常用的几种java集合类总结
一:直观框架图
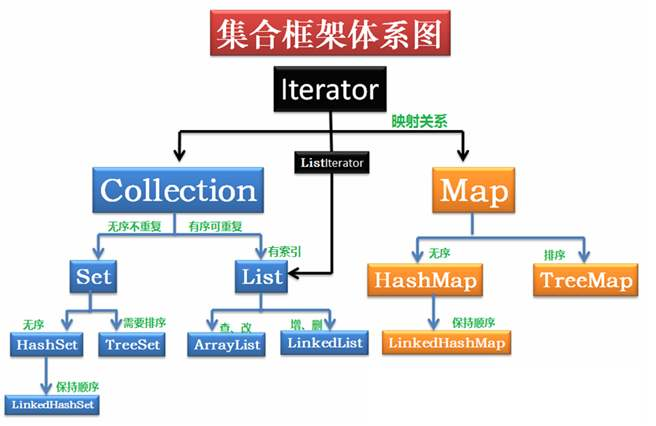
Java集合框架主要包括两种类型的容器,一种是集合(Collection),另一种是图(Map)。Collection接口又有3种子类型,List、Set和Queue,再下面是一些抽象类,最后是具体实现类,常用的有ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap等等。Map常用的有HashMap,LinkedHashMap等。
二、Collection接口
1.List:
List接口扩展自Collection,它可以定义一个允许重复的有序集合,从List接口中的方法来看,List接口主要是增加了面向位置的操作,允许在指定位置上操作元素,同时增加了一个能够双向遍历线性表的新列表迭代器ListIterator。
1.1ArrayList和LinkedList:
链表和数组的最大区别在于它们对元素的存储方式的不同导致它们在对数据进行不同操作时的效率不同,同样,ArrayList与LinkedList也是如此,实际使用中我们需要根据特定的需求选用合适的类,如果除了在末尾外不能在其他位置插入或者删除元素,那么ArrayList效率更高,如果需要经常插入或者删除元素,就选择LinkedList。
Arraylist是基于动态数组实现的,所以查找速度快,但是增删操作的速度会比较慢,但是为什么会这样?
动态数组中,存储数据用的是一段连续的大内存,所以如果我们要在某一个位置添加或者删除一个元素,剩下的每个元素都要相应地往前或往后移动。如果该动态数组中的元素很多,那么,每当我们添加或删除一个元素后,需要移动的元素就非常多,因此,效率就比较低。而查找的时候,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。
这就是为什么ArrayList的查找效率高,而增删操作的效率低了。
LinkedList是基于双向链表的数据结构实现的,链表是可以占用一段不连续的内存空间的,双向链表有前驱节点和后驱节点,里面存储的是上一个元素和后一个元素所在的位置,当我们需要执行插入的任务,比如第一个元素和第二个元素之间,只需要改变他们的前驱节点和后驱节点的指向就可以了,不要像动态数组那么麻烦,删除也是同样的操作,但是因为是不连续的内存空间,当需要执行查找,需要从第一个元素开始查找,直到找到我们需要的数据。
这就是为什么LinkedList查找效率低,增删效率更高。
上面的分析也能看出,其实LinkedList更加节省内存空间,而ArrayList需要预留部分空间出来增加数据。
2.Set:
Set接口扩展自Collection,它与List的不同之处在于,规定Set的实例不包含重复的元素。在一个规则集内,一定不存在两个相等的元素。AbstractSet是一个实现Set接口的抽象类,Set接口有三个具体实现类,分别是散列集HashSet、链式散列集LinkedHashSet和树形集TreeSet。
2.1.Hashset
散列集HashSet是一个用于实现Set接口的具体类,可以使用它的无参构造方法来创建空的散列集,也可以由一个现有的集合创建散列集。在散列集中,有两个名词需要关注,初始容量和客座率。客座率是确定在增加规则集之前,该规则集的饱满程度,当元素个数超过了容量与客座率的乘积时,容量就会自动翻倍。
2.2LinkedHashSet
LinkedHashSet是用一个链表实现来扩展HashSet类,它支持对规则集内的元素排序。HashSet中的元素是没有被排序的,而LinkedHashSet中的元素可以按照它们插入规则集的顺序提取。
2.3TreeSet
树形集是一个有序的Set,其底层是一颗树,这样就能从Set里面提取一个有序序列了。
3.Queue
队列是一种先进先出的数据结构,元素在队列末尾添加,在队列头部删除。Queue接口扩展自Collection,并提供插入、提取、检验等操作。
poll()与remove()方法都是移除队列头部的元素,两者的区别在于如果队列为空,那么poll()返回的是null,而remove()会抛出一个异常。方法element()与peek()主要是获取头部元素,不删除。
接口Deque,是一个扩展自Queue的双端队列,它支持在两端插入和删除元素,因为LinkedList类实现了Deque接口,所以通常我们可以使用LinkedList来创建一个队列。PriorityQueue类实现了一个优先队列,优先队列中元素被赋予优先级,拥有高优先级的先被删除。
三、Map接口
1.HashMap:
见我之前的博客https://www.cnblogs.com/lgn1998/p/12519861.html
2.LinkedHashMap
LinkedHashMap继承自HashMap,它主要是用链表实现来扩展HashMap类,HashMap中条目是没有顺序的,但是在LinkedHashMap中元素既可以按照它们插入图的顺序排序,也可以按它们最后一次被访问的顺序排序。
3.TreeMap
TreeMap基于红黑树数据结构的实现,键值可以使用Comparable或Comparator接口来排序。TreeMap继承自AbstractMap,同时实现了接口NavigableMap,而接口NavigableMap则继承自SortedMap。SortedMap是Map的子接口,使用它可以确保图中的条目是排好序的。
在实际使用中,如果更新图时不需要保持图中元素的顺序,就使用HashMap,如果需要保持图中元素的插入顺序或者访问顺序,就使用LinkedHashMap,如果需要使图按照键值排序,就使用TreeMap。
4.ConcurrentHashMap
Concurrent,并发,从名字就可以看出来ConcurrentHashMap是HashMap的线程安全版。同HashMap相比,ConcurrentHashMap不仅保证了访问的线程安全性,而且在效率上与HashTable相比,也有较大的提高。
e.g.HashMap线程不安全的原因:
1、put的时候导致的多线程数据不一致。
2、HashMap的get操作可能因为resize而引起死循环(cpu100%):当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表,接下来再想通过get()获取某一个元素,就会出现死循环。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号