
爬虫笔记(三)爬取‘糗事百科’热图板块所有图
目的:爬取‘糗事百科’热图板块所有图
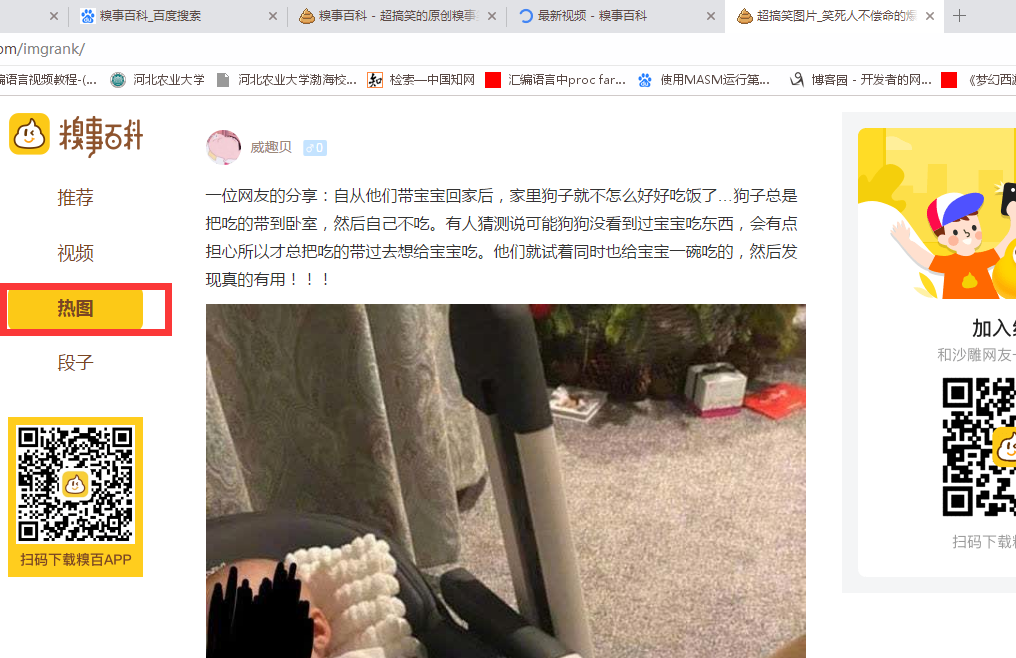
在网页response中可以发现,每个图是一个没有http开头的、以.jpg结尾的链接,在这个链接前边补上http可以成功访问该图片。
所以第一步应该把需要下载的图片的url下载下来,然后补上http,再下载,保存到本地就可以。
下边代码是第一步。

def download_picture_url(pageup,pagedonw): #下载每个图片的url(url前边没有http) picture_url = [] for page in range(pageup,pagedonw): #https://www.qiushibaike.com/imgrank/page/2/ url = 'https://www.qiushibaike.com/imgrank/page/' #补充连接 url = url + str(page) + '/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } page_test = requests.get(url=url, headers=headers).text # print(page_test) data_list = re.findall(r'<div class="thumb">.*?</div>', page_test, re.S) for div in data_list: picture_url.append(re.search(r'(<img src="//)(.*?)(" alt=)', div, re.S).group(2)) for i in picture_url: if i[-3:] != 'jpg': picture_url.remove(i) return picture_url
for page in range(pageup,pagedonw): #https://www.qiushibaike.com/imgrank/page/2/ url = 'https://www.qiushibaike.com/imgrank/page/' #补充连接 url = url + str(page) + '/'
上边代码中是为了实现翻页,每一页的url最后page不一样,所以这样写。
其中response是一个text格式,里边有很多的无用信息,需要从text中提取图片的url。
这里需要说一点,查看浏览器的response不能只看xhr里的,xhr里是动态的,应该查看all里的,
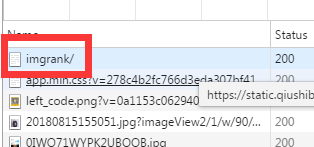
这个才是网页的返回信息,其他的请求都是请求的这个网页后续再请求的内容。也就是在pycharm中requests的返回时这个'imrank/'里的内容。
代码中还涉及到一个re模块的正则匹配,为的是挑出里边图片的url。代码中做了两次正则,第一次有开始和结束标记

第二次才是真正的url

第二步:每一个url前边添加http
def add_http(list_url): #给每一个图片的url添加http list_url_new = [] for i_url in list_url: i_url = 'https://'+i_url list_url_new.append(i_url) return list_url_new
第三部:下载图片到本地
def download(list): #下载每一个图片 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36' } if not os.path.exists('./qiushilib'): #建路径立一个文件夹,如果不想在当前目录下建,可以用makedirs建,参数写绝对 os.makedirs('./qiushilib') num = 1 for i in list: picture_content = requests.get(url=i, headers=headers).content #path = './qiushilib' + '/' + i.split('/')[-1] path = './qiushilib' + '/' + '第'+str(num)+'个'+i.split('/')[-1] with open(path, 'wb') as p: p.write(picture_content) print(i.split('/')[-1], '下载成功',num) num = num + 1
在前几次下载中,发现不论怕多少页,结果都是25张图。经过研究发现,第一页中每一张图和和第二页中每一张图.jpg前边的编号是一样的,所以造成如果用编号做图片名称的话,导致只能下载第一页的,第二页相当于就有这个文件名了,就不下载了。
整个过程没有解决的问题:由于家里网络不稳定,导致经常下载失败,目前还不会下载失败重新下载,或多试几次这个功能,日后也是需要学习的。
最后主函数:
if __name__ == '__main__': picture_url = download_picture_url(1, 3) list_url_new = add_http(picture_url) download(list_url_new)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App