
新闻分类(包含:画词云图、停用词使用等)
import pandas as pd data = pd.read_table('val.txt',names=['category','theme','URL','content']) #读取数据,转成DataFrame格式。因为前期数据已经是处理好的,所以可以这样写。这里的read_table和read_csv可以互换的,一个意思。
data.dropna(inplace=True) #丢掉有空数据的行 print(data.shape) #发现没有空的数据。。。 data_content = data['content'].tolist() #把content一列变成list,等下用jieba分词器拆解每一行 import jieba data_content_list = [] #这一个list中套list,也就是二维数组 for i in data_content: jieba_content = jieba.lcut(i) if len(jieba_content)>1 and jieba_content!='\r\n': #排除空行之类的数据 data_content_list.append( jieba_content ) data_content_df = pd.DataFrame({'data_content_list':data_content_list})
import pandas as pd stopwords_data = pd.read_table("stopwords.txt",sep="\t",quoting=3,names=['stopword'],encoding='utf-8') #缺少 quoting=3报错 stopwords_data_list = stopwords_data['stopword'].tolist() stopwords_list_letter = [] for i in range(ord('a'),ord('z')): stopwords_list_letter.append(chr(i)) for i in range(ord('A'),ord('Z')): stopwords_list_letter.append(chr(i)) #原数据中包含这些英文字母,但是这不是简单的英文字母,ascii码值没有在0-127之内 stopwords_data_list = stopwords_list_letter+stopwords_data_list #重新组成新的停用词list data_content_and_stopwords_list = [] #去停用词之后的content,最终结果也是一个list中套list all_content_and_stopwords_list = [] #data_content_list 是需要去停用词的list,是一个list中套list for i in data_content_list: line_content = [] for j in i: if j not in stopwords_data_list: line_content.append(j) all_content_and_stopwords_list.append(j) #all_content_and_stopwords_list 内容是所有词,做词频用 data_content_and_stopwords_list.append(line_content) #这是去停用词之后的结果
#统计词频,转为字典 data_temporary_all_content_and_stopwords_df = pd.DataFrame({'content':all_content_and_stopwords_list}) counts = data_temporary_all_content_and_stopwords_df['content'].value_counts() df_counts = pd.DataFrame({'counts':counts}) dic = dict(zip(df_counts.index.tolist(),df_counts['counts'].tolist())) print(dic) #统计词频,转为字典 #上边写这么多很麻烦,可以直接用collection直接实现 # from collections import Counter # dic = Counter(all_content_and_stopwords_list) #如果想把dic转成字典 #df = pd.DataFrame(dic.items(), columns=['key', 'value'])
画词云图:
from wordcloud import WordCloud import matplotlib.pyplot as plt wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color="white",max_font_size=80) wordcloud=wordcloud.fit_words(frequencies=dic) #frequencies参数是接收的数据 plt.imshow(wordcloud) #plt.axis('off') #去掉横纵坐标 plt.show()
wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color="white",max_font_size=80) 中font_path="./data/simhei.ttf",是中文字体的路径。如果缺少这个参数,显示不出中文。WordCloud的参数还有很多很多,用的时候查手册,百度就可以。
下边用TF-IDF算法提取关键词,使用jieba.analyse.extract_tags()
import jieba.analyse analyse_data_content_str = ''.join(data_content_and_stopwords_list[2400]) key_words = jieba.analyse.extract_tags(analyse_data_content_str,topK=5, withWeight=False) print(key_words)
关于TF-IDF和jieba.analyse.extract_tags(),请参考https://blog.csdn.net/qq_38101190/article/details/90750188和https://www.cnblogs.com/1061321925wu/p/12518541.html
jieba.analyse.extract_tags()参数中,第一个参数必须是str才可以,不能是list;topK是提取的关键词个数;withWeight是否返回权重。如果为True,jieba.analyse.extract_tags()是一个二维的list,list[0]是第一个关键词和权重组成的list,list[0][0]才是第一个关键词的权重。如需访问权重,需要注意这一点。
下一步是利用词袋法,把所有的词编号,将编号和词频映射成一个多维的向量。其实就是多行多列的list。计算机不认识自然语言,计算机智能认识数,所以不管是什么算法,都是需要将输入的信息转换成计算机能读懂的数,计算机才能识别、工作、运行。
from gensim import corpora, models, similarities import gensim dictionary = corpora.Dictionary(data_content_and_stopwords_list) ##格式要求:list of list形式,分词好的的整个语料。corpora.Dictionary是把list of list中每一个词编码,组成一个字典的形式。 #corpus = [dictionary.doc2bow(sentence) for sentence in data_content_and_stopwords_list] corpus = [] for i indata_content_and_stopwords_list: corpus.append(dictionary.doc2bow(i))
这个段代码中的for循环很重要,做了一件很重要的事,就是把词编码和词频组成了一个元组,然后把所有的元组组合起来。
例如:例如list[0]中的内容是:[(63330, 1), (64306, 2), (65540, 1)………],(63330, 1):在第0个文本中编号63330出现了1次。应该能够想到,在经过这一步之后,每一行的词顺序已经被打乱了。例如:我爱小红,小红爱我,经过这一步,结果是一样的。
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
这里是建立lda模型,num_topics:把原始数据分成几大类主题。这个参数需要自己根据经验去调。
可以通过:
for topic in lda.print_topics(num_topics=20, num_words=5): print (topic)
打印分类好的主题的关键词。
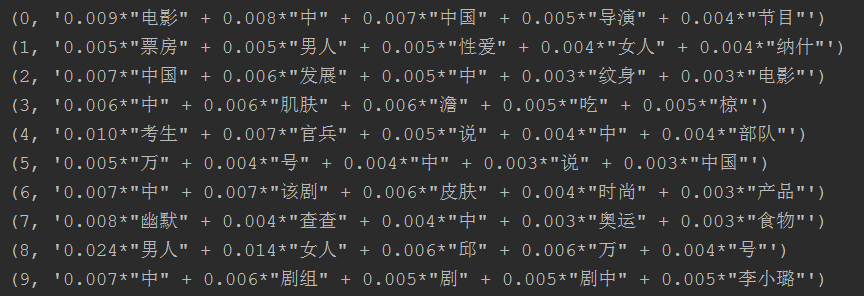
topic的结果是一个tuple类型,和list差不多,就是不能更改,只能加新的内容。topic[0]是主题编号,topic[1]是主题关键词。
在这里说一下,可以利用get_document_topics预测新的新闻是属于哪种主题类型的。例如:
new_sensence = "贩卖毒品是违法行为" grouping = lda.get_document_topics(dictionary.doc2bow(jieba.lcut(new_sensence))) print(grouping)
结果是一个由主题编号和概率组成的list。例如:[(0, 0.5992214), (1, 0.10000743), (2, 0.100016914), (3, 0.1007327), (4, 0.100021526)],发现"贩卖毒品是违法行为"和第0个主题接近的概率最大。(这里为了方便,没有和上边数据对应上,就是这个意思而已。数据量太大了跑起来太慢了。。。。)
下一步,利用朴素贝叶斯解决新闻分类问题。
大致思路是:先用词袋法把词频转为向量,再用贝叶斯分类。
from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import CountVectorizer #词袋法 from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯模型 x_train, x_test, y_train, y_test = train_test_split(new_data_df['words'], new_data_df['label'],random_state=1) #和之前讲的一样,把数据分为两部分,训练集和测试集。训练集负责训练模型,测试集负责测试准确度。分割比例默认7:3,可以设置。 def translate_list(serires_list): words = [] for i in serires_list: words.append(' '.join(i)) return words train_words = translate_list(x_train) test_words = translate_list(x_test)
translate_list(serires_list)函数把list of list转换为一个list形式,为后边的fit做铺垫。比如[['11','22','33'],['44','55','66']]转为['11 22 33','44 55 66'],后边fit只能接受这种格式的参数。
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False) #lowercase将单词转为小写,也就是说内置了转为小写的功能 #CountVectorizer参数详解:https://blog.csdn.net/weixin_38278334/article/details/82320307 classifier = MultinomialNB() classifier.fit(vec.fit_transform(train_words),y_train) print('test_words_sorce',classifier.score(vec.transform(test_words), y_test))
classifier.fit(vec.fit_transform(train_words),y_train) 中vec.fit_transform(train_words)是把词转为词向量,相当于是特征向量,y_train是label。
classifier.score()评分输出:test_words_sorce 0.804。这里存在疑问,有的资料说这里是准确率,所以自己写了一个准确率计算的过程。
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False) #lowercase将单词转为小写,也就是说内置了转为小写的功能 #CountVectorizer参数详解:https://blog.csdn.net/weixin_38278334/article/details/82320307
classifier = MultinomialNB()
classifier.fit(vec.fit_transform(train_words),y_train)
y_test_predict =classifier.predict(vec.transform(test_words))
sum = 0
for i in y_test_predict.tolist():
if y_test_predict.tolist()[i] == y_test.tolist()[i]:
sum = sum+1
print(sum/len(y_test_predict))
输出结果:0.9032。y_test_predict是预测的结果,y_test是原始的数据,看两个ndarray中相同元素的个数就行。
print(vec.get_feature_names()) 可以以列表形式获得所有的词,相当于是词频矩阵的表头
print(vec.transform(test_words).toarray()) 可以打印test_words转成词频后的稀疏矩阵。
在用TFIDF做一下。TFIDF简单来说,就是某一个词,在整体文章出现的次数多,在某一个新闻中出现的也多,说明这个词虽然词频很高,但不是很重要。例如“的”、“了”等。反之,如果某一个词在整篇文章中出现的频率不高,但是在某一个新文章出现的次数多,说明很重要。大致就是这个意思。
from sklearn.feature_extraction.text import TfidfVectorizer #词袋法 from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯模型 train_words = translate_list(x_train) test_words = translate_list(x_test) vec = TfidfVectorizer(analyzer='word', max_features=4000, lowercase = False) #lowercase将单词转为小写,也就是说内置了转为小写的功能 #CountVectorizer参数详解:https://blog.csdn.net/weixin_38278334/article/details/82320307 classifier = MultinomialNB() classifier.fit(vec.fit_transform(train_words),y_train) print('test_words_sorce',classifier.score(vec.transform(test_words), y_test))
输出:test_words_sorce 0.8152
计算准确度:
vec = TfidfVectorizer(analyzer='word', max_features=4000, lowercase = False) #lowercase将单词转为小写,也就是说内置了转为小写的功能 #CountVectorizer参数详解:https://blog.csdn.net/weixin_38278334/article/details/82320307 classifier = MultinomialNB() classifier.fit(vec.fit_transform(train_words),y_train) print(vec.transform(test_words).toarray()) y_test_predict =classifier.predict(vec.transform(test_words)) sum = 0 for i in y_test_predict.tolist(): if y_test_predict.tolist()[i] == y_test.tolist()[i]: sum = sum+1 print(sum/len(y_test_predict))
输出:0.9040,看起来还是有提升的。
如果数据量更大,预测更准确。
参考博客:https://blog.csdn.net/weixin_43746433/article/details/92801334
在朴素贝叶斯原理那,个人感觉http://www.peixun.net/view/1278.html 菊安酱的视频讲的不错(后边代码部分讲的一样烂)。
所有代码亲测可跑,欢迎交流。

