
{
assert(count % 4 == 0);
assert(sizeof(float) == 4);
__m128 step = _mm_set_ps(10.0, 10.0, 10.0, 10.0);
__m128* dst = reinterpret_cast<__m128*>(data);
for (unsigned i = 0; i < count; i += 4)
{
__m128 sum = _mm_add_ps(step, *dst);
*dst++ = sum;
}
}
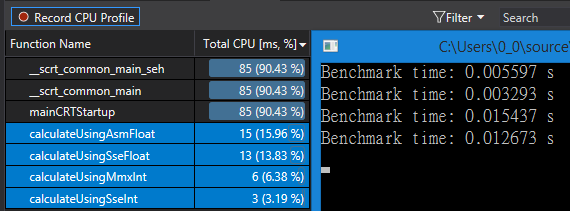
运行结果
SSE2的浮点计算对比x86浮点计算性能提升不是非常明显,但是也要考虑Intrinsics使用导致的略微性能缺失。上面两种计算方式的效率对比结果如下:
完整代码见链接。

