
go语言设计与实现-数据结构-阅读笔记
数组
Go 语言中数组在初始化之后大小就无法改变,存储元素类型相同、但是大小不同的数组类型在 Go 语言看来也是完全不同的,只有两个条件都相同才是同一个类型。
func NewArray(elem *Type, bound int64) *Type { if bound < 0 { Fatalf("NewArray: invalid bound %v", bound) } t := New(TARRAY) t.Extra = &Array{Elem: elem, Bound: bound} t.SetNotInHeap(elem.NotInHeap()) return t }
编译期间的数组类型是由上述的 cmd/compile/internal/types.NewArray 函数生成的,类型 Array 包含两个字段,一个是元素类型 Elem,另一个是数组的大小 Bound,这两个字段共同构成了数组类型,而当前数组是否应该在堆栈中初始化也在编译期就确定了。
Go 语言中的数组有两种不同的创建方式,一种是显式的指定数组的大小,另一种是使用 […]T 声明数组,Go 语言会在编译期间通过源代码对数组的大小进行推断
访问数组的索引是非整数时会直接报错 —— non-integer array index %v;
访问数组的索引是负数时会直接报错 —— "invalid array index %v (index must be non-negative)";
访问数组的索引越界时会直接报错 —— "invalid array index %v (out of bounds for %d-element array)"
简而言之:数组包含两部分,一个是元素类型,一个是数组大小。只有两个都相等才是数组才相等。
索引非整数、负数、越界都会报错。
切片
cmd/compile/internal/types.NewSlice 就是编译期间用于创建 Slice 类型的函数
func NewSlice(elem *Type) *Type { if t := elem.Cache.slice; t != nil { if t.Elem() != elem { Fatalf("elem mismatch") } return t } t := New(TSLICE) t.Extra = Slice{Elem: elem} elem.Cache.slice = t return t }
编译期间的切片是 Slice 类型的,但是在运行时切片由如下的 SliceHeader 结构体表示,其中 Data 字段是指向数组的指针,Len 表示当前切片的长度,而 Cap 表示当前切片的容量,也就是 Data 数组的大小
type SliceHeader struct { Data uintptr Len int Cap int }
Go 语言中的切片有三种初始化的方式:
- 通过下标的方式获得数组或者切片的一部分;
- 使用字面量初始化新的切片;
- 使用关键字
make创建切片:
扩容
在分配内存空间之前需要先确定新的切片容量,Go 语言根据切片的当前容量选择不同的策略进行扩容:
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片容量小于 1024 就会将容量翻倍;
- 如果当前切片容量大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
哈希表
实现哈希表的关键点在于如何选择哈希函数,哈希函数的选择在很大程度上能够决定哈希表的读写性能,在理想情况下,哈希函数应该能够将不同键能够地映射到不同的索引上,这要求哈希函数输出范围大于输入范围,但是由于键的数量会远远大于映射的范围,所以在实际使用时,这个理想的结果是不可能实现的。
冲突解决
开放寻址法
对数组中的元素依次探测和比较以判断目标键值对是否存在于哈希表中,如果发生冲突,就会将键值写到下一个不为空的位置
开放寻址法中对性能影响最大的就是装载因子,它是数组中元素的数量与数组大小的比值,随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会同时影响哈希表的读写性能,当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找任意元素都需要遍历数组中全部的元素,所以在实现哈希表时一定要时刻关注装载因子的变化。
拉链法
实现拉链法一般会使用数组加上链表,如果发生冲突,将键值写道链表的下一个位置
与开放地址法一样,拉链法的装载因子越大,哈希的读写性能就越差,在一般情况下使用拉链法的哈希表装载因子都不会超过 1,当哈希表的装载因子较大时就会触发哈希的扩容,创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。如果有 1000 个桶的哈希表存储了 10000 个键值对,它的性能是保存 1000 个键值对的 1/10,但是仍然比在链表中直接读写好 1000 倍。
Go 语言运行时同时使用了多个数据结构组合表示哈希表,其中使用 hmap 结构体来表示哈希
type hmap struct { count int flags uint8 B uint8 noverflow uint16 hash0 uint32 buckets unsafe.Pointer oldbuckets unsafe.Pointer nevacuate uintptr extra *mapextra }
count表示当前哈希表中的元素数量;B表示当前哈希表持有的buckets数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是len(buckets) == 2^B;hash0是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;oldbuckets是哈希在扩容时用于保存之前buckets的字段,它的大小是当前buckets的一半;
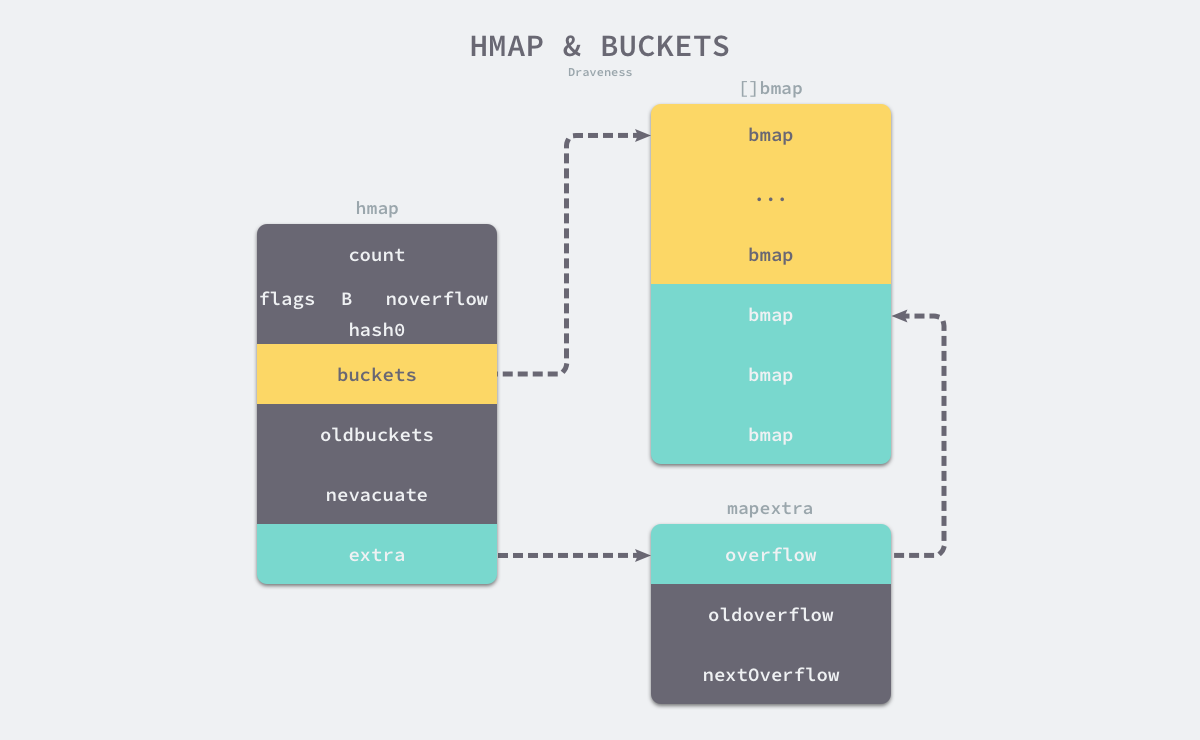
type bmap struct { tophash [bucketCnt]uint8 }
访问
低8位找buckets序号,高8位去tophash找
写入
先查找,存在更新,不存在添加,如果桶满了,调用newoverflow创建新桶或者使用hmap在noverflow创建好的桶来保存数据
扩容
装载因子大于6.5 增量扩容 桶数量翻倍 1次查找-2次搬迁
哈希使用太多溢出桶。 等量扩容 重哈希
字符串
字符串虽然在 Go 语言中是基本类型 string,但是它实际上是由字符组成的数组。Go 语言中的字符串其实是一个只读的字节数组
type StringHeader struct { Data uintptr Len int }
type SliceHeader struct { Data uintptr Len int Cap int }
与切片的结构体相比,字符串少了一个表示容量的 Cap 字段,因为字符串作为只读的类型,我们并不会直接向字符串直接追加元素改变其本身的内存空间,所有在字符串上执行的写入操作实际都是通过拷贝实现的。
作为只读的数据类型,我们无法改变其本身的结构,但是在做拼接和类型转换等操作时时一定要注意性能的损耗,遇到需要极致性能的场景一定要尽量减少类型转换的次数。

