
SQL必知必会
先来几张图


前言
@author lgj
在读电子版<<SQL必知必会>> 第4版时,做了下笔记。供以后自己或者其他学习者参考。
电子版<<SQL必知必会>>和书中使用的数据库和表的源代码,
请参看地址:https://github.com/thinkingfioa/Notes/tree/master/sql/SQL%E5%BF%85%E7%9F%A5%E5%BF%85%E4%BC%9A4
评价 本书适合入门,对数据库查询部分讲解的比较好,之后的增删改以及数据库的其他特性讲解的并不出众,需要配合其他资料进一步学习。
第2课 检索数据
2.3 检索多个列
select column1, column2, column3 from tableName;
2.4 检索所有的列
select * from products;
注:
1. 缺点:使用通配符(*),除非确实需要查询表的每一列,否则可能会降低检索和应用的性能.
2. 优点:能检索出表的不明确的列。
2.5 检索不同的值
select distinct vend_id from products;
注:
1. distinct关键字作用于作用于其后的所有的列,不仅仅是其后的一列。
2. 如:select distinct vend_id,prod_price from products;那么这两列vend_id, prod_price都同,才会合并。
2.6 限制结果
- select prod_name from products limit 2; 返回结果只有2行。
- select prod_name from products limit 2 offset 5; 返6,7这2行数据。
- select prod_name from products limit 2 offset 5; 可以简写成 select prod_name from products limit 5,2;
注:
1. 第一个被检索的行是第0行,而不是第1行。因此,LIMIT 1 OFFSET 1会检索第2行,而不是第1行.
2. MySQL和MariaDB支持简化版的LIMIT 4 OFFSET 3语句,即LIMIT 3,4。
2.7 使用注释
- 单行注释: #
- 多行注释: /*. ... */
第3课 排序检索数据
使用Select子句的Order by子句,根据需要检索排序出的数据
3.1 排序数据
使用Order by语句排序Select检索出来的语句, Order by子句取一个或多个列的名字。
select prod_name, prod_price from products order by prod_price;
注:Order by子句, 必须是select的最后一条语句。
3.2 按多个列排序
select prod_name, prod_price, prod_id from products order by prod_price, prod_name;
3.3 按列位置排序
select prod_name, prod_price, prod_id from products order by 2, 3;
注:
1. order by 后面可以接数字,比如:2代表的是prod_price, 3代表的是prod_id。不推荐使用这种方式。
3.4 指定排序方向
ASC 升序(默认),DESC 降序。
- select prod_name, prod_price, prod_id from products order by prod_price DESC, prod_name;
- 如果DESC降序,必须对所有需要降序的列都要加上。
第4课 过滤数据
4.2.3 范围值检查
- select prod_name, prod_price, prod_id from products where prod_price between 4 and 10;
4.2.4 空值检查
- select * from customers where cust_email is NULL; 空判断过滤数据
- select * from customers where cust_email is not NULL; 非空判断过滤数据
is null: 当列的值是 null,此运算符返回 true。
is not null: 当列的值不为 null, 运算符返回 true。
<=>: 比较操作符(不同于=运算符),当比较的的两个值为 null 时返回 true。
关于 null 的条件比较运算是比较特殊的。你不能使用 = null 或 != null 在列中查找 null 值 。
在 mysql 中,null 值与任何其它值的比较(即使是 null)永远返回 false,即 null = null 返回false 。
第5课 高级数据过滤
5.1.3 组合where子句
- OR操作符和AND操作符。
select prod_name, prod_price, vend_id from products where vend_id = '1001' OR vend_id = '1005' and prod_price >= 10;
结果:
| prod_name | prod_price | vend_id |
|---|---|---|
| .5 ton anvil | 5.99 | 1001 |
| 1 ton anvil | 9.99 | 1001 |
| 2 ton anvil | 14.99 | 1001 |
| JetPack 1000 | 35.00 | 1005 |
| JetPack 2000 | 55.00 | 1005 |
分析:
OR操作符和AND操作符优先级不同。AND操作符的优先级 > OR操作符的优先级。所以上面的sql变成了:
select prod_name, prod_price, vend_id from products where vend_id = '1001' OR (vend_id = '1005' and prod_price >= 10 );
5.2 IN操作符
- select prod_name, prod_price, vend_id from products where vend_id in ('1001', '1003') order by prod_price DESC;
IN操作符的优点
- IN操作符一般比一组OR操作符更快
- IN最大的优点是:可以包含其他SELECT语句,能够动态的建立WHERE子句,如下:
select a.* from student a join score b on a.s_id=b.s_id where b.c_id in(select c_id from course where t_id =(select t_id from teacher where t_name = '张三'));
5.3 NOT操作符
Not操作符用作否定其后所跟的任何条件。
- select * from products where Not vend_id = 1001 and prod_name = 'Safe';
| prod_id | vend_id | prod_name | prod_price | prod_desc |
|---|---|---|---|---|
| SAFE | 1003 | Safe | 50.00 | Safe with combination lock |
| 注:Not在这里只能作用与vend_id. |
第6课 使用通配符进行过滤
6.1.1 百分号(%)通配符
在搜索串中,%表示任何字符出现任意次数。代表搜索模式中给定位置0个,1个,多个字符。排除匹配NULL的行。
- select prod_id, prod_name from products where prod_name like 'Jet%';
6.1.2 下划线(_)通配符
在搜索串中,下划线(_)只匹配单个字符,而不是多个字符。只能是一个字符。
- select prod_id, prod_name from products where prod_name like 'JetPack _000';
6.1.3 方括号([])通配符
只有微软的Access和SQL server支持。
6.2 使用通配符的技巧
- 要知道,使用通配符可能比其他的搜索耗费更长的时间,对数据库的压力更大。
- 不要过度使用通配符,在其他操作符能达到效果的情况下,尽量不要使用通配符。
- 尽量不要把通配符放在搜索模式的开始处,把通配符置于开始处,搜索起来最慢的。
第7课 创建计算字段
7.1 计算字段
计算字段是运行时在SELECT语句内创建的。不同于数据库中表的列
7.2 拼接字段
将表中的列数据,拼接到一起。将值联结在一起(将一个值附加到另一个值), 构成单个值。如:prod_name(prod_price).
拼接的操作符:
1. Access和SQL Server使用+号
2. DB2、Oracle、PostgreSQL、SQLite和Open Office Base使用||
3. MySQL和MariaDB中,必须使用特殊的函数。eg: concat(prod_name, '(', prod_price, ')')
Trim函数
1. RTRIM(String)函数去掉字符串右边的空格。
2. LTRIM(String)函数去掉字符串左边的空格。
3. TRIM(String)函数去掉字符串左边和右边空格。
As别名。重新为列起一个新的名字。
1. select concat(prod_name, '(', vend_id, ')') as price_info from products;
7.3 执行算术计算
算术运算符:加,减,乘,除
计算商品共卖出多少钱
1. select prod_id, quantity, item_price, quantity * item_price as expanded_price from orderitems where order_num = 20005;
第8课 使用数据处理函数
8.1 函数
SQL中函数,各个DBMS所支持的都不同,如果使用过多的函数,可能会带来可移植问题。
8.2 使用函数
大部分SQL实现支持以下类型的函数
1. 用于处理文本字符串(如删除,填充值,转换大小写等)的文本函数。
2. 用于在数值数据上进行的算术操作(如返回绝对值,进行代数运算)的数值函数。
3. 用于处理日期和时间值,并从这些值中提取特定成分(如返回两个日期之差,检查日期有效性)的日期和时间函数。
4. 返回DBMS正使用的特殊信息(如返回用户登录信息)的系统函数。
8.2.1 文本处理函数
常见的文本处理函数
| 函数 | 说明 |
|---|---|
| LEFT()(或使用子字符串函数) | 返回字符串左边的字符 |
| RIGHT()(或使用子字符串函数) | 返回字符串右边的字符 |
| LOWER()(Access使用LCASE()) | 将字符串转换为小写 |
| UPPER()(Access使用UCASE()) | 将字符串转换为大写 |
| LTRIM() | 去掉字符串左边的空格 |
| RTRIM() | 去掉字符串右边的空格 |
| TRIM()、去掉字符串左边和右边的空格 | |
| SOUNDEX() | 返回字符串的SOUNDEX值(读音相同) |
| LENGTH()(也使用DATALENGTH()或LEN()) | 返回字符串长度 |
解释文本处理函数:SOUNDEX()
SOUNDEX()函数是一种和根据读音相同来比较的
1. SELECT cust_name, cust_contact FROM Customers WHERE SOUNDEX(cust_contact) = SOUNDEX('Michael Green');
8.2.2 日期和时间处理函数
非常遗憾的是:日期和时间处理函数在SQL实现中差别很大,可移植性非常差。所以,关于具体DBMS支持的日期-时间处理函数,请参阅相应的文档。
8.2.3 数值处理函数
数值处理函数仅处理数值数据,这些函数一般主要用于代数、三角或几何运算。数值处理函数在SQL差别不大。
| 函数 | 说明 |
|---|---|
| ABS() | 返回一个数的绝对值 |
| COS() | 返回一个角度的余弦 |
| EXP() | 返回一个数的指数值 |
| PI() | 返回圆周率 |
| SIN() | 返回一个角度的正弦 |
| SQRT() | 返回一个数的平方根 |
| TAN() | 返回一个角度的正切 |
第9课 汇总数据
9.1 聚集函数
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
9.1.1 AVG()函数
AVG函数计算表中列的平均值。AVG()只能用来确定特定数值列的平均值.AVG函数忽略列值为NULL的行。
- select avg(prod_price) as avg_price from products;
9.1.2 COUNT()函数
COUNT函数有两种实现方式:
1. 使用count(*),对表中行的数目进行计数。无论是空值(NULL)或非空值。
2. 使用count(columnName)对表特定列具有值进行计数,忽略NULL值。
3. select count(vend_state) from vendors;语句忽略NULL值。
9.1.3 MAX()函数
MAX()返回指定列中的最大值。
- select max(prod_price) as max_price from products;
9.1.4 MIN()函数
MIN()的功能正好与MAX()功能相反,它返回指定列的最小值。
9.1.5 SUM()函数
SUM()用来返回指定列值的和(总计)。
- select sum(item_price) as sum_price from orderitems where order_num = 20005;
- select sum(item_price*quantity) as total_price from orderitems where order_num = 20005;
注: 利用标准的算术运算符,所有的聚集函数都可以执行多个列上的计算。
9.2 聚集不同的值
使用关键字: DISTINCT关键字,过滤相同的值。
- select avg(distinct prod_price) as avg_price from products where vend_id = 'DLL01';
9.3 组合聚集函数
select 语句可以根据需要包含多个聚集函数。
- select count(*) as num_items, min(prod_price) as min_price, max(prod_price) as max_price, sum(prod_price) as sum_price from products;
第10课 分组数据
将数据分组,使用Group by子句和Having子句。
10.1 数据分组
目前为止的所有计算都是在表的所有数据或匹配特定的WHERE子句的数据上进行的。没有对应的分组概念。
- select count(*) as num_prods from products where vend_id = 'DLL01';
如果查询每个供应商提供的商品数,怎么查?答:需要使用分组,Group by子句和Having子句
10.2 创建分组
分组是使用select语句的Group by实现的。
- select vend_id, count(*) num_prods from products group by vend_id;
使用group by子句分组数据,然后对每个组而不是整个结果集进行聚集。
使用GROUP BY子句前,需要了解一些重要的规定:
1. GROUP BY子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致的进行分组。
2. GROUP BY子句嵌套了分组,数据将在最后指定的分组上进行汇总。
3. GROUP BY子句中列出的每一列必须是检索列或有效的表达式。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
4. 大多数SQL实现不允许GROUP BY列带有长度可变的数据类型。
5. 除聚集计算语句外,SELECT语句中的每一列都必须在GROUP BY子句中给出。
6. 如果分组列中包含具有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
7. GROUP BY子句必须出现在WHERE子句之后,Order by子句之前。
10.3 过滤分组
Group by新建分组,使用Having子句过滤分组。如:查询至少有两个订单的顾客。
Where 子句和Having 子句的区别:
1. Where子句过滤的是行,而Having子句过滤的是分组。
2. Having子句可以替代Where子句,但是不建议这样做。
- select vend_id, count() as num_prods from products where prod_price >= 4 group by vend_id having count() > 2;
分析:首先,where语句先选出价格大于4的商品,然后按照vend_id来进行分组,再对分组进行过滤。
10.4 分组和排序
| Order by | Group by |
|---|---|
| 对产生的输出排序 | 对行分组,但输出可能不是分组的顺序 |
| 任意列都可以使用 | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
| 语句的末尾 | 一般在join和where后面 |
一般使用GROUP BY子句后,也应该使用ORDER BY子句。
10.5 Select子句的顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
第11课 使用子查询
11.2 利用子查询进行过滤
假如需要列出订购物品RGAN01的所有顾客,应该怎样检索?
1. 从订单详情表(OrderItems)中查询订购物品GRANO1的所有订单编号。
2. 根据订单编号,从表(Orders)中查询顾客ID
3. 根据顾客ID,从表(Customers)查询顾客信息。
select cust_name, cust_contact from customers
where cust_id IN (select cust_id from Order
where order_num IN (select order_num from OrderItems
where prod_id = 'GRANO1'));
作为子查询的Select语句只能查询单个列(cust_id、order_num)。企图查询多个列,是错误的。
11.3 作为计算字段使用子查询
假如需要显示Customers表中每个顾客的订单总数,应该怎样写?
1. 从Customers表中检索顾客列表。
2. 对于检索的每个顾客,统计在Orders表中的数目。
select cust_name, cust_state,
(select count(*) from Orders
where Orders.cust_id = Customers.cust_id) AS orders
from Customers order by cust_name;
该子查询检索到每个顾客执行一次。
第12课 联结表
12.1.1 关系表
关系表的设计就是把信息分成多个表,一类数据一个表。各个表通过共同的值进行关联。
12.2 创建联结
当from子句后接多个表时候,表示联结产生了。select子句后面所接的字段,分别来自于两个表中。
1. select vend_name, prod_name, vend_city, vendors.vend_id from vendors, products where vendors.vend_id = products.vend_id;
如果没有Where子句,那么返回结果就是笛卡尔积。
三者是等价的
select a.*,b.c_id,b.s_score from student a inner join score b on a.s_id=b.s_id;
select a.*,b.c_id,b.s_score from student a join score b on a.s_id=b.s_id;
select a.*,b.c_id,b.s_score from student a,score b where a.s_id=b.s_id;
12.2.3 联结多个表
select prod_name, vend_name, prod_price, quantity from OrderItems, Products, Vendors
where Products.vend_id = Vendors.vend_id
And OrderItems.prod_id = Products.prod_id
And order_num = 20007;
第13课 创建高级联结
13.1 使用表别名
使用表别名优点:
1. 缩短SQL语句
2. 允许在一条select语句中多次使用相同的表
select cust_name, cust_contact from Customers AS C, Orders AS O, OrderItems AS OI
where C.cust_id = O.cust_id and OI.order_num = O.order_num and prod_id = 'RGAN01'
13.2 使用不同类型的联结
四种联结: 1. 内联结或等值联结, 2. 自联结(self-join), 3. 自然联结(natural join), 4. 外联结(outer join)。
13.2.1 自联结
问:查询与Y Lee同一公司的所有顾客。
1. 使用子查询
select cust_name, cust_address from customers where cust_name = (select cust_name from customers where cust_contact = 'Y Lee')
2. 使用自联结
select C1.cust_name, C2.cust_address from customers as C1, customers as C2 where C1.cust_name = C2.cust_name and C1.cust_contact = 'Y Lee'
用自联结而不用子查询:
1. 许多DBMS处理联结远比处理子查询快得多。
13.2.2 自然联结
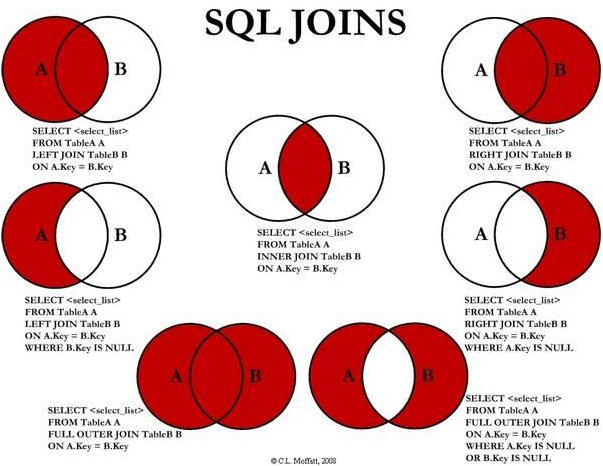
13.2.3 外联结
许多联结将一个表中的行和另一个表中的行相关联,但有时候需要包含没有关联行的那些行。如,以下工作:
1. 对每个顾客订单进行计数,包括至今尚未下订单的顾客。
2. 列出所有产品以及订购数量,包括没人订购的产品。
上述举例,包括了那些相关表中没有关联的行。这种联结称为外联结。
检索所有顾客及其订单
1. 内联结(inner join):
select Customers.cust_id, Orders.order_num from Customers inner join Orders on Customers.cust_id = Orders.cust_id;
2. 外联结(left outer join):
select Customers.cust_id, Orders.order_num from Customers left outer join Orders
on Customers.cust_id = Orders.cust_id;
外联结的使用的是left outer join是从左边的表(Customers)中选择行,所以如果右表没有对应的id则补充。要注意on后面的表Customers和Orders顺序。
3. 外联结(right outer join)
select Customers.cust_id, Orders.order_num from Customers right outer join Orders on Orders.cust_id = Customers.cust_id;
4. 全外联结(full outer join)
select Customers.cust_id, Orders.order_num from Orders full out join Customers
on Orders.cust_id = Customers.cust_id;
两个表的行的最大集合。
参考 https://www.cnblogs.com/dinglinyong/p/6656315.html
13.3 使用带聚集函数的联结
检索所有顾客及每个顾客所下的订单数
select Customers.cust_id, count(Orders.order_num) AS num_ord
from Customers inner join Orders on Customers.cust_id = Orders.cust_id
group by Customers.cust_id;
13.4 使用联结和联结条件
联结和联结的使用要点:
1. 注意使用的联结类型。有内联结,外联结等
2. 联结语法每个DBMS可能不一样。
3. 保证使用正确的联结条件,否则返回不正确的数据。
4. 应该总是使用联结条件,否则会得到笛卡尔积。
5. 在一个联结中可以包含多个表,甚至可以对每个联结采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们 前分别测试每个联结。这会使故障排除更为简单。
第14课 组合查询
利用UNION操作符将多条Select语句合成一个结果集。
14.1 组合查询
SQL 允许执行多条查询语句(多条Select语句),并将结果作为一个查询结果集返回。
主要有两种情况需要使用组合查询:
1. 在一个查询中,从不同的表返回结构数据。
2. 对一个表执行多个查询,按一个查询返回数据。
注:一般多个Where子句的Select语句都可以作为一个组合查询。也就是说将Where子句拆分开来。
14.2 创建组合查询
用操作符UNION操作符组合多条Select语句,将他们的结果组合成一个结果集。
14.2.1 使用UNION操作符
查询Illinois、Indiana和Michigan等美国几个州的所有顾客的报表,和不管位于哪个州的所有的Fun4All
1. 使用UNION操作符查询。
select cust_name, cust_contact, cust_email from Customers
where cust_state in ('Illinois','Indiana','Michigan')
UNION
select cust_name, cust_contact, cust_email from Customers
where cust_name = 'Fun4All';
2. 使用Where子句
select cust_name, cust_contact, cust_email from Customers
where cust_state in ('Illinois','Indiana','Michigan') or cust_name = 'Fun4All'
Union和Where子句比较:
1. 对于较复杂的过滤条件,或者从多个表(而不是一个表)中检索数据的情形,使用UNION可能会使处理更简单。
2. 多数DBMS使用内部查询优化程序,使用Union关键字会在内部组合它们,所以性能几乎无差别。但使用Union操作符也请注意下性能问题。
14.2.2 UNION规则
Union非常好用,但使用组合前请注意下以下规则:
1. UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔。
2. UNION每次查询必须包含相同的列,表达式,聚集函数。(各个列不需要以相同的次序列出)。
3. 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含转换的类型。
14.2.3 包含或取消重复的行
UNION从查询结果集中自动去除了重复的行。
使用关键字:Union All的会返回所有的匹配行(不进行去除重复的行)。
Union All操作符是Where不能替代的。
14.2.4 对组合查询结果排序
用Union组合查询时,只能使用一条Order by子句,它必须位于最后一条Select语句。
- select cust_name, cust_contact, cust_id from customers
where cust_state in ('MI', 'OH')
union
select cust_name, cust_contact, cust_id from customers
where cust_contact = 'E Fudd'
order by cust_id;
注意:union组合查询中order by子句的列必须在select后面有。且order by必须在语句最后,对整个结果集进行排序。
14.2.5 sql执行顺序总结
sql 不同于与其他编程语言的最明显特征是处理代码的顺序。在大数编程语言中,代码按编码顺序被处理,但是在sql语言中,第一个被处理的子句是from子句,尽管select语句第一个出现,但是几乎总是最后被处理。
每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只是最后一步生成的表才会返回给调用者。如果没有在查询中指定某一子句,将跳过相应的步骤。下面是对应用于sql server 2000和sql server 2005的各个逻辑步骤的简单描述。
(8)select (9)distinct (11)<top num> <select list>
(1)from [left_table]
(3)<join_type> join <right_table>
(2)on <join_condition>
(4)where <where_condition>
(5)group by <group_by_list>
(6)with <cube | rollup>
(7)having <having_condition>
(10)order by <order_by_list>
逻辑查询处理阶段简介:
from:对from子句中的前两个表执行笛卡尔积(cartesian product)(交叉联接),生成虚拟表vt1
join on:对vt1应用on筛选器。只有那些使<join_condition>为真的行才被插入vt2。join分为cross join、inner join、[left join、right join,full join]
outer(join):如果指定了outer join(相对于cross join 或(inner join),保留表(preserved table:左外部联接把左表标记为保留表,右外部联接把右表标记为保留表,完全外部联接把两个表都标记为保留表)中未找到匹配的行将作为外部行添加到 vt2,生成vt3.如果from子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表为止。
where:对vt3应用where筛选器。只有使<where_condition>为true的行才被插入vt4.和join中的on筛选类似,只是比on筛选器执行的晚.
group by:按group by子句中的列列表对vt4中的行分组,生成vt5.
cube|rollup:把超组(suppergroups)插入vt5,生成vt6.
having:对vt6应用having筛选器。只有使<having_condition>为true的组才会被插入vt7.过程和on、where类似,只能用在group by 之后。
select:处理select列表,产生vt8.
distinct:将重复的行从vt8中移除,产生vt9.
order by:将vt9中的行按order by 子句中的列列表排序,生成游标(vc10).
limit/top:从vc10的开始处选择指定数量或比例的行,生成表vt11,并返回调用者。
标准的 sql 的解析顺序为:
(0).from 子句, 组装来自不同数据源的数据
(1).join on 拼接多个表
(2).where 子句, 基于指定的条件对记录进行筛选
(3).group by 子句, 将数据划分为多个分组
(4).使用聚合函数进行计算
(5).使用 having 子句筛选分组
(6).计算所有的表达式
(7).使用 order by 对结果集进行排序
举例说明:
在学生成绩表中 (暂记为 tb_grade), 把 "考生姓名"内容不为空的记录按照 "考生姓名" 分组, 并且筛选分组结果, 选出 "总成绩" 大于 600 分的.
标准顺序的 sql 语句为:
select 考生姓名, max(总成绩) as max总成绩
from tb_grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
在上面的示例中 sql 语句的执行顺序如下:
(1). 首先执行 from 子句, 从 tb_grade 表组装数据源的数据
(2). 执行 where 子句, 筛选 tb_grade 表中所有数据不为 null 的数据
(3). 执行 group by 子句, 把 tb_grade 表按 "学生姓名" 列进行分组
(4). 计算 max() 聚集函数, 按 "总成绩" 求出总成绩中最大的一些数值
(5). 执行 having 子句, 筛选课程的总成绩大于 600 分的.
(7). 执行 order by 子句, 把最后的结果按 "max 成绩" 进行排序.
重点注意:
where和having的区别,
join需要注意用on,
like、=、is null的区别 还有null与空格的区别
order by的局限
group by如何在count等命令下分组
第15课 插入数据
利用SQL的INSERT语句将数据插入表中。
15.1.1 插入完整的行
使用insert语句时,请在表名括号内明确给定列名。
1. insert into Customers(cust_id,cust_name, cust_address, cust_city, cust_state, cust_zip, cust_country, cust_contact, cust_email)
VALUES
('1000000006','Toy Land','123 Any Street','New York','NY','11111','USA',NULL, NULL);
15.1.3 插入检索出的数据
将Select语句的查询结果插入到表中。顾名思义,它是由一条INSERT语句和一条SELECT语句组成的。
insert into
Customers(cust_id, cust_contact,cust_email,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country)
select
cust_id,cust_contact,cust_email,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country
from CustNew;
说明:将select语句查询出来的结果,插入到表Customers中.
注意:
1. insert 和select不一定要求列名匹配。它使用的是列的位置,因此SELECT中的第一列(不管其列名)将用来填充表列中指定的第一列,第二列将用来填充表列中指定的第二列。
2. insert 通常只插入一行。但insert select是个例外,它可以用一条insert插入多行,不管select语句返回对少条语句,都会被插入到表中。
15.2 从一个表复制到另一个表
select into将数据复制到一个新表中。
insert select与select into区别:
1. insert select是导出数据,先select出结果,然后插入到表中。select into是导入数据。
select * into CustCopy from customers;
创建一个名为CustCopy的新表。然后将整个customers表内容复制到表CustCopy中。
Mysql中语法是:
create table CustCopy AS select * from Customers;
使用select into注意点:
1. 任何select选项和子句都可以使用,包括where和order by。
2. 可利用联结从多个表插入数据(Mysql中未测试通过).
3. 不管从多少个表中检索数据,数据都只能插入到一个表中。
第16课 更新和删除数据
16.1 更新数据
update语句更新表中的数据。
- update Customers set cust_contact = 'Sam Roberts',cust_email = 'sam@toyland.com' where cust_id = '10000006';
注意:update语句可能更新多个值。
16.2 删除数据
delete语句删除表中的数据。
- delete from Customers where cust_id = '10000006'
删除时外键考虑:
1. 使用delete语句删除数据时,可能会有外键的影响。比如:我要删除Products表中某个商品,但是该商品cust_id在订单表中有记录,作为订单表的外键。那么删除会失败。
16.3 更新和删除的指导原则
- 除非确实删除所有行或更新所有行,否则绝不能不使用where语句。
- 保证每个表都要有主键,尽可能像where子句那样使用它。
- 在update和delete语句使用where子句前,应该先用select进行测试,保证过滤条件是正确无误的。
- 使用强制实施引用完整性的数据库,这样DBMS将不允许删除其数据与其他表相关联的行。
第17课 创建和操纵表
该课主要讲解:创建,更改和删除表的基本知识。表的创建是很有学问的,本书中的内容并不丰富还需要查一些其他资料。
17.1.1 表创建基础
利用create table创建表,必须给出下列信息:
1. 新表的名字,在关键字create table后给出.
2. 表列的名字和定义,用逗号隔开。
3. 有的DBMS还要指定表的位置。
CREATE TABLE IF NOT EXISTS `runoob_tbl`(
`runoob_id` INT UNSIGNED AUTO_INCREMENT,
`runoob_title` VARCHAR(100) NOT NULL,
`runoob_author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
实例解析:
如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
ENGINE 设置存储引擎,CHARSET 设置编码。
17.1.2 使用Null
创建表的时候,指定表的列为Not null,则表示,以后执行insert语句,该列必须有值,不接受null。
17.1.3 指定默认值
创建表的时候,可以为表的列提供默认值。
- create table OrderItems
(
order_num INTEGER Not null,
order_item INTEGER Not null,
prod_id CHAR(10) Not null,
quantity INTEGER Not null default 1,
item_price DECIMAL(8,2) not null
);
17.2 更新表
使用alter table时,请考虑下列的事:
1. 理想情况下,不要再表包含数据时对其进行更新。应该在表的设计过程中充分烤炉未来可能。
2. 所有的DBMS都允许给现有的表增加列,不过对所增加列的数据类型(以及NULL和Default的使用)有所限制.
3. 许多DBMS不允许删除或更改表中的列.
- alter table Vendors add vend_phone CHAR(20);
复杂的表结构更改一般需要手动删除过程,它涉及以下步骤:
1. 用新的列布局创建一个新表;
2. 使用INSERT SELECT语句从旧表复制数据到新表。有必要的话,可以使用转换函数和计算字段;
3. 检验包含所需数据的新表;
4. 重命名旧表(如果确定,可以删除它);
5. 用旧表原来的名字重命名新表;
6. 根据需要,重新创建触发器、存储过程、索引和外键
17.3 删除表
- drop table Customers;
注意:删除表不可撤销。请慎重
17.4 重命名表
每个DBMS对表重命名的支持有所不同,具体要参考具体的DBMS文档.
第18课 使用视图
18.1 视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
理解视图的最好方法是看例子.
select cust_name, cust_contact from Customers, Orders, OrderItems
where Customers.cust_id = Orders.cust_id
and OrderItems.order_num = Orders.order_num
and prod_id = 'RGAN01';
该句sql检索订购了某种商品的顾客。任何需要这个数据的人必须理解这些表与表之间的关系。
假如将整个查询包装成一个名为ProductsCustomers的虚拟表。那么sql可以简化为:
select cust_name, cust_contact from ProductCustomers where prod_id = 'RGANO1';
总结:视图不包含任何的列或数据,包含的是一个查询。
18.1.1 为什么使用视图
视图的常见使用场景:
1. 重用SQL语句。
2. 简化复制的SQL操作。在编写查询后,可以方便的使用它,而不必知道具体的细节。
3. 使用表的一部分,而不是整个表。
4. 保护数据。可以授予用户访问表的特定部分,而不是表的全部权限。
5. 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
创建视图后,可以用表相同的方式去使用它们。可以对视图执行select操作,过滤和排序数据,将视图联结到其他视图或表等。
再次强调:视图只是包含了动态检索数据的查询。
18.1.2 视图的规则与限制
不同的DBMS中视图的限制和规则可能不同,具体请参考文档。
视图的创建和使用的一些最常见的规则和限制:
1. 与表一样,视图必须唯一命名,名字不能有冲突。
2. 对于可以创建的视图数目没有限制。
3. 创建视图,必须具有足够的访问权限。
4. 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造视图。所允许的嵌套层数在不同的DBMS中有所不同(嵌套视图可能会严 重降低查询的性能,因此在产品环境中使用之前,应该对其进行全面测试)。
5. 许多DBMS禁止在视图查询中使用ORDER BY子句。
6. 有些DBMS要求对返回的所有列进行命名,如果列是计算字段,则需要使用别名。
7. 视图不能索引,也不能有关联的触发器或默认值。
8. 有些DBMS把视图作为只读的查询,这表示可以从视图检索数据,但不能将数据写回底层表。
18.2 创建视图
Create view语句来创建视图。
18.2.1 利用视图简化复杂的联结
视图最常见的应用:隐藏复杂的SQL
create view ProductCustomers AS
select cust_name, cust_contact, prod_id
from Customers, Orders, OrderItems
where Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num;
然后调用sql查询:
select cust_name, cust_contact from ProductCustomers where prod_id = 'RGANO1';
18.2.2 用视图重新下格式化检索的数据
视图另一个常见的应用: 重新格式化检索出的数据
create view VendorLocations AS
select RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')'
AS vend_title from Vendors;
在单个组合计算列中返回供应商名和位置
18.2.3 用视图过滤不想要的数据
可以定义一个视图:过滤没有电子邮件地址的顾客
create view CustomerEMailList AS
select cust_id, cust_name, cust_email
from Customers where cust_email is not Null;
18.2.4 使用视图与计算字段
在简化计算字段的使用上,视图也特别有用。
create view OrderItemsExpanded AS
select order_num, prod_id, quantity, item_price, quantity*item_price AS expanded_price
from OrderItems
第19课 使用存储过程
19.1 存储过程
1. 通俗的讲,存储过程就是类似于C的一个方法。
2. 简单的说,存储过程就是为以后使用而保存一条或多条SQL语句。可以将其视为批文件,但它的作用不仅限于批处理。
19.2 为什么使用存储过程
- 存储过程有3个优点:简单,安全和高性能。
- 多数DBMS的存储过程可能不同,而且存储过程也比较复杂,难于编写。
19.3 执行存储过程
使用关键字execute来执行存储过程
EXECUTE AddNewProduct( 'JTS01', 'Stuffed Eiffel Tower', 6.49,'Plush stuffed toy with the text");
AddNewProduct是一个存储过程,将一个新的商品添加到Product表中。但我们发现,最重要的字段prod_id列没有,应为我们想统一化规格化生成对应的prod_id.
所以,该存储过程需要做以下3件事:
1. 验证传递的数据,保证所有4个参数都有值;
2. 生成用作主键的唯一ID;
3. 将新产品插入Products表,在合适的列中存储生成的主键和传递的数据。
19.4 创建存储过程
创建存储过程,每个DBMS差别很大,具体需要参考DBMS文档。
第20课 管理事务处理
- 使用事务处理,确保成批的SQL操作要么完全执行,要么完全不执行,来保证数据库的完整性。
- 事务处理是一种机制,用来管理必须成批执行的SQL操作,保证数据库不可能包括不完整的操作结果。
- 事务都应该具备ACID特征。所谓ACID是Atomic(原子性),Consistent(一致性),Isolated(隔离性),Durable(持久性)四个词的首字母所写,
在使用事务时,需要理解几个关键字:
1. 事务(transaction)指一组SQL语句.
2. 回退(rollback)指撤销指定SQL语句的过程。
3. 提交(commit)指将未存储的SQL语句结果写入数据库表。
4. 保留点(savepoint)指事务处理中设置的临时占位符(placeholder),可以对它发布回退。
哪些sql语句可以回退?
答:Insert, Delete和Update语句可以回退。Select, Drop和Create语句不能回退。
20.2 控制事务处理
管理事务的关键在于将SQL语句组合成逻辑块,并规定数据何时回退,何时不应该回退。
不同的DBMS实现事务处理的语法不同:
1. SQL Server
Begin Transaction
...
Commit Transaction
在这里Begin Transaction和Commit Transaction之间的SQL必须完全执行,或完全不执行。
2. Mysql
Start Transaction
...
Commit
3. Oracle
Set Transaction
...
Commit
20.2.1 使用Rollback
SQL 使用Rollback来回退(撤销)SQL命令
命令:delete from Orders; Rollback;
使用Delete语句,然后使用Rollback语句撤销。该句能充分说明:在事务处理块中,delete操作(insert操作和update操作)并不是最终的结果。
20.2.2 使用Commit
在事务处理块中,提交必须时显示提交。
删除订单12345,所以需要同时更新两个数据库表Orders表和OrderItems表。
1. Mysql中
Begin Transaction
delete OrderItems where order_num = 12345;
delete Orders where order_num = 12345;
Commit Transaction
2. Oracle中
Set Transaction
delete OrderItems where order_num = 12345;
delete Orders where order_num = 12345;
Commit;
上面的事务处理块中同时更新两个表中的记录,事务保证了操作的一致性,不可能出现部分删除。
20.2.3 使用保留点
保留点(savepoint)作用是:支持回退部分事务。
例如添加一个订单,需要插入顾客信息,插入订单信息,订单详情信息,但当插入订单详情时发生错误,只需要回退到插入订单信息,不需要回退到插入顾客信息。这是就需要回退部分事务。
保留点使用:在编写事务过程中,需要在事务处理块中的合适位置放置占位符。用于后面的回退。
不同的DBMS的保留点设置不同
1. Mysql
Savepoint delete1;
2. SQL Server
Save Transaction delete1;
不同的DBMS的回退保留点的方式不同
1. Mysql
Rollback to delete1;
2. SQL Server
Rollback transaction delete1;
20.3 SQL Server事务举例
不同的DBMS可能不同,但是总体概念和流程都是相同的。
Begin Transaction
insert into Customers(cust_id, cust_name) values('1000000010', 'Toys Emporium');
save transaction StartOrder;
insert into Orders(order_num, order_date, cust_id) values(20100,'2001/12/1','1000000010');
IF @@ERROR <> 0 Rollback Transaction StartOrder;
insert into OrderItems(order_num, order_item, prod_id, quantity, item_price)
values(20100, 1, 'BR01', 100, 5.49);
IF @@ERROR <> 0 Rollback Transaction StartOrder;
insert into OrderItems(order_num, order_item, prod_id, quantity, item_price)
values(20100, 2, 'BR03', 100, 10.99);
IF @@ERROR <> 0 Rollback Transaction StartOrder;
Commit Transaction;
第21课 使用游标
21.1 游标
SQL检索结果是返回一组称为结果集的行。但是无法从结果集中得到第一行,下一行或前10行的数据。但是大多数Web应用开发人员不使用游标,而是根据自己的需要开发相应的功能。如:利用limit1, 10来实现分页查询, 或使用foreach来实现遍历。
游标的用途:
有时,需要在检索出来的行中前进或后退一行或多行,就需要使用游标。
游标(cursor)是一个存储在DBMS服务器上的数据库查询,它不是一条SELECT语句。在存储了游标之后,应用程序可以根据需要滚动或浏览数据集中的数据。
游标在不同的DBMS中的一些共性:
1. 能够标记游标为只读,使数据能读取,但不能更新和删除。
2. 能控制可以执行的定向操作(向前、向后、第一、最后、绝对位置、相对位置等)。
3. 能标记某些列为可编辑的,某些列为不可编辑的。
4. 规定访问范围,使游标对创建它的特定请求(如存储过程)或对所有请求可访问。
5. 指示DBMS对检索出的数据(而不是指出表中活动数据)进行复制,使数据在游标打开和访问期间不变化。
21.2 使用游标
使用游标的几个明确的步骤:
1. 在使用游标前,必须定义它。这个过程实际上没有检索数据,它只是定义要使用的SELECT语句和游标。
2. 一旦定义,就必须打开游标以供使用。这个过程用前面定义的SELECT语句把数据实际检索出来。
3. 对于填有数据的游标,根据需要取检索各行。
4. 在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具体的DBMS)。
21.2.1 创建游标
使用Declare语句创建游标。
创建一个游标来检索没有电子邮件地址的所有顾客.
1. Mysql + SQL Server
Declare CustCursor Cursor for
Select * from Customers where cust_email is null;
2. Oracle
Declare Cursor CustCursor is
Select * From Customers where cust_email is null;
21.2.2 使用游标
游标的使用场景并不多,该节笔记比较粗糙。
使用OPEN CURSOR语句打开游标
1. Open Cursor CustCursor;
使用Fetch语句访问游标数据。
Fetch需要指出检索哪些行,从何处检索他们以及将他们存放于何处。
Declare Type CustCursor IS ref Cursor
Return Customers%ROWTYPE;
Declare CustRecord Customers%ROWTYPE
Begin
Open CustCursor;
Fetch CustCursor INTO CustRecord;
Close CustCursor;
End;
21.2.3 关闭游标
1. Oracle
Close CustCursor;
2. SQL Server
Close CustCursor
Deallocate Cursor CustCursor;
第22课 高级SQL特性
22.1 约束
- 约束: 管理如何插入或处理数据库数据的规则。
- 引用完整性(referential integrity): 利用键来建立从一个表到另一个表的引用
关系型数据库,需要保证插入数据库的数据和合法性。
例如:如果Orders表存储订单信息,OrderItems表存储订单详细内容,应该保证OrderItems中引用的任何订单ID都存在于Orders中。类似地,在Orders表中引用的任意顾客必须存在于Customers表中。
DBMS通过在数据库表上施加约束来实施引用完整性.
22.1.1 主键
主键是一种特殊的约束,用来某一行的数据是唯一的,而且主键永不改动。
表中的列只要满足以下条件,可用于主键:
1. 任意两行的主键值都不相同。
2. 每行都具有一个主键值(即列中不允许NULL值)。
3. 包含主键值的列从不修改或更新。
4. 主键值不能重用。如果从表中删除某一行,其主键值不分配给新行。
主键的创建:
1. Create Table
Create Table Vendors
(
vend_id CHAR(10) NOT NULL Primary Key,
vend_name CHAR(50) NOT NULL,
vend_address CHAR(50) NULL,
vend_city CHAR(50) NULL,
vend_state CHAR(5) NULL,
vend_zip CHAR(10) NULL,
vend_country CHAR(50) NULL
);
Primary Key声明表的主键列
2. Alter Table
Alter Table Vendors
Add Constraint Primary Key(vend_id);
22.1.2 外键
外键是表中的一列,其值必须在另一表的主键列中。
外键是关系数据库描述表和表之间依赖关系
1. Create Table
Create Table Orders
(
order_num Integer not null primary key,
order_date DateTime not null,
cust_id char(10) not null references Customers(cust_id)
);
2 Alter Table
Alter Table Orders
Add Constraint Foreign key (cust_id) references Customers(cust_id);
外键的作用:
1. 能够帮组保证引用完整性。
2. 防止意外删除记录
由于顾客表Customers表中主见: cust_id,作为订单表Orders中的外键。所以如果想直接删除顾客表中的记录,必须保证其值已经不被订单表中依赖。
3. 级联删除
Mysql支持级联删除特性。解释:如果从顾客表Customers表中删除某个顾客,那么由于顾客表Customers表中的主见cust_id作为了Orders表中的外键依赖,所以订单表Orders中的该顾客的订单也一并删除。
22.1.3 唯一约束
唯一约束用来保证某一列中的数据是唯一的。它和主键有以下区别:
1. 表可包含多个唯一约束,但每个表只允许一个主键。
2. 唯一约束列可包含NULL值。
3. 唯一约束列可修改或更新。
4. 唯一约束列的值可重复使用。
5. 与主键不一样,唯一约束不能用来定义外键。
22.1.4 检查约束
检查约束用来保证一列中的数据满足一组指定的条件。检查约束的常见用途:
1. 检查最小或最大值。例如,防止0个物品的订单(即使0是合法的数)。
2. 指定范围。例如,保证发货日期大于等于今天的日期,但不超过今天起一年后的日期。
3. 只允许特定的值。例如,在性别字段中只允许M或F。
对OrderItems表施加了检查约束,保证所有物品的数量大于0:
CREATE TABLE OrderItems
(
order_num INTEGER NOT NULL,
order_item INTEGER not null,
prod_id CHAR(10) not null,
quantity INTEGER not null check (quantity > 0),
item_price MONEY not null
);
检查名为gender的列只包含M或F
Alter Table OrderItems
Add Constraint Check (gender LIKE '[MF]')
22.2 索引
索引是利用B+等索引机制,加快查询和排序的速度。
使用索引需要记住以下内容:
1. 索引提高检索操作的性能,但降低了数据插入、修改和删除的性能。因为数据变更需要更新索引。
2. 索引数据可能要占用大量的存储空间。
3. 并非所有数据都适合做索引。查询量非常大,列的数据非常多,使用使用索引。
4. 索引用于数据过滤和数据排序。如果你经常以某种特定的顺序排序数据,则该数据可能适合做索引。
5. 可以在索引中定义多个列(例如,州加上城市)。这样的索引仅在以州加城市的顺序排序时有用。
所以必须唯一命名:
Create Index prod_name_index On Products(prod_name);
22.2.1 索引建立的几大原则
组合索引的解释:
如果创建了(state, city, zip)列作为组合索引,索引中的数据行按照state/city/zip次序排列,
这意味着,这个索引可以被用于搜索如下所示的数据列组合:
state, city, zip
state, city
state
但是MySQL不能利用这个索引来搜索没有包含在最左前缀的内容。例如,如果你按照city或zip来搜索,
就不会使用到这个索引。如果你按照state,和zip来搜索,该索引也是不能用于这种组合值的,但是可以利用索引来查找匹配的state从而缩小搜索的范围。
1. 选择唯一性索引
唯一性索引的值是唯一的,能快速的通过该索引来确定某条记录。
2. 为经常需要排序、分组和联合操作的字段建立索引
经常需要Order By、Group By、Distinct和Union等操作的字段,排序操作会浪费很多时间。
3. 为常作为查询条件的字段建立索引
某个字段经常用来做查询条件,该字段的查询速度会影响整个表的查询速度。使用索引,可以极大加快查询速度。
4. 最左前缀匹配原则,非常重要的原则。
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,
比如state='yes' and city='wuwei' and price > 3 and name = 'ppp' 如果建立(state, city, price, name)顺序的索引,
name的查询是用不到索引的,只能使用部分索引,然后在结果集上面进行排序。如果建立(state, city , ppp, price)的索引则都可以用到,state, city, name的顺序可以任意调整。
5. =和in可以乱序。
比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
但是如果建立索引(a,b,c),结果where子句是:b =2 and c=3,则索引不起作用。
6. 尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。
例如,对一个CHAR(100)类型的字段进行全文检索需要的时间肯定要比对CHAR(10)类型的字段需要的时间要多。
7. 尽量使用前缀来索引
索引字段的值很长,应该采用前缀来索引。
8. 尽量选择区分度高的列作为索引。
数据量区分度越高,索引的比较成本会小很多。
9. 删除不再使用或者很少使用的索引
请定期删除不在使用的索引。
10. 限制索引的数目
使用索引需要付出代价,索引会消耗磁盘空间,对数据库记录的更新和删除产生影响。
11. 索引列不能参与计算。
坚决不能将某个计算函数作为缩影。如:from_unixtime(create_time) = ’2014-05-29’
12. 尽量的扩展索引,不要新建索引。
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
22.3 触发器
触发器是特殊的存储过程,可以在特定的数据库活动发生时自动执行。
触发器可以与特定表上的Insert, Update或Delete操作(或组合)想关联。
如:与Orders表上的Insert操作相关联的触发器只在Orders表中插入行时才会执行。
触发器的常见用途:
1. 保证数据一致。例如,在Insert或Update操作中将所有州名转换为大写。
2. 基于某个表的变动在其他表上执行活动。例如,每当更新或删除一行时将审计跟踪记录写入某个日志表。
3. 进行额外的验证并根据需要回退数据。例如,保证某个顾客的可用资金不超限定,如果已经超出,则阻塞插入。
4. 计算计算列的值或更新时间戳。
不同的DBMS的触发器差距很大,请参考具体文档.
如:创建一个触发器,对所有Insert和Update操作,将Customers表中的cust_state列转换为大写。
1. SQL Server
Create Trigger customer_state On Customers
For Insert, Update As
Update Customers Set cust_state = Upper(cust_state)
2. Oracle
Create Trigger customer_state
After Insert Or Uupdate
For Each Row
Begin
Update Customers
Set cust_state = Upper(cust_state)
Where Customers.cust_id = :OLD.cust_id
end;
22.4 数据库安全
一般对数据保护操作有:
1. 对数据库管理功能(创建表、更改或删除已存在的表等)的访问;
2. 对特定数据库或表的访问;
3. 访问的类型(只读、对特定列的访问等);
4. 仅通过视图或存储过程对表进行访问;
5. 创建多层次的安全措施,从而允许多种基于登录的访问和控制;
6. 限制管理用户账号的能力。

