
爬虫笔记(四)--基于bs4
爬取https://www.shicimingju.com 诗词名句网站中,《三国演义》全部内容。基于bs4,而不是正则。bs4相对于正则简单一些,但是正则更加精准。准确的说是基于bs4中的beautifulsoup。
同样操作步骤:导入包requests和bs4
headers--UA伪装
text是返回的信息,也就是url中的原码。
可以print测试一下,和网页源码内容一样的,下边就需要对网页源码内容分析。
import requests import bs4 if __name__ == '__main__': headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36' } url = 'https://www.shicimingju.com/book/sanguoyanyi.html' text = requests.get(url = url,headers = headers).text
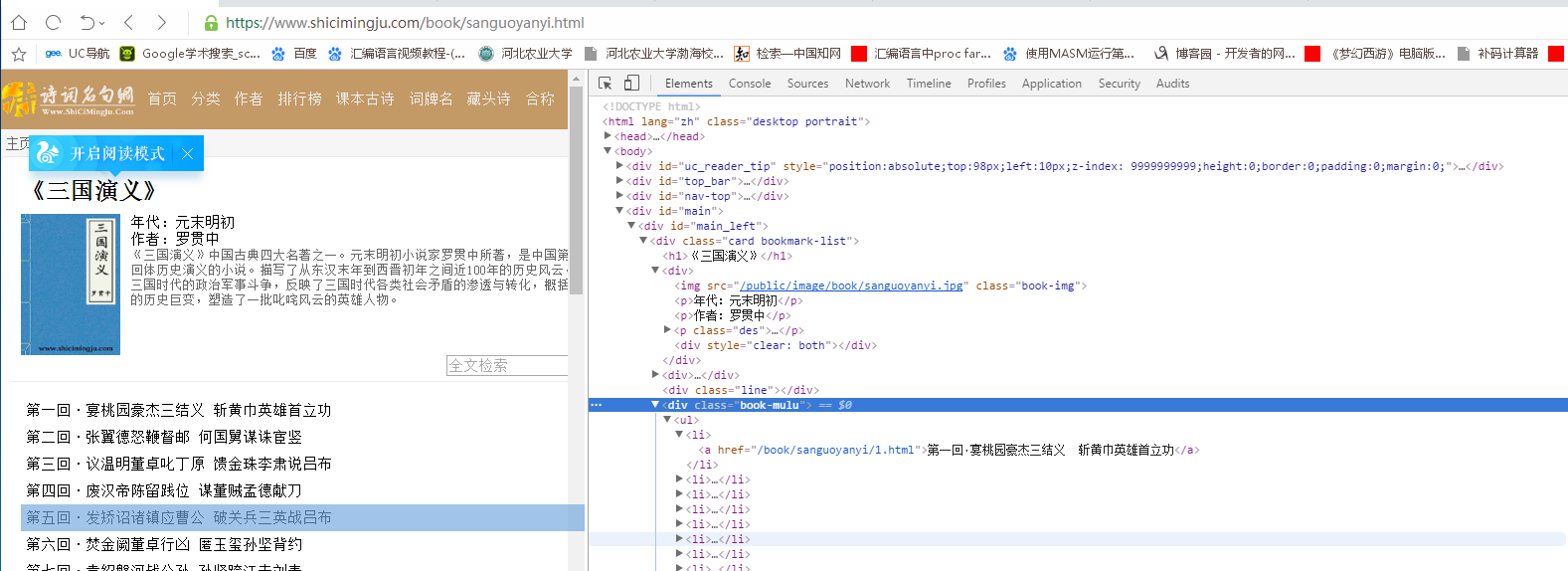
所有节目录的title和url都在同一个标签中, div class=“book-mulu” -----> ul -----> li,具体的章节title和url在 li-----> a 中。
所以下一步应该把所有的url和title都获取到。
很明显,可以用正则,但是为了练习bs4,选择bs4。
通过beautifulsoup实例化对象soup,beautifulsoup参数第一个是要分析的字符串,可以来自本地,可以来自requests。第二个是解释器,常用‘lxml’。
为了筛选网页源码中的需要内容,使用soup的select方法。select方法是选择器,可以通过标签、ID、类(class内容)、层选择,详细可以参考:https://blog.csdn.net/weixin_43037607/article/details/92703849
我选择通过类查找,定位到需要内容的上上级标签,再通过“>” 逐级向下查找,找到li层。也可以选择".book-mulu li",表示跨层,不逐级跃层。
最后soup.select,返回是一个list,这个很重要。
soup = bs4.BeautifulSoup(text,'lxml') list = soup.select(".book-mulu > ul > li") #".book-mulu li" 空格表示跨层
第一次选择的是通过soup.findall()寻找 li标签,写法就是soup.findall(name = 'li'),发现返回的是list,list中除了需要的内容,还有其他没用的li标签,还需要再次筛选,所以放弃。
打印一下list前5个元素:
<li><a href="/book/sanguoyanyi/1.html">第一回·宴桃园豪杰三结义 斩黄巾英雄首立功</a></li> <li><a href="/book/sanguoyanyi/2.html">第二回·张翼德怒鞭督邮 何国舅谋诛宦竖</a></li> <li><a href="/book/sanguoyanyi/3.html">第三回·议温明董卓叱丁原 馈金珠李肃说吕布</a></li> <li><a href="/book/sanguoyanyi/4.html">第四回·废汉帝陈留践位 谋董贼孟德献刀</a></li> <li><a href="/book/sanguoyanyi/5.html">第五回·发矫诏诸镇应曹公 破关兵三英战吕布</a></li>
确实是需要的内容。
下一步就是提取url和title,发现url并不是完整的url,前边少了一些内容,也要想办法补全。
url_list = [] for i in list: url_list.append('https://www.shicimingju.com'+i.a['href']) #补全url
最后就是对每一个章节的url访问,提取标签中的所需内容,储存到本地。
soup_detail.find('div',class_ = 'card bookmark-list') 用find方法找到第一个属性为“card bookmark-list” div标签,实际上也可以通过id找。
第一次写时,顺手把find写成了findall,报错。原因在于findall返回的是一个list,而find是第一个匹配的str。
find.text是将所有的,该标签以及该标签的子标签,的内容返回。还有一个是.string,只能返回该标签内容,不包含子标签。
最后用文件with open,追加 ‘a’,的方式储存成一个txt文件。
for i in url_list: text_detail = requests.get(url = i,headers = headers).text soup_detail = bs4.BeautifulSoup(text_detail, 'lxml') content = soup_detail.find('div',class_ = 'card bookmark-list').text with open('./sanguoyanyi.txt','a',encoding= 'utf-8') as fp: fp.write(content) fp.write('\n')
最后是这个样子
总结:bs4确实要比正则灵活一些,可以利用属性、方法直接定位到想要获取的内容。
当天爬的次数过多,直接把家里网络IP疯掉了,把随身的两个手机IP也疯掉了。随之又开始查如何使用代理IP。代理IP直接淘宝买,1块钱10W个,短效的,大部分都能用。http://www.9vps.com/user/default.asp 我买的是这家的。给的是一个url,直接访问,返回的就是一个IP。可以使用爬虫直接访问这个url,接受返回的消息,就可以得到IP,而且对url再次刷新,也就是再次访问,又可以获得一个新的IP。获取IP的方式是对一个固定的url进行访问,好像很多家代理都是这样弄的。
在requests中,有一个参数proxies可以设置IP,亲测是没有问题的,可以百度IP测试。
因为代理IP一般都是短效的,所以需要解决一旦ip失效,要切换ip的问题。思路已经想好,利用try except 捕获异常,重新访问获取代理ip的url,得到新的ip。设置requests中的timeout参数可以设置访问时间。
第二天想这样做,发现网站又给我解封家里的ip了。。。so,暂时放弃,但是一定可以实现。
今天想爬微信公众号的内容,但是微信公众号的url不太好获取。。。学吧- -!

