jmeter组件使用详解(二)
1.jmeter组件使用详解
1.1 断言(Assertions)
请求成功(返回200),不代表业务成功,业务的成功,只能靠业务来判断
断言不要检查中文(检查元素)
jmeter最佳实践说少加,加不加根据实际情况
为了方便(压力机性能好的情况下):
- 单场景:建议查询加,非查询不加
- 混合场景:建议每个请求接口加
1.1.1 响应断言详解
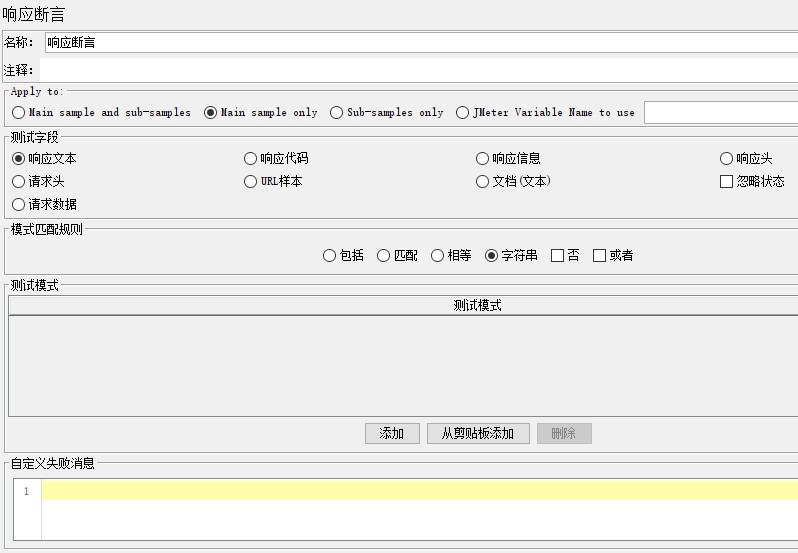
apply to:
- main sample and sub-samples
- main sample only
- sub-sample only
- jmeter variable name to use(比较自定义变量值)
一般勾选“main sample only”就足够了(默认)
重定向请求(勾选了“跟随重定向”)那么就要有 main sample and sub-samples
模式匹配规则
- 包括:正则表达式匹配部分和全部,可以断言多个,and
- 匹配:正则表达式匹配部分和全部
- 相等:纯文本,区分大小写(完全匹配,比“匹配”更严格,因为区分大小写)
- 字符串:纯文本,区分大小写(完全匹配,比“匹配”更严格,因为区分大小写)
- 否:取反(如果是选择包括+否,就是不包括)
- 或者:可以断言多个,包含一个就成功
说明:
- 模式匹配规则为“包括”和"匹配"时,支持正则表达式
- 当为“相等”或“字符串”时完全匹配
- jmeter中,断言成功不显示,失败才显示
1.1.2 断言持续时间
响应时间大于这个值,就报错(不会忽略思考时间)
1.1.3 Bean Shell断言
1.2 监听器(Listener)
1.2.1 查看结果树
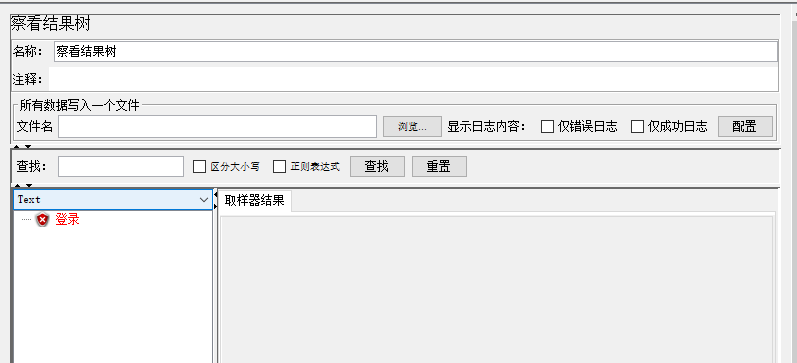
调试脚本用,调试成功后禁用,否则影响性能,或者只显示错误的
默认是接受返回数据但是不保存,要保存什么数据就勾选
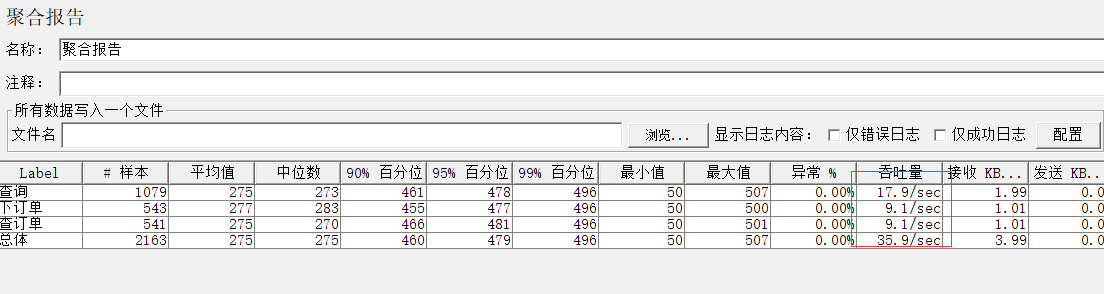
1.2.2 聚合报告
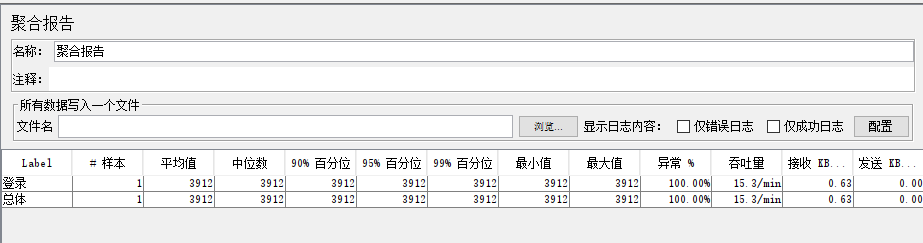
样本:请求个数
平均值:平均响应时间
中位数:50%的请求所用的时间不超过该值
90% 百分位:90%的请求所用的时间不超过该值
异常 %:错误率,比如断言失败。本次测试中出现错误的请求的数量/请求的总数
吞吐率:即每秒多少请求/业务(包含成功和失败的)
Kb/sec:网络吞吐率,每秒多少Kb
1.2.3 jp@gc - Transactions per Second(tps)
1.2.4 jp@gc - Response Times Over Time(响应时间)
1.2.5 jp@gc - Active Threads Over Time(活动线程时间分布)
1.2.6 用表格察看结果
说明:运行的时候,监听器用得越少越好,尽可能只用一种监听器作结果记录,否则会十分影响性能
1.3 逻辑控制器
1.3.1 事务控制器


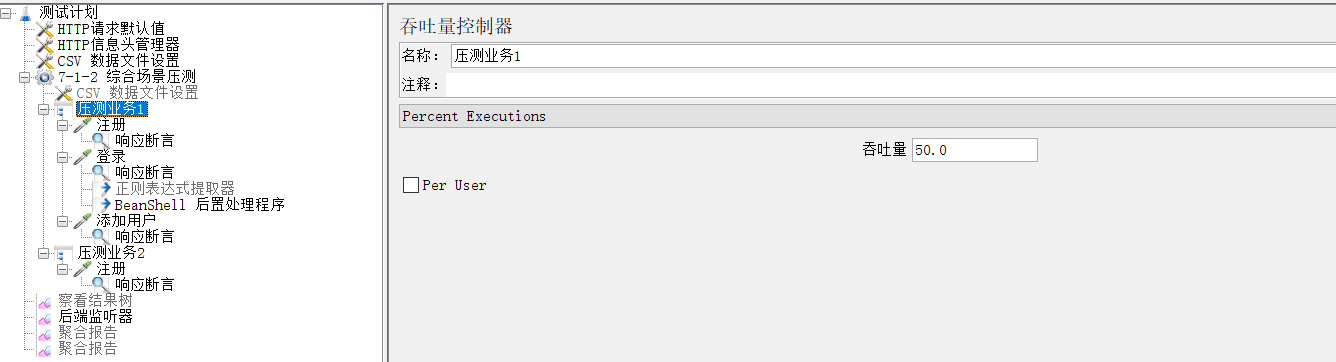
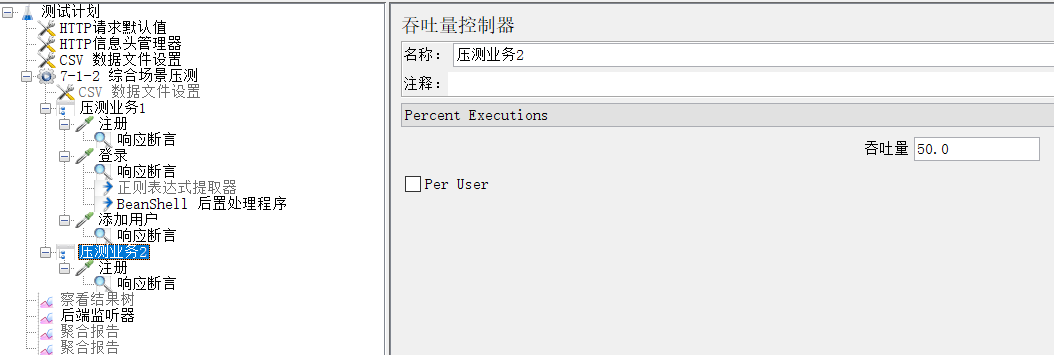
1.3.2 吞吐量控制器
业务模型、业务比例
有关联的业务模型
业务1 查询
业务2 下订单
业务3 查订单
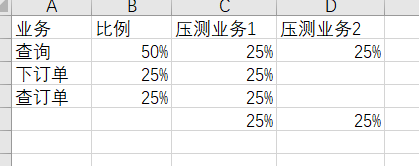
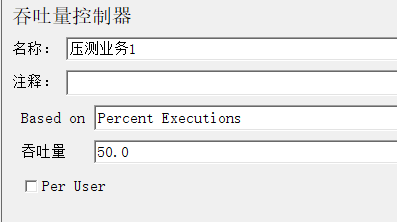
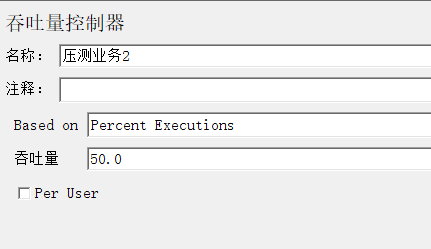

比例:2:1:1
无关联业务模型
业务1:
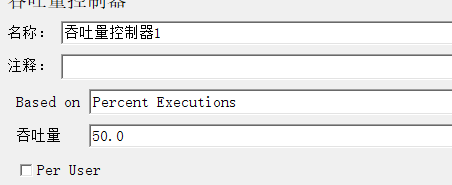
业务2
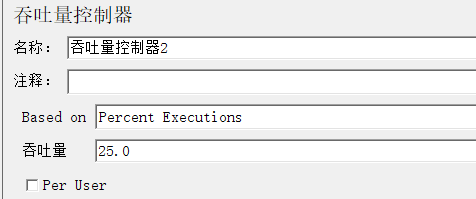
业务3
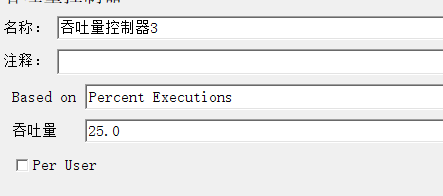
比例2:1:1

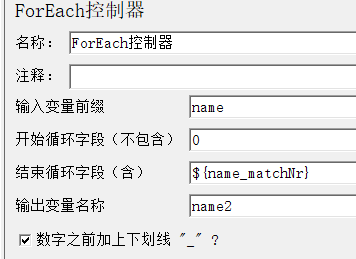
1.3.3 ForEach控制器
1.3.4 仅一次性控制器
2.场景设置案例
2.1 混合场景(业务比例应用)
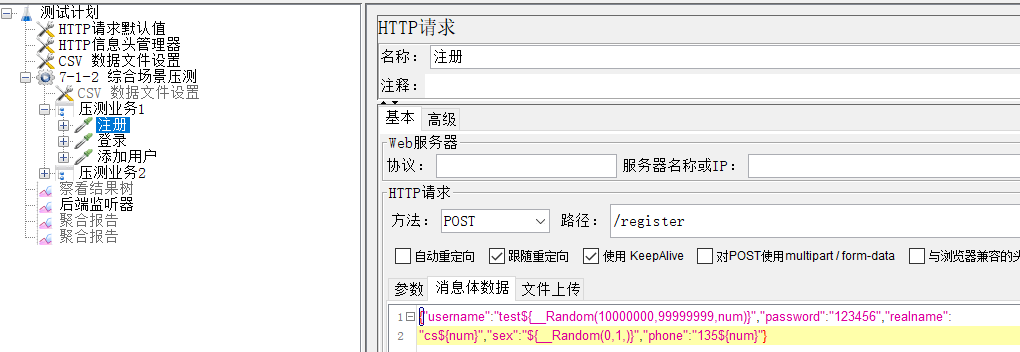
2.1.1 业务比例 :注册:登录:添加=2:1:1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号