jmeter组件使用详解(一)
1.jmeter组件使用
创建脚本的方式:
代理录制:jmeter自带http代理服务器
抓包手写:应用层抓包工具(fillder,charles,F12等)
根据API文档手写
1.1 测试计划详解
它是jmeter测试元件的容器
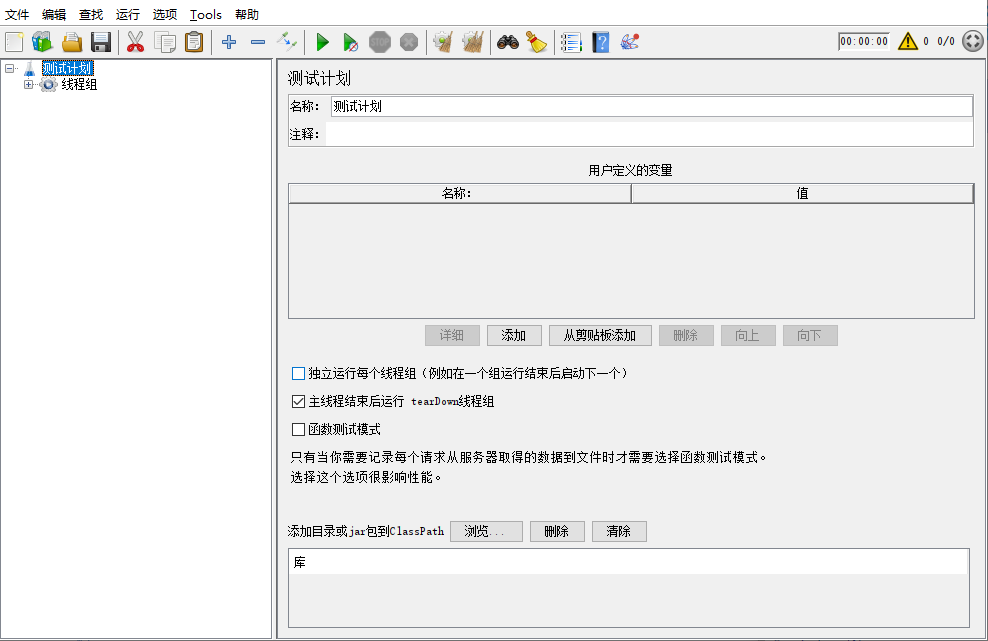
用户定义的变量(User Defined Variables):可以定义整个测试中使用的重复值
独立运行每个线程组:
- 勾选后,普通线程组之间按上下排列顺序执行,而非默认的执行
- 默认不勾选,不勾选表示各种运行自己的
函数测试模式:压测的时候不选择,否则影响性能
添加classpath(需要重启jmeter):
- 类路径设置,可以添加jar文件的目录到特定的测试计划
- 也可以直接把jar包放到jmeter的lib目录(默认的classpath)
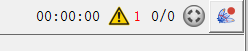
上面分别表示:
- 运行时间
- 日志,如果有错误日志,数字标红
- 线程:绿色表示正在运行(灰色表示未运行)
1.2 线程组
1.2.1 线程组(Thread Group)
给服务器发请求的,发送压力
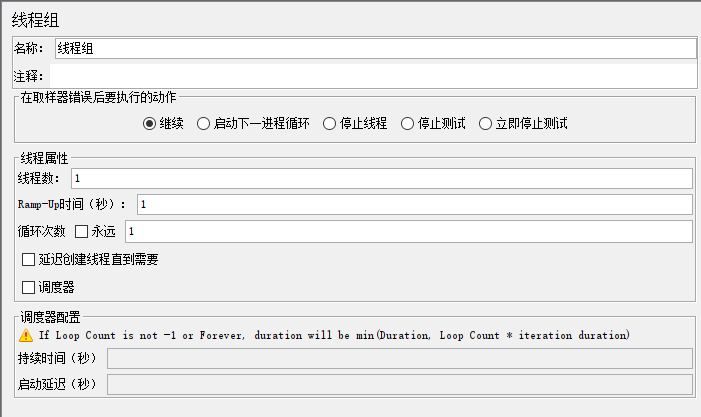
在取样器错误后要执行的操作:
- 继续:线程出错继续执行
- 启动下一线程循环:开始下一次循环
- 停止线程:3个线程循环2次,如果第二个线程出问题,这个线程就停止,继续运行其余线程
- 停止测试:把线程运行的请求运行完才停止
- 立即停止测试:立刻停止
线程属性:
线程数设置多少合适:线程要占用内存资源,创建线程要消耗cpu,结合tps和rt,如果应用处理快,可以设置少点
Ramp-Up时间(秒):线程在多少秒内启动(如果线程数是100,这里设置为10,表示10秒内启动100个线程,但是不一定是每秒启动10个线程)
调度器配置:
持续时间:最终的持续时间包含了启动时间
启动延迟:定时启动
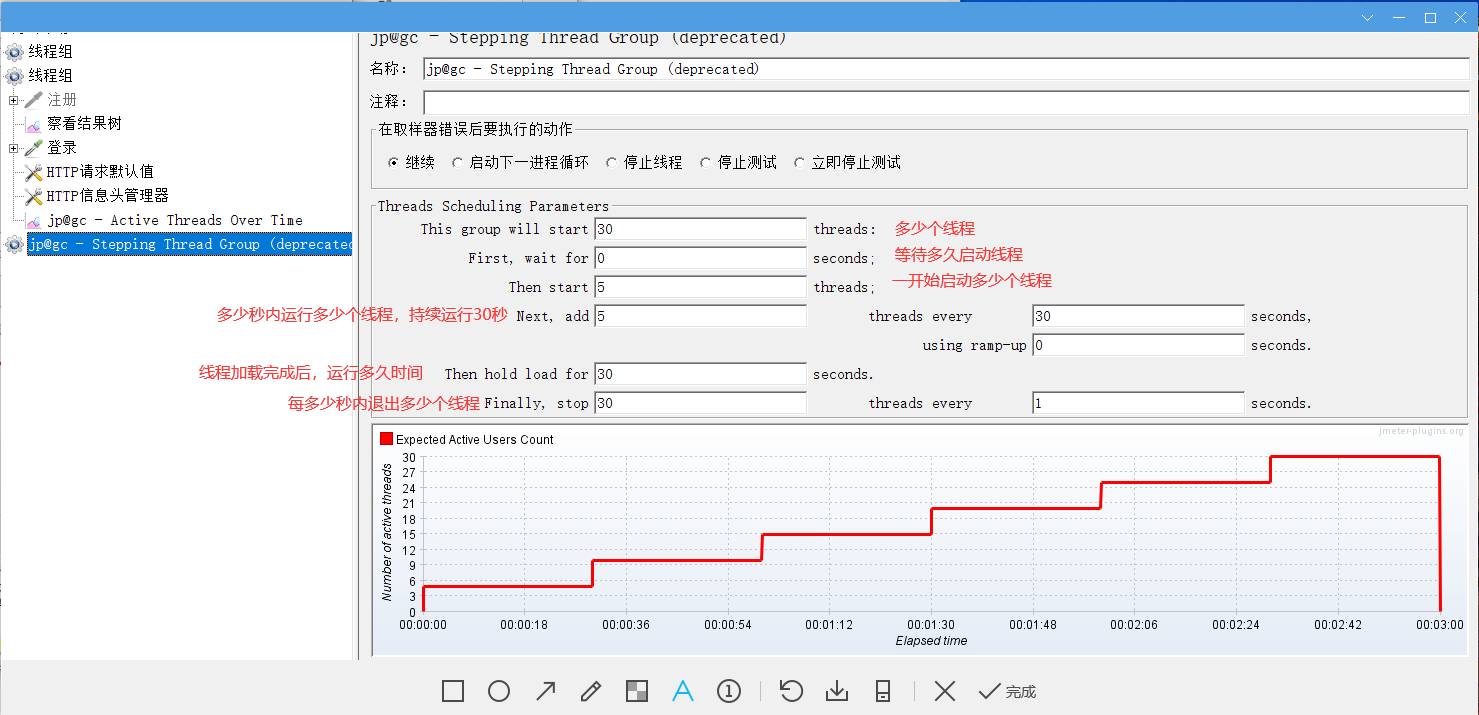
1.2.2 jp@gc-Stepping Thread Group
阶梯加压,和自带的比,多了阶梯加压完成后,还可以设置持续运行多少时间
自带的,虽然没有明显的阶梯,但是场景还是有意义
1.2.3其他线程组
setup线程组:执行前执行一次,应用场景是初始化数据
tearDown线程组:执行后执行一次,做关闭连接、清除垃圾数据等收尾工作
1.3 配置元件(ConfigElement)
1.3.1 CSV数据文件配置
作用:用于参数化实现,
说明:参数值最后只能一个空行或者没有空行
参数化实现的几种方式:
- csv数据文件配置
- 用户定义的变量
- 相关函数
- beanshell脚本
批量造csv参数化数据的方式:
- 代码(Java,json)
- 从数据库导出
- 并发业务接口
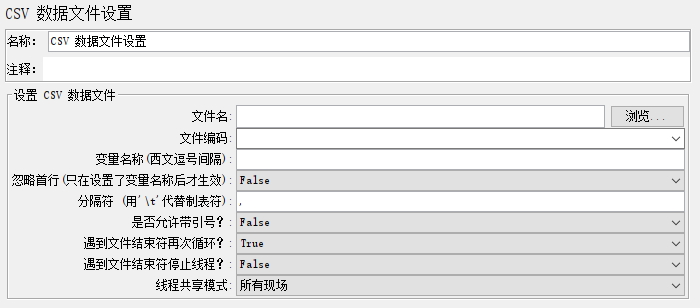
1.文件名:在当前测试计划下的相对路径或绝对路径
不要放中文路径下,路径不要包含空格,特殊字符
可以参数化:放在bin目录下可以用这种路径:${__P(user.dir,)}${__P(file.separator,)}user.csv
2.文件编码:一般选用UTF-8
变量名称(西文逗号间隔):
参数文件中每列的名称,如果有多列,用英文逗号间隔,如果只有一列,则不加分隔符
忽略首行(只在设置了变量名称后才生效):如果参数文件中有很多列,为了区分每列,就在首行把列名写上,此时就要选True
比如:
username,password,age,addr,phone
jack,123456,18,beijing,119
tom,123456,19,beijing,110
4.分隔符(用'\t'代表制表符):是变量值的分隔符,比如上面,分隔符是英文逗号
5.是否允许带引号?:如果是False,请求中保留引号(默认),如果是True,请求中去掉引号
遇到文件结束符再次循环?(Recycle on EOF):
True 表示循环:一般保持默认True
False 就取消循环
Edit:在没有参数的时候会根据定义的内容来调用函数或变量
遇到文件结束符结束进程?Stop thread on EOF?:
值不够,是否停止线程,不停,一般保持默认False
如果设置为True,结束进程,那么“Recycle on EOF?”设置的True将失效
线程共享模式(Sharing mode):
所有线程 ALL Threads【每次迭代,唯一】 (默认值):
结论:
多个线程组取值不一样,
每个线程组内的线程取值也不一样
每次迭代取值不一样,
每次循环取值一样
多个取样器取值一样
当前线程Current thread【每次迭代,顺序】:
结论:
多个线程组取值一样,
每个线程组内的线程取值也一样
每次迭代取值不一样,
每次循环取值一样
多个取样器取值一样
当前线程组 Current thread group:
结论:
多个线程组取值一样,
每个线程组内的线程取值不一样
每次迭代取值不一样,
每次循环取值一样
多个取样器取值一样
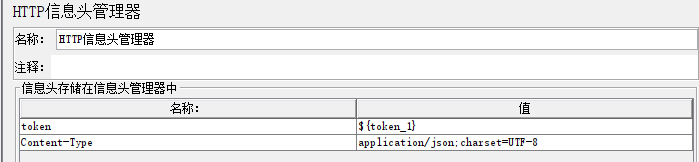
1.3.2 HTTP信息头管理器
比如:content-type:application/json
1.3.3 HTTP Cookie管理器
UI端请求:建议加上
比如:登录完了有cookie,重定向时没有cookie,就又跳转到登录页面
1.3.4 HTTP请求默认值
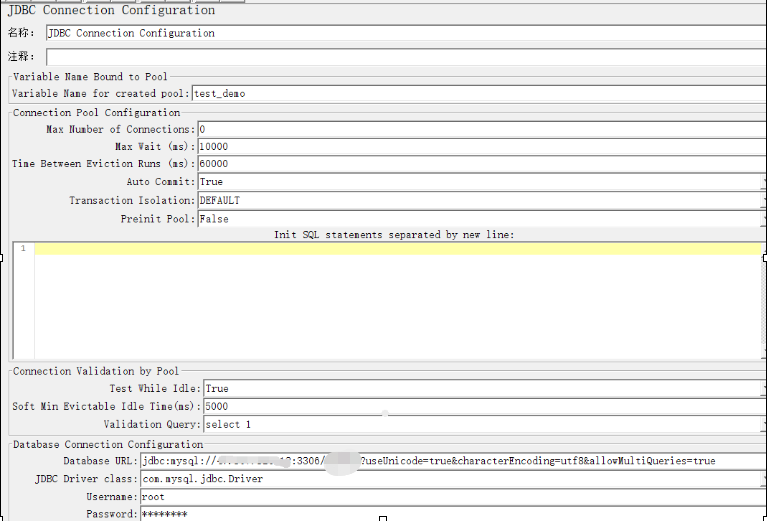
1.3.5 JDBC Connection Configuration
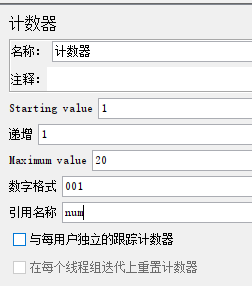
1.3.6 计数器
1.4 前置处理器(Pre Processors)
BeanShell预处理程序
1.5 定时器(Timer)【不建议使用】
1.5.1 高斯随机定时器:
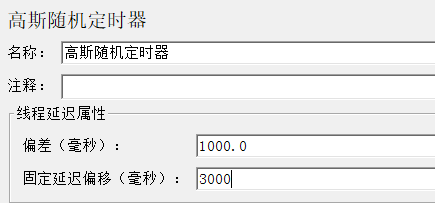
1000-3000:
偏差1000,固定延迟偏移2000
取值范围:3000-1000 或3000+1000
1.5.2 同步定时器(集合点)
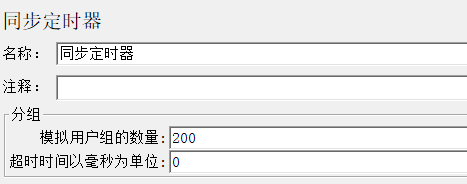
超时时间为0就永远等待
固定定时器
1.6 取样器
1.6.1 http请求
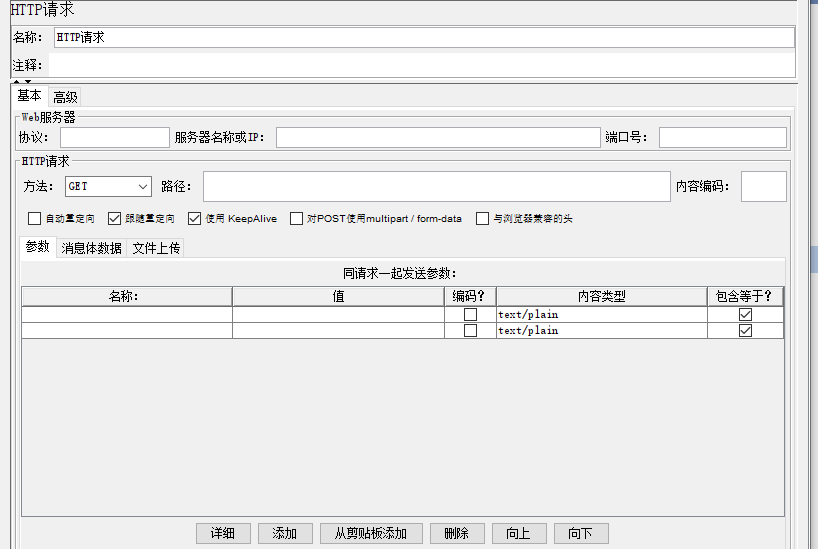
重定向:
- 自动重定向:不传cookie信息
- 跟随重定向:自动把上一次请求的header中的cookie信息传过去
User keepalive 长链接
长链接:
1.高级--实现改为httpclient4 设置链接和响应超时时间
2.jmeter.properties
2.1 打开httpclient.reset_state_on_thread_group_iteration=false
2.2
#httpclient4.idletimeout=60000
#httpclient4.idletimeout=1000
#httpclient4.time_to_live=60000
Use multipart/form-data for POST:表单和json互斥,可以和文件上传一起使用
参数Parameters:
设置url请求参数
编码?Encode:当参数值中有特殊字符时,最好选上“编码”,否则字符串可能会被截断
包含等于?Include Equals:自动添加参数名和值之间的等号
消息体数据Body data:设置post消息体
文件上传Send Files:发送文件相关设置
客户端实现
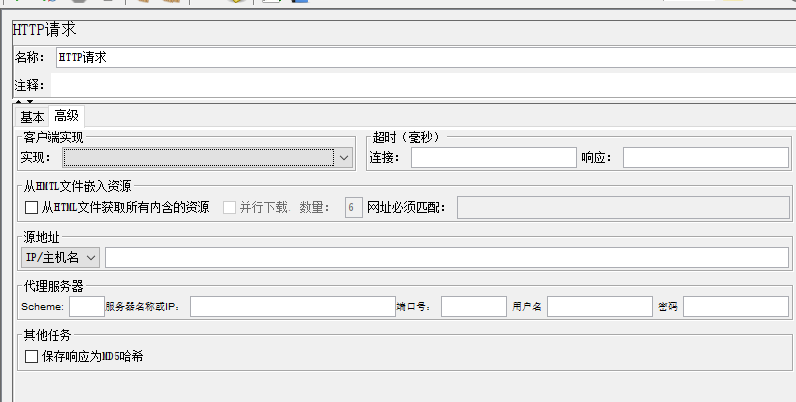
其中有三个选项:空值、HTTPCLient4、Java
- JAVA:使用JVM提供的HTTP实现
- HTTPClient4:使用Apache的HTTP组件HttpClient4.x实现 (和User keepalive结合使用,设置链接和响应超时时间)
- 空值:如果为空,则依赖HTTP Request默认方法,或在jmeter.properties文件中的jmeter.httpsample定义的值
差异:httpclient4每次连接都会重新建立tcp连接,适合模拟真实场景
1.6.2 其他取样器
jp@gc-Dummy Sampler
BeanShell取样器
调试器取样器
JDBC Request
1.7 后置处理器
jmeter关联的五种方式:
- 正则表达式提取器
- jp@gc - JSON Path Extractor提取器
- Json Extractor提取器
- 边界提取器
- beanshell后置处理器
1.7.1 正则表达式提取器
1.7.1.1 正则表达式:
基础:
. 匹配除"\r\n"之外的任何单个字符。要匹配包括""\r"\n"在内的任何字符,请使用像"[\s\S]"的模式。(\s是指空白,包括空格、换行、tab缩进等所以的空白,而\S刚好相反,这样一正一反就表示所有的字符),[a-z]
* 匹配前面的子表达式(也可以是一个字符)任意次。例如zo"能匹配z",也能匹配"zo"以及"zoo"。等价于o{0,}
+ 匹配前面的子表达式一次或多次(大于等于1次)。例如,"zo+"能匹配"zo"以及"zoo",但不能匹配"z"。+等价于{1,}
? 匹配前面的子表达式零次或一次,例如,"do(es)?" 可以匹配"do"或"does"中的"do"。等价于{0,1}
\w 字母、数字、下划线、汉字
\d 数字
{n} 重复n次 a{2}--aa
{n,} 重复>=n次
{n,m} 重复n到m次
说明:注意:限定符只对其前面一个字符起作用
组合:
.* 具有贪婪的性质,匹配到不能匹配为止,最大匹配原则
*? +? 表示非贪婪匹配,即尽可能少的匹配,最小匹配原则
.*? 表示在能匹配成功的前提下尽可能少的匹配,最小匹配原则
常用:
.*? \d \s \S\s \s+
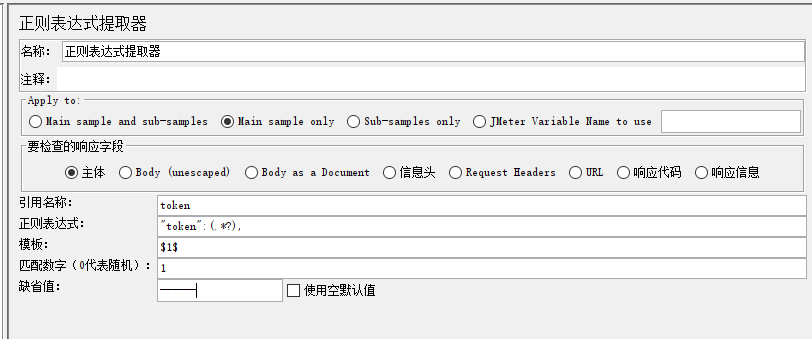
1.7.1.2 详解
要检查的响应字段:用得最多的是【主体】,其次是【信息头】
主体:header+body,可以从header,也可以从body取值
响应信息:http响应代码对应得响应信息,例如:HTTP/1.1 200 ok 取值为ok
引用名称:变量名,由用户指定,最好有意义
正则表达式:
- 用来获取服务器响应值的正则表达式
- 括起来的部分就是要提取的
- 写法(大部分情况有效):左边界(.*?)右边界
模板:填写的是位置变量$N$,或者是常量字符串,如果正则表达式需要提取多个值这里可以写多个:$1$$2$...
匹配数字:
- 0表示随机取值
- 1表示第一个,正整数代表提取第几个匹配的内容,模板中每个模板都取第一个
- -1代表全部取值,此时提取结果是一个数组,哪怕结果只有一个值(如果匹配第一个,除了数字选择1,还可以通过${token_1}的方式来取第1个匹配的内容,${token_2}来取第2个匹配的内容,token是引用名称)
缺省值:如果参数没有取得到值,那默认给一个值让它取,最好是有特征的,方便出错的时候看报错信息,比如:----------
1.7.1.3 例子
{
"data": {
"orderId": "10000${__Random(100,999,num)}",
"balanceFlag": true,
"waitPayAmount": 0
},
"respMsg": "success",
"respCode": "200"
}
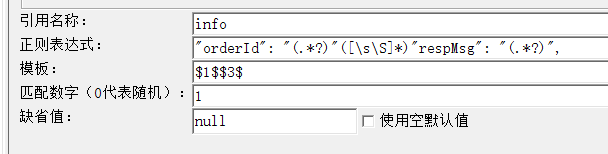
取出orderId和respMsg 只用一个表达式
答案:"orderId": "(.*?)"([\s\S]*)"respMsg": "(.*?)",
1.7.2 调试后置处理程序 Debug PostProcessor
用于调试
放在取样器下面
查看结果树--响应数据,里面的JMeterVariables,要引用,都可以${变量名}的方式获取
1.7.3 jp@gc-JSON/YAML Path Extractor
1.7.3.1 符号说明
- $,表示根节点
- @,当前节点
- .或者[]用于连接父子节点
- ..深层扫描
- *通配符
- [?(表达式)]
- [start:end],切片
- ==~ 正则匹配
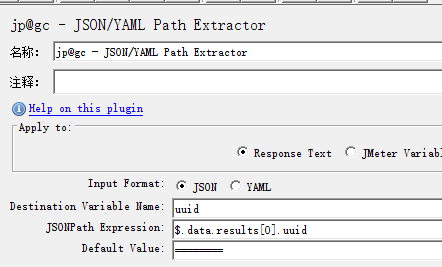
1.7.3.2 获取数组下的第一个uuid
1.7.3.3 获取前三个uuid和showname
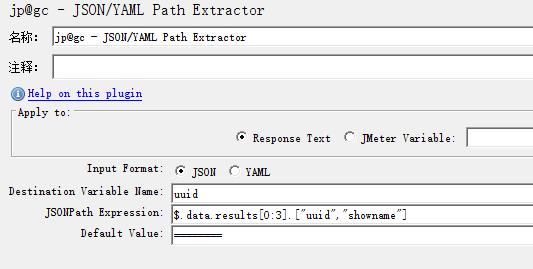
1.7.3.4 深层扫描
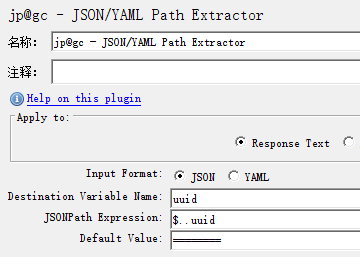
1.7.3.5 获取数组中所有的uuid
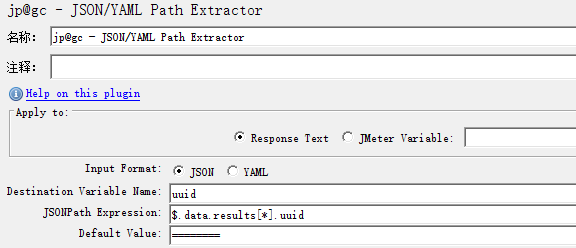
1.7.3.6 根据条件获取值
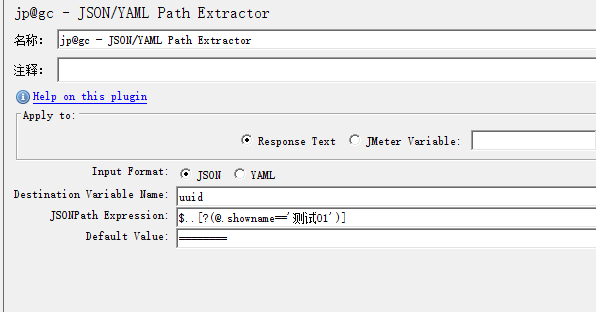
1.7.3.7 根据部分数据获取值(正则模糊匹配)
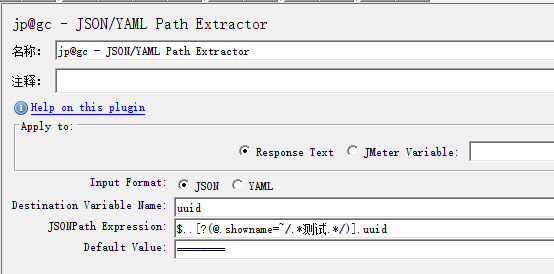
1.7.4 BeanShell后置处理程序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号