

Docker的内核,性能与调优
Docker的内核,性能与调优
首先我们抛出3个问题:
- docker容器的内核与宿主机内核是怎样的关系?
- 容器在运行时如何调用系统资源?
- docker的性能参数有没有作用范围?
能够将这3个问题全部解答,关于docker的内核与调优策略便有了一定程度的认识。
一、容器与宿主机的内核关系 —— 共享内核
docker镜像是一个“应用程序和它运行依赖环境”的封装。当镜像运行起来后,即是docker容器。运行时的容器本质是操作系统下的一个进程,这些进程共享同一个宿主机OS的内核。
与传统VM相比,docker是一种操作系统虚拟化技术,并不需要在镜像内安装GuestOS。
docker在共享宿主机内核的基础上包装内核提供的一系列API,这些API中最重要的就是namespace和cgroup。通过namespace实现隔离,通过cgroup实现资源限制。
二、Namespace--命名空间
- PIDnamespace:每当在此空间中启动一个程序,内核就给它分配唯一的ID。与宿主机所见的不同,容器内的进程都有自己的进程ID空间。
- MNTnamespace:每个容器都有自己目录挂载的命名空间。
- NETnamespace:每个容器都有自己单独的网络栈,其中的socket和网卡设备都是其他容器不能访问的。
- UTSnamespace:在此命名空间中的进程拥有自己的主机名和NIS域名。
- IPCnamespace:拥有相同IPC命名空间的进程才可以利用“共享内存、信号量、消息队列”方式进行通信。
- User namespace:用于隔离容器中的UID,GID和根目录
三、Cgroup--控制组
顾名思义,控制、分组,用于对进程进行层次化分组,并以组为粒度实现资源限制和策略控制。每一个容器内的进程都收到组策略的管控。
Cgroup包含了很多控制器。
Cgroup对进程分组的控制是通过一个虚拟文件系统下的目录节点和节点文件实现的,控制器是目录节点中的文件,文件内容规定了系统资源的配额。
以全局cgroup为例 # ls /sys/fs/cgroup
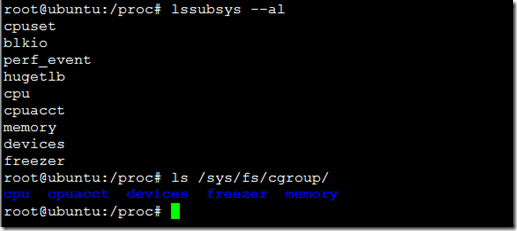
默认的情况下,docker会在这些目录下面创建自己的节点子目录,而每个容器都会创建自己容器ID的节点子目录;这些目录都包含了对应层次的控制器文件,用于控制每一级的资源配额。下文简述一些控制器的功能:
- cpu:限制组中进程的cpu使用量
- cpuacct:对进程的CPU使用程度进行计量
- memory:限制组中进程的内存使用量,并计量
- blkio:限制组中进程对块设备的IO操作
- net_prio:用于设置组相关网络包的优先级
- hugetlb:用于限制和报告组内进程对大页面的使用量
- freezer:用于组内进程的挂起和解冻
四、docker内核与调优
理解了上面的几部分,我们现在应该有个印象:
- docker容器共享宿主机OS的内核
- docker容器视为一个进程
- docker容器的资源配额受docker引擎和宿主机OS限制
所以在进行docker内核调优时,可以推论:
- docker的内核参数大多继承自宿主机内核
- docker容器可以在某些情况、某些范围内调整自己的内核参数
那么某些情况和某些范围指的是什么呢?让我们来分享一些特殊情况
4.1 docker的 --sysctl 参数的白名单
语法:docker run --sysctl key=value IMAGE:TAG CMD
该参数允许docker容器启动时设置某些内核参数,这些参数是有限制的,可以在docker源码中查看到
// docker/opts/opts.go
func ValidateSysctl(val string) (string, error) { validSysctlMap := map[string]bool{
"kernel.msgmax": true, "kernel.msgmnb": true, "kernel.msgmni": true,
"kernel.sem": true,
"kernel.shmall": true,
"kernel.shmmax": true, "kernel.shmmni": true, "kernel.shm_rmid_forced": true,
}
validSysctlPrefixes := []string{
"net.",
"fs.mqueue.",
}
...
如上所示,只有被标识为 True 的 kernel.*, net.* 以及fs.mqueue.* 是可以传入参数并修改的
如果传入其他参数,会提示:for --sysctl: sysctl'kernel.acpi_video_flags=0' is not whitelisted
即白名单未通过
4.2 容器中看不到的参数
通常容器内可以修改的参数,都是可以通过sysctl -a查看到的,但有些则不行:
例如 net.core.rmem_max参数(定义内核用于所有类型的连接的最大接收缓冲大小)
root@host01:~/tmp# sysctl -a | grep rmem_max
net.core.rmem_max = 212992
root@host01:~/tmp# docker run hub.c.163.com/public/debian:7.9 sysctl -a | grep rmem_max
root@host01:~/tmp#原因是这些参数是隶属于kernel的namespace
4.3 不能被namespace化的参数
当一些内核参数在容器中修改后,会反过来作用于宿主机,这一类内核参数的特点是无法被namespace化;因为docker使用共享内核的机制,大多数和kernel相关的参数都有这样的特点:
# step1.检查当前进程数最大值
root@host01:~/tmp# sysctl -a | grep pid_max
kernel.pid_max =32768
# step2.启动一个测试用的容器,--privileged 表示获得root权限
root@host01:~/tmp# docker run -d --privileged --name test hub.c.163.com/public/debian:7.9
a43e89ee85d36e250e0886331e9d6213094f31260eb9e1539b83f0e9cfc91848
# step3.在容器内修改进程数最大值
root@host01:~/tmp# docker exec test sysctl -w kernel.pid_max=86723
kernel.pid_max = 86723
# step4.再次检查进程数最大值,发现变更成了上一步docker容器内设定的值
root@host01:~/tmp# sysctl -a | grep pid_max
kernel.pid_max = 86723引入3中特殊情况对应的图形:
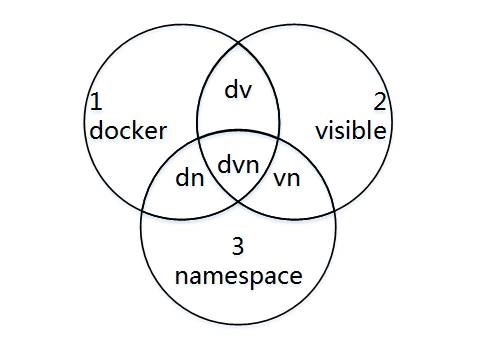 1 doker 表示在白名单内; 2 visible 表示sysctl -a 容器内可见;3 namespace 表示不影响全局
1 doker 表示在白名单内; 2 visible 表示sysctl -a 容器内可见;3 namespace 表示不影响全局
综上,我们可以得出结论:
- 程序白名单以外的参数不可调整;想调整请修改docker源码
- 容器内systcl看不到的继承自宿主机
- 容器内能影响宿主机的不要修改
针对docker容器的内存调优策略:
- 请尽量在宿主机OS进行内核优化操作;
- 需要特化&满足条件的参数请通过 --sysctl参数传入或写入dockerfile
五、操作系统参数调优
限于篇幅,本文对于操作系统的参数调优不再阐述,给与几篇相关扩展阅读:
- 文件句柄数 ulimit -n & /etc/security/limits.conf
- Docker Container继承自Docker Daemon的ulimit设置,也可以修改/etc/sysconfig/docker,指定docker-deamon启动参数
- TCP/IP协议栈优化、内核参数默认值和建议值

