

一文彻底弄懂并解决Redis的缓存雪崩,缓存击穿,缓存穿透
缓存雪崩、缓存击穿、缓存穿透是分布式系统中使用缓存时,常遇到的三类问题,都会对系统性能和稳定性产生严重影响。下面将详细介绍这三者的定义、产生原因、危害以及常见的解决方案。
1. 缓存雪崩
1.1 定义
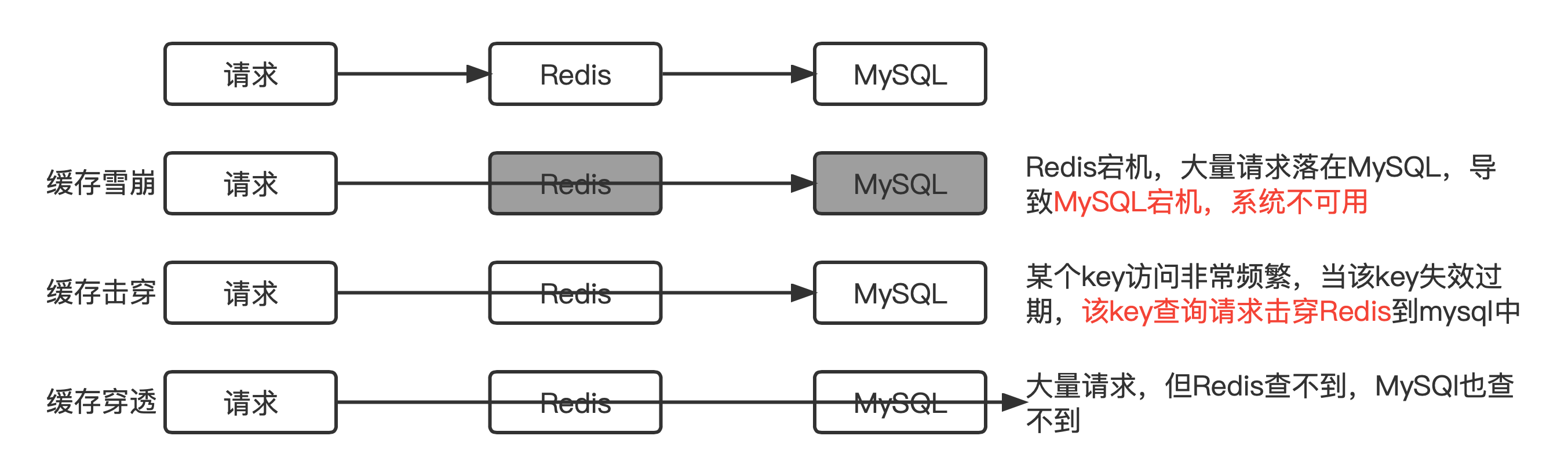
缓存雪崩是指在某一时刻,大量缓存同时失效,导致大量请求直接打到数据库层,造成数据库压力骤增,甚至可能导致数据库崩溃、系统不可用的情况。
1.2 产生原因
- 缓存集中失效:通常情况下,缓存的失效时间(TTL)是设置好的,但如果大量缓存键设定了相同或接近的过期时间点,那么在这些缓存集中失效时,会造成大量的请求无法从缓存中读取数据,只能直接访问数据库。
- 缓存服务器宕机:如果 Redis 服务器集群出现宕机或故障,那么所有缓存数据会瞬间不可用,大量请求直接涌向数据库。
1.3 危害
- 数据库压力激增:大量并发请求瞬间打到数据库,可能造成数据库连接数耗尽、性能下降,甚至宕机。
- 服务不可用:由于数据库无法及时响应请求,系统整体响应速度变慢或完全失去响应,导致服务不可用。
1.4 解决方案
-
缓存过期时间分散化:
- 可以为不同的缓存键设置不同的失效时间(TTL),使得缓存的过期时间均匀分布,避免大量缓存同时失效。例如,在设定 TTL 时,加上一个随机值,避免缓存键在同一时间失效。
// 设置缓存时,加一个随机时间,防止集中过期 int randomTTL = ttl + new Random().nextInt(100); redisTemplate.opsForValue().set(key, value, randomTTL, TimeUnit.SECONDS); -
缓存预热:
- 在系统上线前,提前将热点数据加载到缓存中,避免大量请求同时触发缓存未命中的情况。
-
降级策略:
- 在缓存雪崩时,可以采取限流、降级等策略,减缓数据库的压力。如在缓存失效时,直接返回默认值或缓存过期的旧数据,避免数据库短时间内处理大量请求。
-
多级缓存架构:
- 使用本地缓存(如 Caffeine、Guava 等)和分布式缓存(如 Redis)相结合的方式,部分热点数据可以先放入本地缓存,降低 Redis 和数据库的压力。
-
Redis 高可用:
- 部署 Redis 主从集群,使用 Redis 的哨兵模式(Sentinel)或者 Redis Cluster 来实现高可用,避免缓存服务器单点故障。
2. 缓存击穿
2.1 定义
缓存击穿是指缓存中存储的某个热点数据在某一时刻失效,大量并发请求同时去访问这个热点数据,导致所有请求打到数据库,造成数据库压力骤增的情况。
2.2 产生原因
- 热点缓存失效:当某个热点数据的缓存过期时,大量请求涌入到数据库层,而此时数据库需要处理所有的请求,造成数据库的瞬时压力增大。
2.3 危害
- 数据库压力过大:由于热点数据失效,导致瞬间的大量请求直接打到数据库,增加数据库的压力,可能会引发数据库连接耗尽、响应变慢等问题,严重时可能导致数据库宕机。
2.4 解决方案
-
热点数据永不过期:
- 对于特别重要的热点数据,可以考虑不设置缓存过期时间,让这些数据一直保存在缓存中。可以通过定时任务手动更新缓存中的数据来避免数据过期问题。
-
互斥锁(Mutex)机制:
- 为了解决在缓存失效瞬间,大量请求同时访问数据库的问题,可以通过加锁机制,保证同一时刻只有一个线程能访问数据库。其他线程需要等待该线程将新数据写入缓存后,再读取缓存。
String value = redisTemplate.opsForValue().get(key); if (value == null) { // 获取分布式锁 if (redisTemplate.opsForValue().setIfAbsent(lockKey, "lock", 10, TimeUnit.SECONDS)) { try { // Double-check value = redisTemplate.opsForValue().get(key); if (value == null) { // 查询数据库 value = database.get(key); // 将结果写入缓存 redisTemplate.opsForValue().set(key, value, ttl, TimeUnit.SECONDS); } } finally { // 释放锁 redisTemplate.delete(lockKey); } } else { // 等待锁释放后,再从缓存中读取数据 Thread.sleep(100); // 自行调整等待时间 value = redisTemplate.opsForValue().get(key); } } -
预防性缓存更新:
- 在热点数据即将过期时,提前异步刷新缓存。通过检测热点数据的访问频率,当即将过期时触发自动更新操作,避免过期瞬间的击穿问题。
-
双缓存机制:
- 可以采用双层缓存策略:一个主要缓存层负责缓存大部分数据,另一个次缓存层保存上次的缓存数据。在主要缓存失效时,可以直接从次缓存层读取数据,避免直接打到数据库。
3. 缓存穿透
3.1 定义
缓存穿透是指恶意用户或程序请求查询的数据在缓存和数据库中都不存在,导致每次请求都会直接打到数据库,绕过缓存。由于缓存没有存储该请求的结果,所有这类请求都会绕过缓存,直接访问数据库,从而导致数据库承受巨大的压力。
3.2 产生原因
- 恶意攻击:有意构造大量不存在的数据请求,如查询不存在的用户 ID 或商品 ID,缓存中没有这些数据,因此直接请求数据库。
- 查询不存在的键:一些业务逻辑上无法避免查询不存在的数据,例如用户查询某些过时或错误的请求参数,数据库中也没有相应的记录。
3.3 危害
- 数据库性能下降:由于查询的数据既不在缓存中,也不在数据库中,因此每次请求都会直接打到数据库,造成数据库压力增大,甚至引发性能瓶颈。
3.4 解决方案
-
缓存空结果:
- 如果查询的某个键在数据库中不存在,则将该键的查询结果(如
null或空值)缓存起来,并设定一个较短的过期时间,防止该键反复查询打到数据库。
// 查询缓存 String value = redisTemplate.opsForValue().get(key); if (value == null) { // 查询数据库 value = database.get(key); if (value == null) { // 缓存空结果,避免缓存穿透 redisTemplate.opsForValue().set(key, "null", 5, TimeUnit.MINUTES); } else { // 将数据库中的值写入缓存 redisTemplate.opsForValue().set(key, value, ttl, TimeUnit.SECONDS); } } - 如果查询的某个键在数据库中不存在,则将该键的查询结果(如
-
布隆过滤器(Bloom Filter):
- 使用布隆过滤器对所有可能存在的数据进行标记,所有请求先经过布隆过滤器进行校验,只有布隆过滤器认为存在的数据,才会去查询缓存或数据库。这样可以有效拦截掉绝大多数不存在的请求,防止这些请求绕过缓存直接打到数据库。
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 100000); // 将所有可能的合法键加入布隆过滤器 bloomFilter.put("validKey1"); bloomFilter.put("validKey2"); // 查询时先校验布隆过滤器 if (!bloomFilter.mightContain(key)) { return "Invalid Key"; } // 正常查询缓存和数据库 -
参数校验:
- 在查询请求进入系统前,进行严格的参数校验和过滤,避免不合法的请求进入系统。例如用户 ID 或商品 ID 是否符合格式要求,避免恶意构造的非法请求直接打到数据库。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!