Linux三剑客,业务模型
1.三剑客:grep、send、awk
作用:主要应用于查看日志、分析日志、命令监控、修改配置文件shell脚本等
演示数据:
数据1:/etc/passwd
数据2:test.sh
#!/bin/bash for ((i=1;i<=10;i++)) do echo test_$i done
数据3:sh test.sh > 1.txt
1.1 sed
功能:编辑,不会改变原来的内容
要改变需要重定向
1.1.1 常用参数
n:把匹配到的内容输出打印到屏幕上
sh test.sh|send -n '3p'

p:以行为单位进行查询
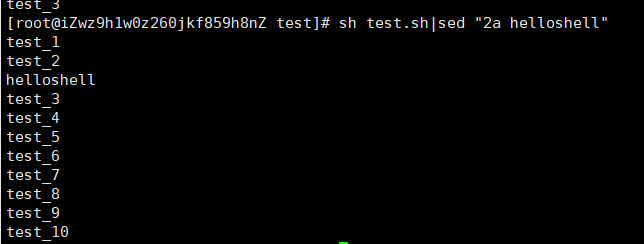
a:表示新增
sh test.sh|send "2a helloshell"
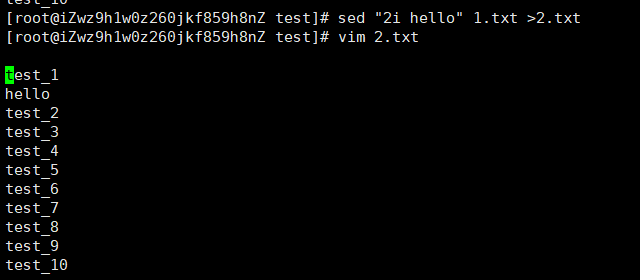
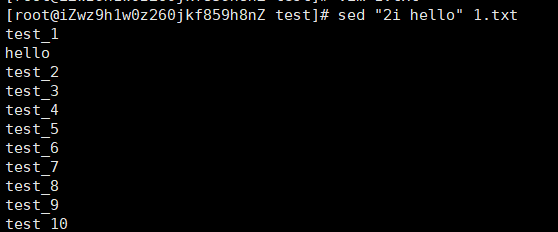
i:表示插入
sed " 2i hello" 1.txt
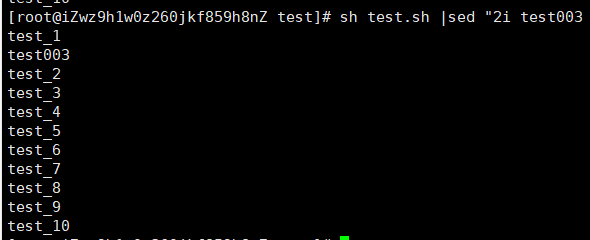
sh test.sh|sed "2i test003"
c:表示替换
sed "2c hello" 1.txt
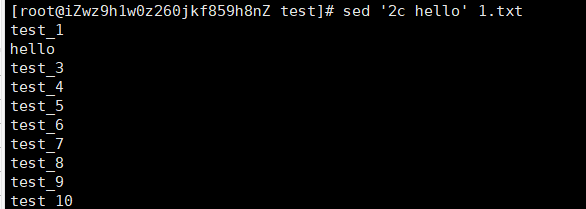
d:表示删除
sed '2d' 1.txt
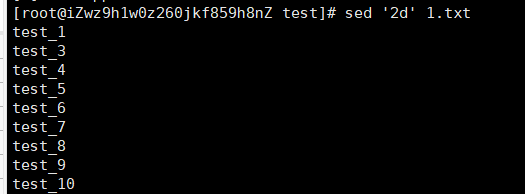
s/要被取代的内容/新的字符串/g 全部替换
sed ‘s/1/11/g’ 1.txt
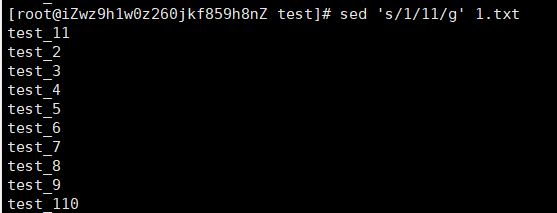
-i 对原文件进行修改
sed -i 's/2/22/g' 1.txt
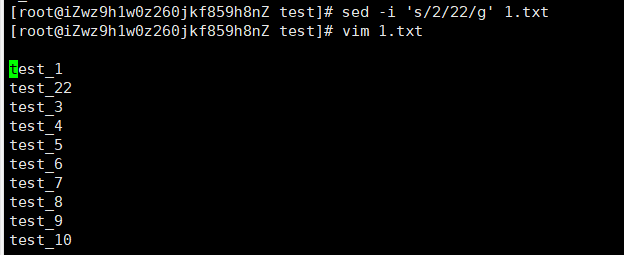
/被搜索内容/p
sed -n '/test_22/p' 1.txt

sed -n '/112.29.171.80/p' /mysql/logs/alert.log

1.2 grep
功能:查找
grep mysql /tec/passwd

1.2.1 参数
-E:表示或
grep -E 'roo|ren' /etc/passwd 查找passwd文件包含roo或ren的行


-i :忽略大小写
grep -niE "exception|error" catalina.out .2020-10-25
查找catalina.out .2020-10-25文件包含exception或error的行忽略大小写并显示行号
tail -f catalina.out.2020-10-25 | grep -niE "exception|error"
动态显示catalina.out .2020-10-25并查找文件包含exception或error的行忽略大小写并显示行号
tail -fn500 xxx.log|grep grep -niE "exception|error"
动态显示后500行并查找包含exception或error的行忽略大小写并显示行号
-v:输出不匹配行 排除
ps -ef|grep java| grep -v "grep" 查找包含java的文件忽略grep所在行
-w:匹配指定字符串
grep -w 'roo' /etc/passwd 查找passwd包含roo的行 无结果
grep -w 'root' /etc/passwd 查找passwd文件包含root的行 有结果
^: 匹配开头行首
grep '^root' /etc/passwd 查找passwd文件以root开头的行
ls -l|grep "^-"|wc -l 统计当前目录下文件个数

统计当前目录下目录个数 ls -l|grep "^d"|wc -l
-R 目录和子目录


$:匹配结尾行尾
cat /etc/passwd|grep nologin$ 查找passwd文件以nologin结尾的行
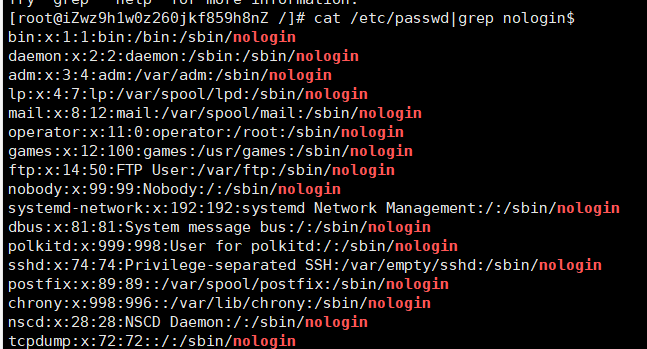
-n:表示对提取的内容显示所在行号
grep -n 'ren' /etc/passwd 查找passwd文件包含ren的行并显示行号

-AN 展示往下几行
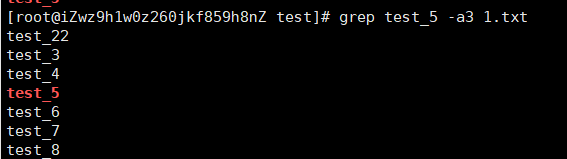
grep test_5 -A3 1.txt

-BN 展示往上几行

-aN 展示往上下几行
1.3 awk
功能:文本与数据处理
1.3.1 输出
printf格式化输出,不会自动换行
awk -F ':'{printf("User:%s UID:%s\n",$1,$3)} /etc/passwd:printf格式化列出用户名、用户标识号 与\n合用
print打印输出内容,会自动换行
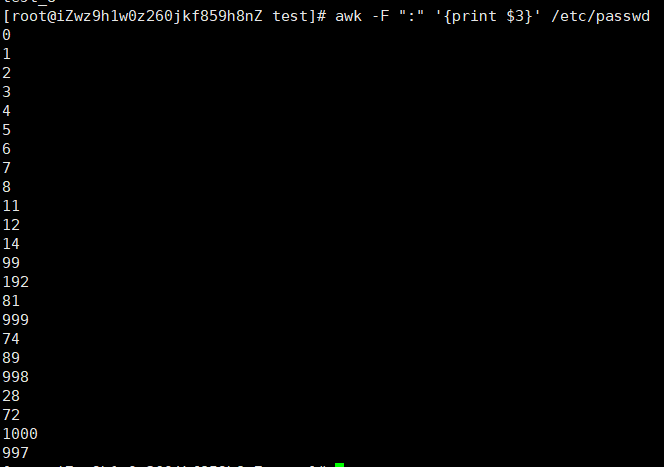
awk -F ":" '{print $3}' /etc/passwd:格式化输出passwd文件以:分隔的第三列
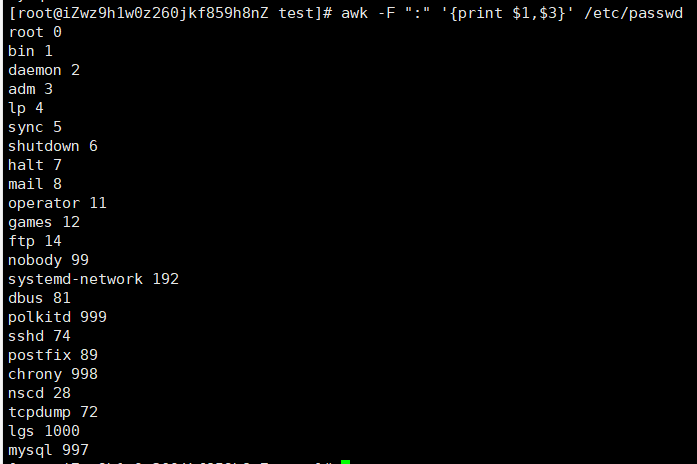
cat /etc/passwd|grep test|awk -F ':'{print $1,$3}
等价于:awk -F ':' '{print $1,$3}' /etc/passwd | grep test:查找test文件以:分隔的第一列,第三列内容
1.3.2 参数
-F:指定分隔符 awk默认是空格 cut 默认为制表符 不是空格
1.3.3 awk内置参数
$0:表示整个当前行
$1:每行第一个字段
$2:每行第二个字段
$n:每行第n个字段
awk -F ':' {print $0} /etc/passwd 打印所有内容
awk '{print $1}' /usr/local/nginx/logs/access.log 打印日志第一列
NR:每行的行号
df -h|awk 'NR==6 {print $5}' 打印第六行第五列 df磁盘使用率

NF:字段数量(列数),如果是$NF,就表示最后一列
awk -F ':' '{print NR,NF,$NF}' /etc/passwd:打印出行号,列数,和最后一列数据
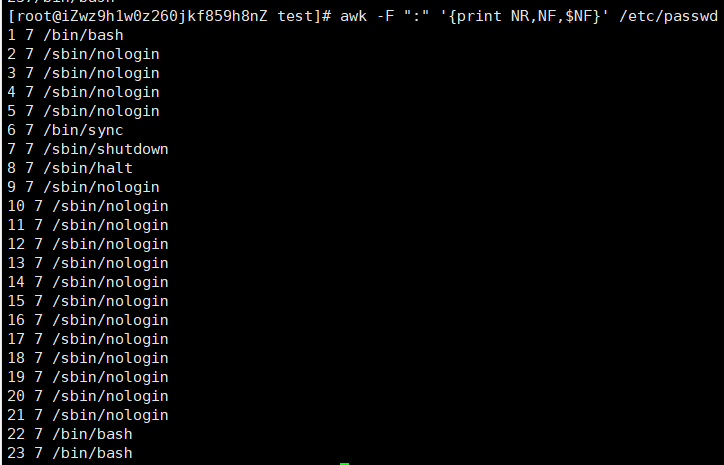
获取3-5行第一列数据



1.3.5 逻辑判断式
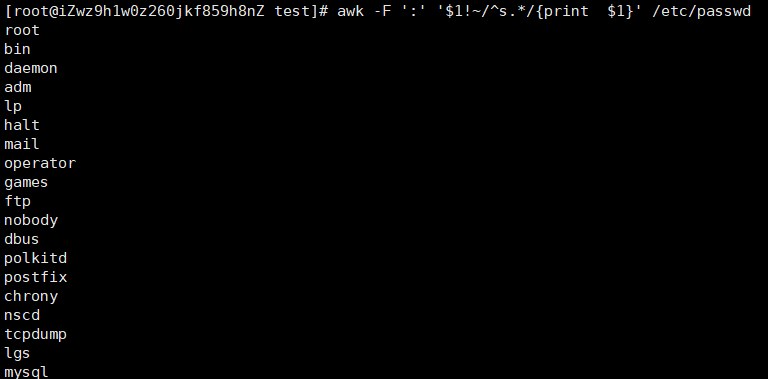
~,!~:匹配正则表达式
awk -F ':' '$!~/^s.*/{print $1}' /etc/passwd:匹配第一列不以s开头的数据
==,!=,<,>:判断逻辑表达式
awk -F ':'$3>500{print $1,$3} /etc/passwd:显示/etc/passwd中用户名ID大于500的用户名和ID

awk -F ':''{if($3>500) print $1,$3}' /etc/passwd

1.3.6 其他
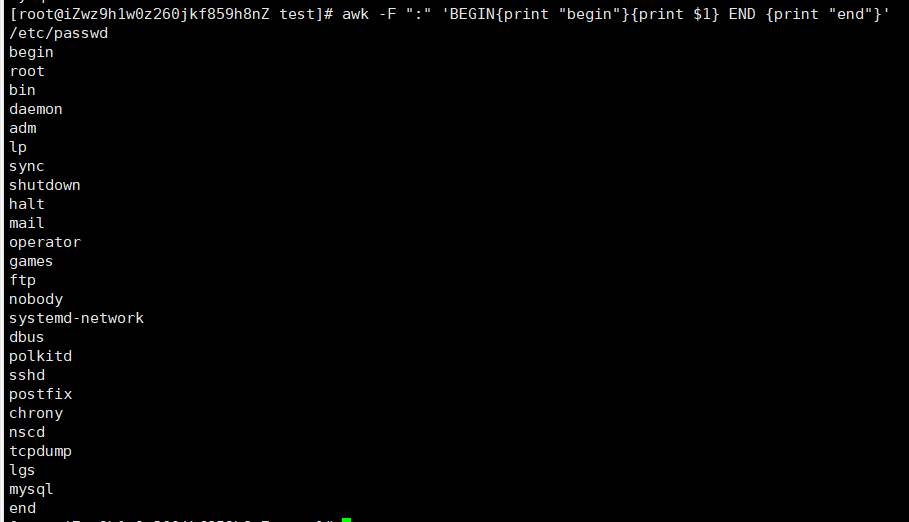
BEGIN:在读取所有行内容前就开始执行,常常被用于修改内置变量的值
awk -F : 'BEGIN{print "begin"}{print $1}END{print "end"}' /etc/passwd:以begin开头、end结尾,打印第一列数据
FS:BEGIN时定义分隔符
cat /etc/passwd |awk 'BEGIN {FS=":"}{print $1}' |head -n3:BEGIN{FS=":"}等价于 -F ":"
END:结束的时候执行
cat /etc/passwd |awk -F ":" '{print $1}END{printf "执行完成"}'
1.3.7 搜索
awk '/test_5/' 1.txt

awk '/112.29.171.80/{print $1}' /mysql/logs/alert.log 搜索Ip访问时间

netstat -n|grep ^tcp|awk '{print $NF}' |sort|uniq -c|sort -k 1 r 查询以tcp开头的进程打印最后一行,并排序(统计相同的行)
 1.4 cut
1.4 cut
功能:提取列
1.4.1 参数
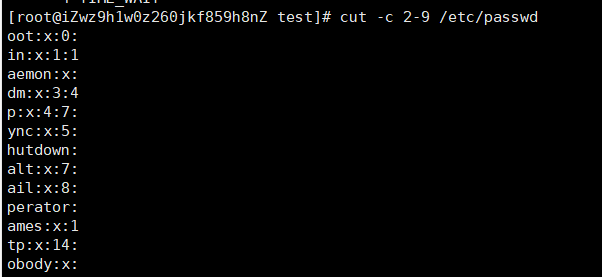
-c 以字符为单位进行分隔
cut -c 2-9 /etc/passwd :截取/etc/passwd文件从第二个字符到第九个字符
cut -c -4 /etc/passwd:截取/etc/passwd文件前4个字符
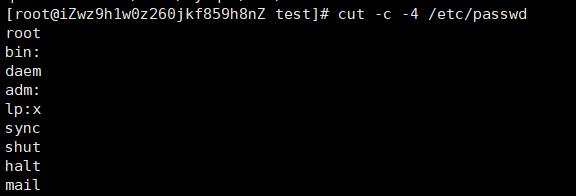
cut -c 4- /etc/passwd 截取/etc/passwd文件4末尾的字符
-f 指定截取区域
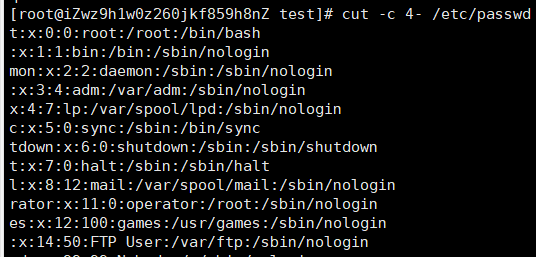
cut -d ':' -f 2- /etc/passwd 以':'为分隔符,截取除/etc/passwd的第二列到最后一列
-d 指定分隔符
awk默认是空格,cut默认为制表符,不是空格
所以,cut的缺点是,空格的时候没发操作
1.5 uniq
作用:uniq用于检查或者统计文本出现的重复行
1.5.1 常用参数
-c 它用于连续重复行次数的统计
数据
uniq -c 3.txt |sort -r
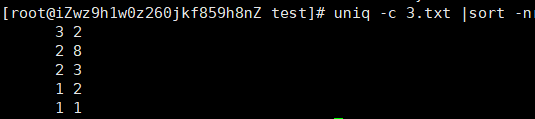
uniq -c 3.txt
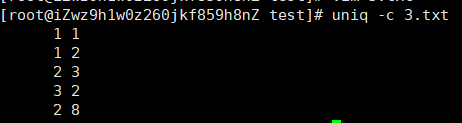
1.6 sort
功能:sort的默认方式就是把第一列根据ASCII值排序输出
1.6.1 常用参数
-n 依照数值的大小排列 默认n
sort -n 是按照第一列的数值大小进行排序
-r 以相反的顺序来排序
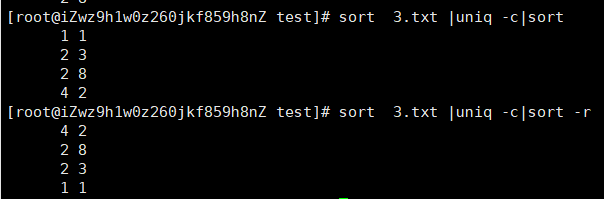
-k 选择以某个区间进行排序
sort -r 1.txt :将内容倒序输出
数据 12111332
结果 33 22 1111
1.7 wc
功能:统计指定文件中的行数、字节数、字数,并将统计结果显示输出
1.7.1 参数
-l 统计行数
wc -l /etc/passwd 统计/etc/passwd文件有多少行

grep root /etc/passwd|wc -l

指定目录下,所有txt文件中行数
find /root/test -type f -name "*.txt" -exec wc -l {} \;
find /root/test -type f -name "*.txt" |xargs -l {} wc -l {}
find /root/test -type f -name "*.txt" |xargs -i wc -l {}
删除20天以前的文件
find ~/ -name "*" -ctime+20 -exec rm -f{} \;
2.业务模型
2.1 业务比例统计
按天统计:cat access.log|awk '{print $4}'|cut -c 2-12|sort |uniq -c |sort -nr
结果
35624 03/May/2022
业务量最多的天,按小时
cat access.log |grep 03/May/2022 |awk '{print $4}'| cut -c 2-15|sort |uniq -c |sort -nr:查询2022年5月3日日志并打印第四列数据(年月日),排序(统计重复次数)|再按降序排列
结果
14080 03/May/2022:17
11074 03/May/2022:16
7116 03/May/2022:18
3349 03/May/2022:15
5 03/May/2022:14
业务最多的天里,业务量最多的小时,统计业务比例
如果更细的维度有峰值,那么需要进一步细化,比如分、秒
按分统计:cat access.log |grep 03/May/2022:17 |awk '{print $4}'|cut -c 2-18|sort |uniq-c|sort nr
结果
236 03/May/2022:17:59
236 03/May/2022:17:58
236 03/May/2022:17:57
236 03/May/2022:17:56
按分统计接口请求数:cat access.log|grep 03/May/2022:17|awk '{$7}'|sort|uniq-c|sort -nr
结果
7040 /register
3520 /login
3520 /add
按秒统计:cat access.log|grep 03/May/2022:17:58 |awk 'print $4'|cut -c 2-21|sort| uniq -c |sort nr
结果
4 03/May/2022:17:58:59
4 03/May/2022:17:58:58
4 03/May/2022:17:58:57
4 03/May/2022:17:58:56
说明:其它业务量非最大天,但是其它维度是峰值的,也要考虑
2.2 业务模型获取
重要性
是性能测试确定测试范围的依据
是综合场景设计的业务比例的依据
方式
方式1:使用命令获取 grep、awk,sed等命令,如上业务比例统计
方式2:日志平台获取
ELK:
elasticsearch
看图:
- Analytics--Visualize Library--create--Lens
- File fifter拖动request_keyword:request.keyword:"/login" or request.keyword:"/register"
Discover:
- 日志 年月日 时分秒 统计
logstash:耗费资源
kibana:kql
EFK:ELK+Filebeat
ELK+Filebeat+kaflka
说明:历史业务模型可能有多个,所以需要从不同的维度(天,小时,分钟,秒)去获取业务高峰数据
2.3 练习
2.3.1 业务模型提取练习:用公司的日志平台、或者用命令,对公司日志提取出业务模型
2.3.2 思考:restful api,如何提取业务模型?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号