流畅的python第二章序列构成的数组学习记录
python内置序列类型概览

列表推导和生成器表达式
列表推导是构建列表的快捷方式,而生成器表达式可以用来创建其他任何类型的序列
列表推导的示例
>>>test = [i*2 for i in range(3)] >>>test [0,2,4]
使用列表推导通常的原则是,只能列表推导来创建新的列表,并且尽量保持简短。
python2中列表推导可能有变量泄露问题,而python3解决了变量泄露问题
列表推导和map/filter的对比

生成器表达式
虽然也可以用列表推导来初始化元组,数组或其他序列类型,但是生成器表达式是更好的选择。因为生成器表达式背后遵守了迭代器协议,可以逐个的产出元素,而不是先建立一个完整的列表,然后在吧这个列表传递到某个构造函数里。更节省内存
使用生成器表达式初始化元组和数组

元组的使用
元组除了用作不可变的列表,还可以用于没有字段名的记录
元组和记录
元组其实是对数据的记录,元组的每个元组都存放了记录中的一个字段的数据,外加这个字段的位置。
元组拆包

元组拆包可以使用*开帮助我们把注意力集中在元组的部分元素上


元组拆包还可以应用在嵌套结构中
具名元组
collections.namedtuple是一个工厂函数。可以用来构建一个带字段名的元组和一个有名字的类
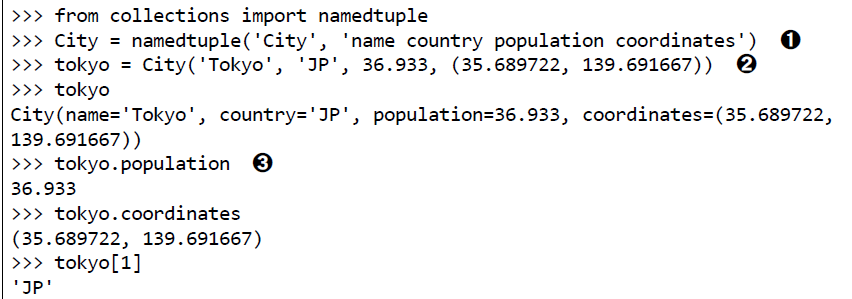
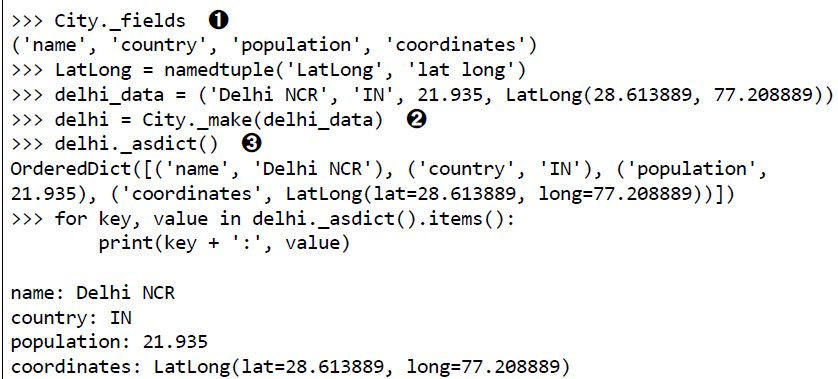
除了从普通元组集成来的属性外,具名元组还有一些自己专有的属性。_fields,_make,_asdict()
不可变列表的元组
除了增减元素相关的方法之外,元组支持列表的其他所有方法。
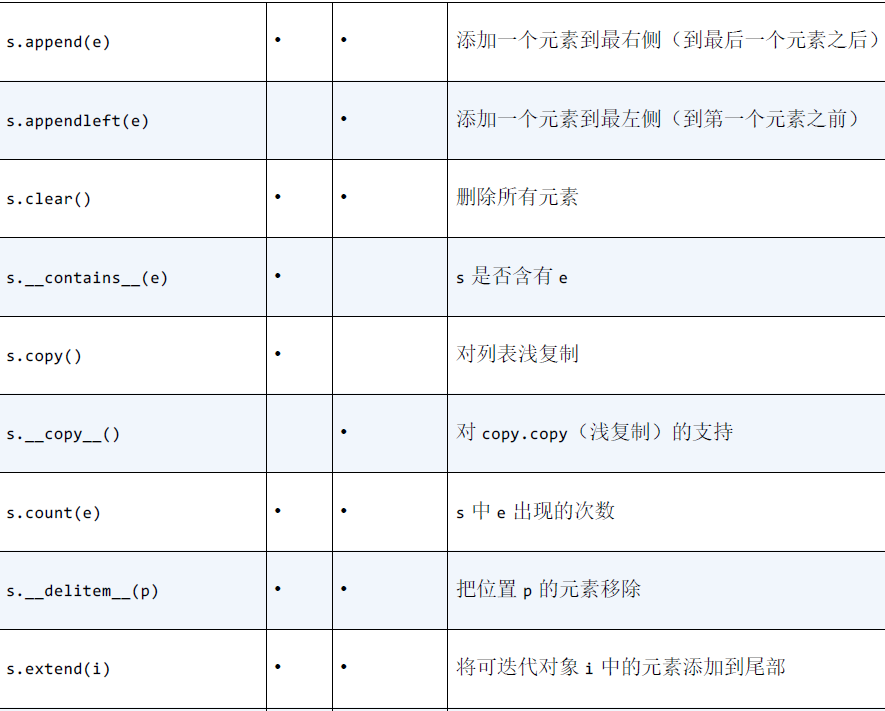
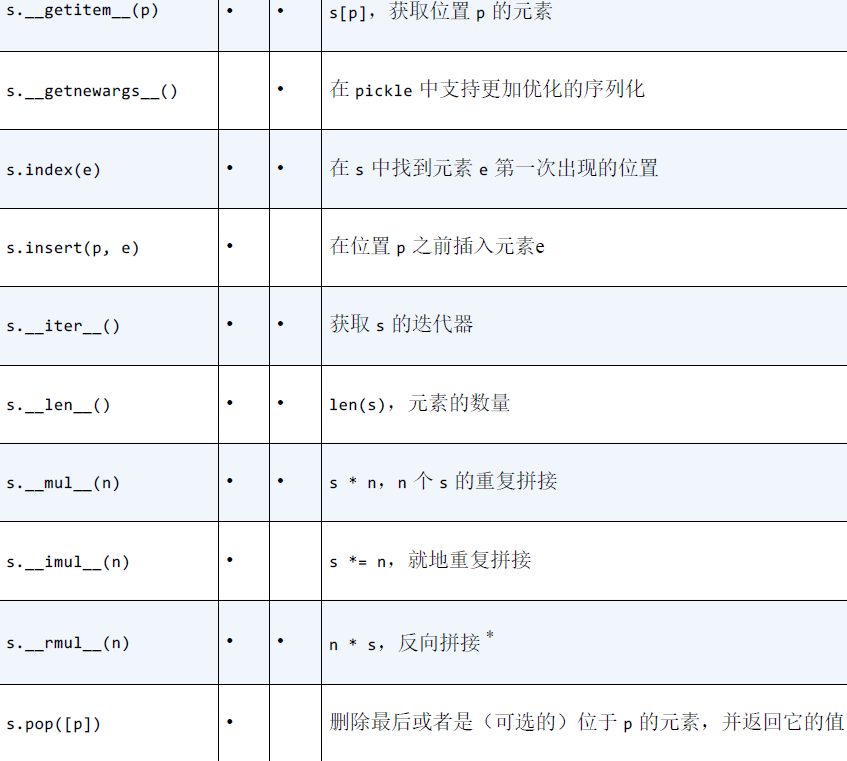
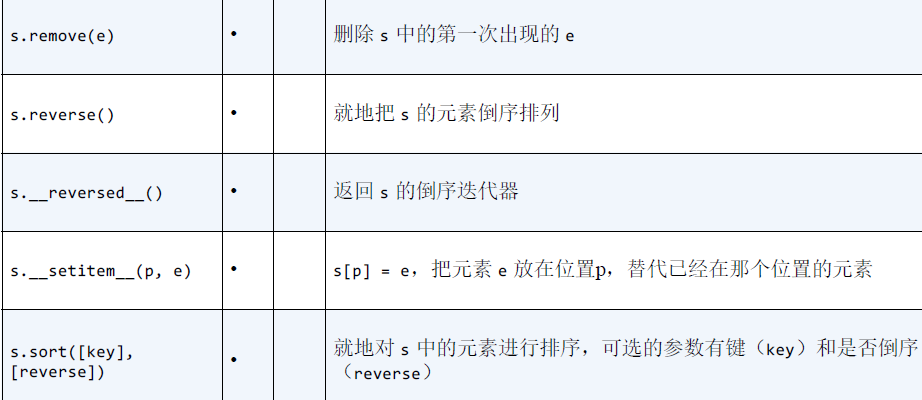
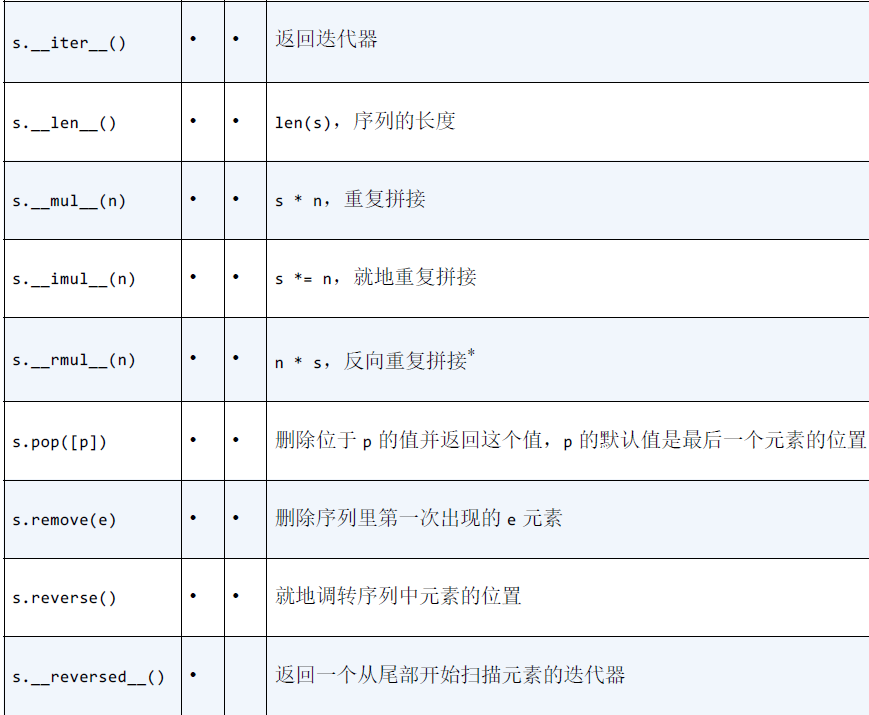
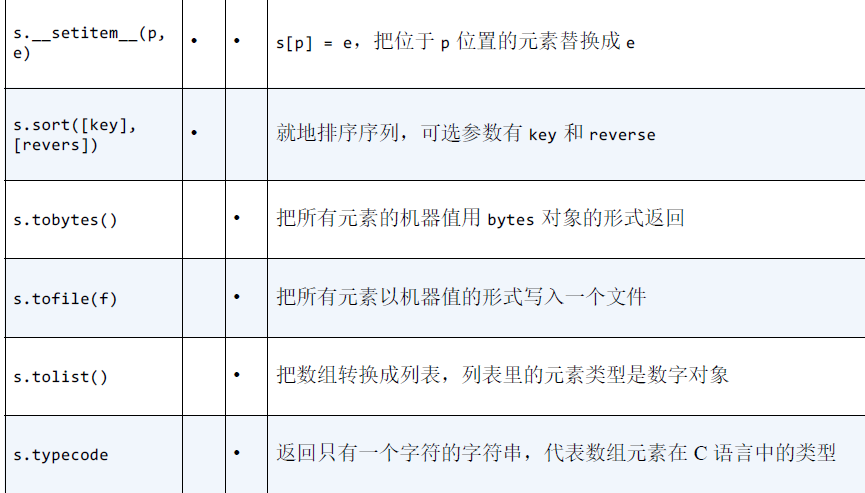
列表或元组的方法和属性

对象切片
s[a:b:c]对s在a和b之间以c为间隔取值,c可以为负,反向取值
多维切片和省略
切片赋值

对序列使用+和*
拼接的过程中,两个被操作的序列都不会被修改,python会新建一个包含同样类型数据的序列作为拼接的结果。
+和*都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列
序列的增量赋值
+=背后的特殊方法是__iadd__但是如果一个类没有实现该方法,python会调用__add__
*=背后的特殊方法是__imul__类似于+=

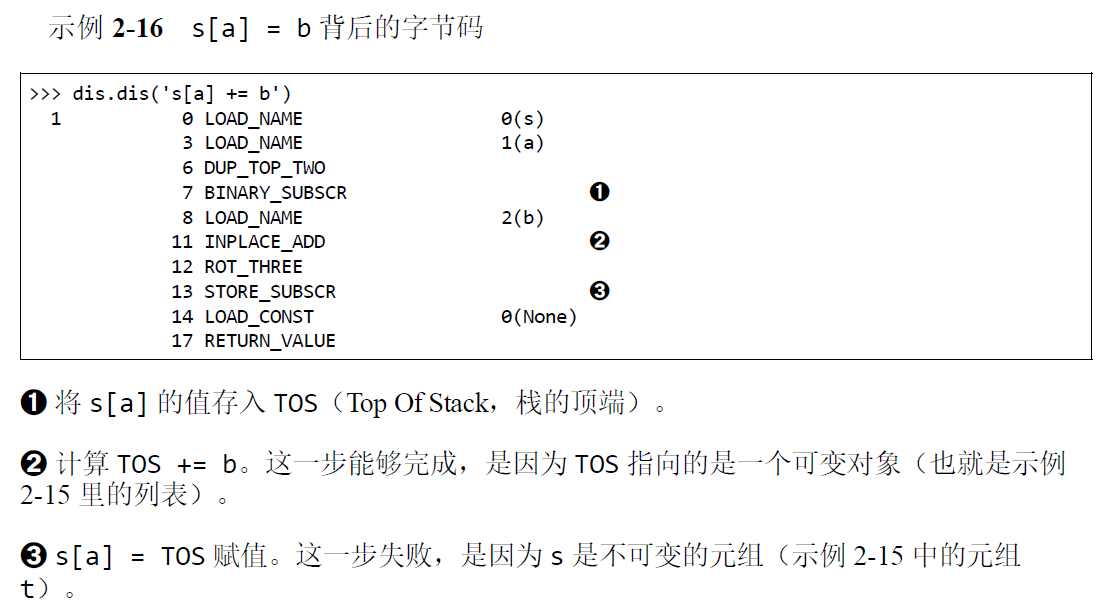
得到的教训
不要把可变对象放在元组里面
增量赋值不是一个原子操作
查看python字节码并不难,他对了解代码背后的运行机制很有帮助
list.sort方法和内置函数sorted
list.sort就地排序,对原列表进行排序并返回None。对原列表直接操作
sorted则不是,会创建新的列表,该列表是原列表进过排序的。
reverse参数,True降序排列,默认False
key参数用于对比的关键字
bisect管理已排序的序列
bisect模块包含两个主要函数,bisect,insort,两个函数都利用二分查找算法来在有序序列中查找或插入元素

bisect.insort(seq,item)将item插入seq中,并保持seq升序排序
数组
如果我们需要一个只包含数字的列表,那么array.array比list更高效,数组支持所有跟可变序列有关的操作。包括pop,insert和extend。另外,数组还提供从文件读取和存入文件的更快的方法frombytes和tofile
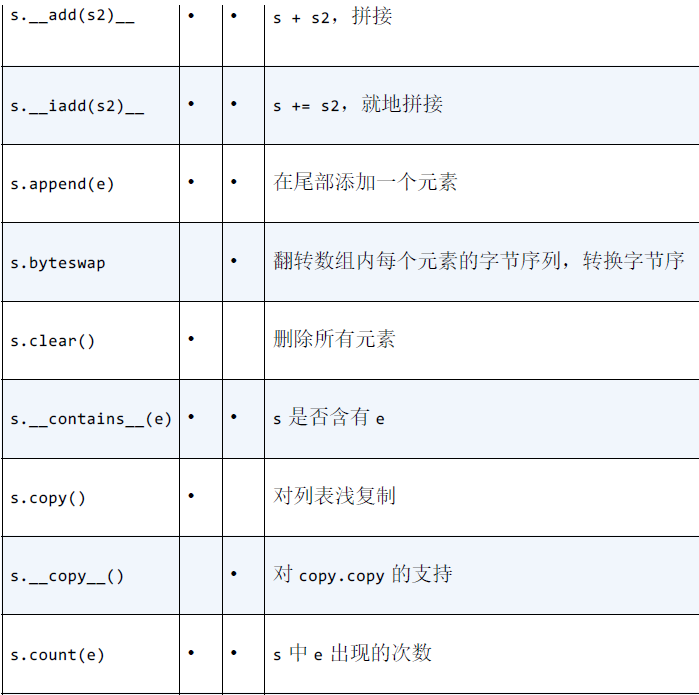
列表和数组的属性和方法


内存视图memoryview
scipy和numpy
双向队列和其他形式的队列
collections.deque类是一个线程安全可以快速从两端添加或者删除元素的数据类型。
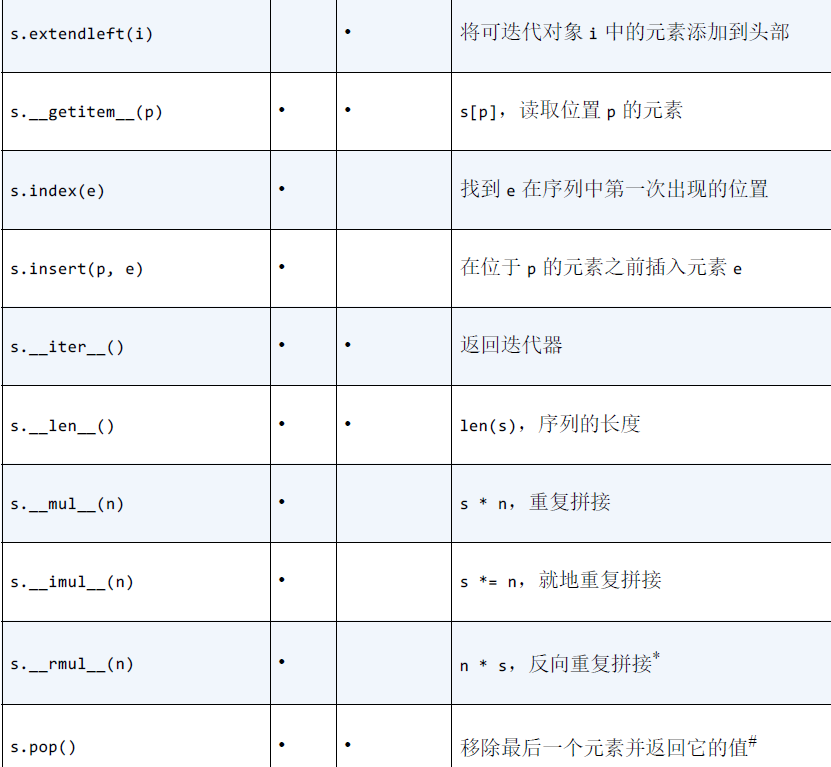
列表和双向队列的方法