分类——决策树模型(附有决策树生成步骤)
一、决策树的算法的学习
决策树学习通常包括特征选择、决策树的生产、决策树的修剪这三个步骤组成。这些决策树学习的思想主要来自于ID3算法、C4.5算法、CART算法,我学习了这三个算法后是觉得难度依次增加,考虑的问题由局部->总体->优化,下面会依次介绍三种算法个人学习心得,不妥之处,敬请指出。
1、特征选择
三种算法分别对应三种不同的准则,ID3算法运用了信息增益,C4.5算法运用了信息增益比,CART算法运用了基尼指数(Gini)。(这里只简要介绍三个准则,详细请阅读李航教授的《统计学习方法》)。在介绍之前,先介绍熵的概念,随机变量X(为输入实例的所属类。假如有50个随机变量(假设全部被决策树分类),如果所有的随机变量被分成2类,一类有20的,另一类则有30个,则X的取值为2/5、3/5.)的熵定义为从X1、X2到Xn分别与对应的以2或者e为底,X1、X2到Xn对应的自身的乘积的之和的相反数。
首先介绍ID3算法的准则信息增益:它定义为:g(D,A)=H(D)-H(D|A),其中H(D)为经验熵,是上述熵的应用,D是训练数据集;H(D|A)为特征A对数据集D的经验条件熵,个人理解是每个数据集都已经成为某类的一个数据,用特征A对数据集进行划分,划分出来的每一部分中的数据可能从属不同的类,H(D|A)即求的是划分的每一部分的H(Di)之和,信息增益g(D,A)就能求出。但是运用信息增益可能在概率上会有偏好,会造成过拟合,因此有了信息增益比。
C4.5则运用了信息增益比,特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比,即gR(D,A)=g(D,A)/HA(D),其中,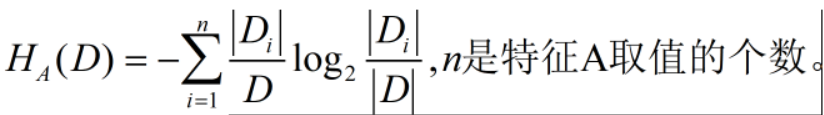
CART算法可以用于分类或回归中,其标准Gini指数请参考李航教授的《统计学习方法》。
2、决策树的生成(我重点从实战中记录心得)
决策树的生成这里使用了sklearn.datasets库中的load_wine数据集,一般的建模从代码层面可以得出模型的准确率、召回率等,但不能生成决策树。而一棵完美的决策树会是建模过程更加的高级,所以有必要学习下。画出对应模型的决策树需要graphviz第三方库(这个库的安装真的有点难度),需要pip进行install,这一点还不够,还需要设置电脑系统环境变量,这是重点。
首先从graphviz官方安装对应的graphviz工具,我安装的是Win10-64位的,安装过程中需要记得安装地址,后面在设置电脑系统环境变量需要使用,安装成功后便开始进行环境变量的设置了。
设置环境变量:首先进入控制面板,找到“系统”,点击进入,
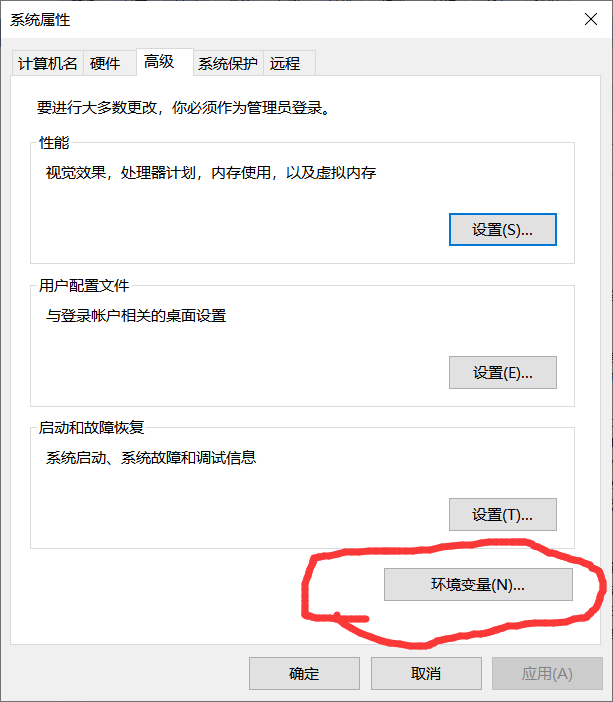
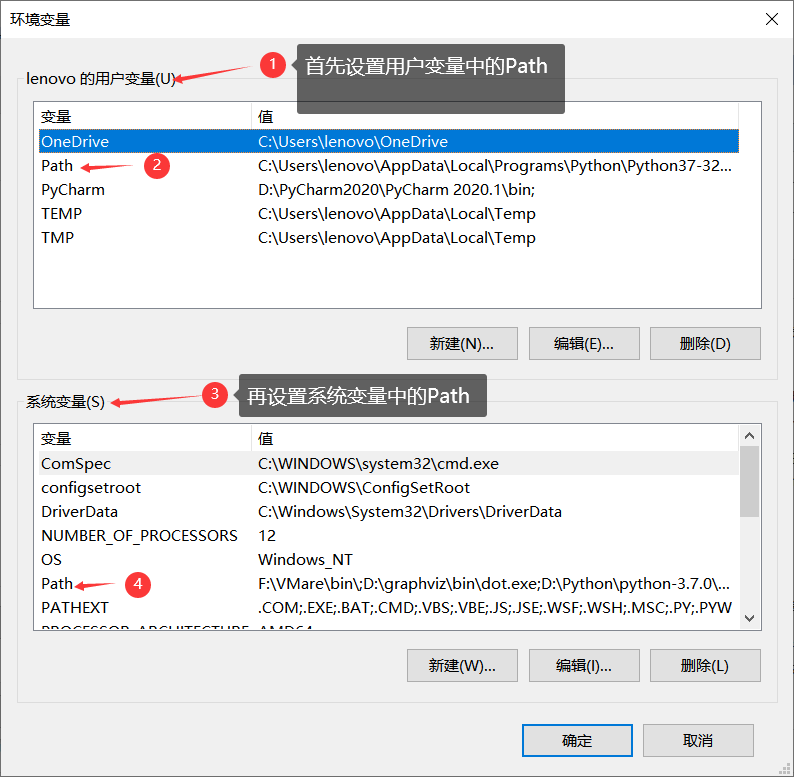
设置用户环境,即输入刚刚安装的地址,以我为例:D:\graphviz\bin
设置环境变量,在安装地址后+\dot.exe,例:D:\graphviz\bin\dot.exe
检测环境变量是否生效:
1.打开dos窗口:win+R
2.输入命令:dot -version
3.观察到如下信息,则该设置生效;

有效之后便是最后一步在Pycharm中安装graphviz库了,成功之后便可以使用(这是正常情况下),如果出现下面的bug,python中运行 仍然出错
’ExecutableNotFound: failed to execute ['dot', '-Tpdf', '-O', 'iris'], make sure the Graphviz executables are on your systems' PATH‘
之后用以下方法查看了环境变量,发现没有,之后追加上。
import os
os.environ[ "PATH" ] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
现在就可以使用了。
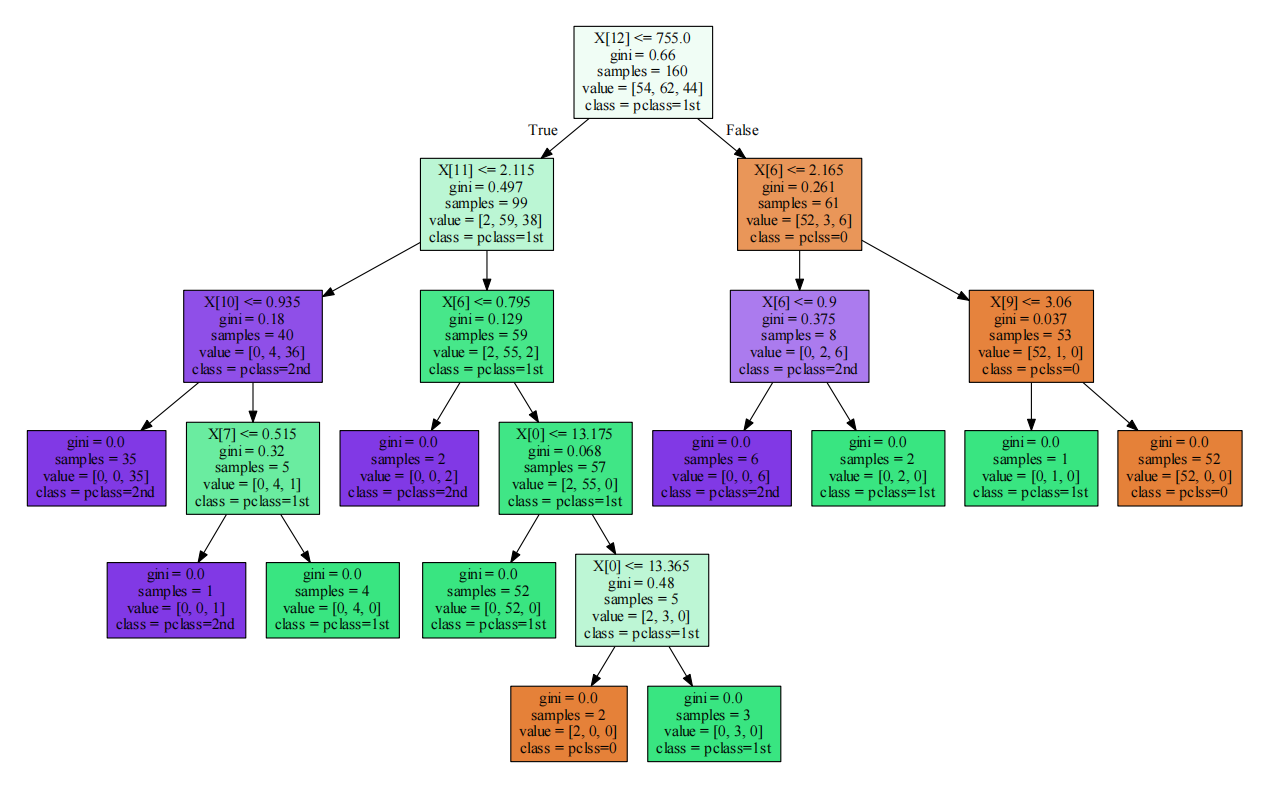
下面给出决策树实现load_wine数据集的代码及决策树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | from sklearn.datasets import load_winefrom sklearn import treefrom sklearn.model_selection import train_test_split as tsplitfrom sklearn.tree import DecisionTreeClassifier, export_graphvizimport graphvizimport osos.environ[ "PATH" ] += os.pathsep + 'D:/graphviz/bin'X,y=load_wine(return_X_y=True)x_train,x_test,y_train,y_test=tsplit(X,y,test_size=0.1)m=tree.DecisionTreeClassifier()m.fit(x_train,y_train)<p>**添加特征名称(feature_names)、分类结果(class_names)、填充颜色filled=True可以给可视化的决策树添加颜色。因为load_wine数据集有13个特征,所有下面没有添加,有需要请自己添加,格式一样。<br>dot_data=export_graphviz(m,out_file=None,<br>class_names=['pclass=0','pclass=1st','pclass=2nd'],filled=True)<br>graph=graphviz.Source(dot_data)<br>graph.render('决策树可视化')<br></p> |
附加读取excel类型文件的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #模型搭建代码汇总from sklearn.tree import export_graphvizimport graphvizimport os import pandas as pd#1.读取数据与简单预处理df = pd.read_excel('员工离职预测模型.xlsx')df = df.replace({'工资': {'低': 0, '中': 1, '高': 2}})#2.提取特征变量和目标变量X = df.drop(columns='离职')y = df['离职']#3.划分训练集和测试集from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)#4.模型训练及搭建from sklearn.tree import DecisionTreeClassifiermodel = DecisionTreeClassifier(max_depth=3, random_state=123)model.fit(X_train, y_train)#以下这两行是手动进行环境变量配置,防止在本机的环境变量部署失败os.environ['PATH'] = os.pathsep + 'D:\graphviz\bin'dot_data = export_graphviz(model, out_file=None)graph = graphviz.Source(dot_data)graph.render('决策树可视化') |
参考文献:
[1]李航.统计学习方法[M].清华大学出版社,2019
[2]徐向武.Python高手修炼之道[M].人民邮电出版社,2020
[3]https://blog.csdn.net/qq_45832050/article/details/109271806?utm_source=app&app_version=4.7.1&code=app_1562916241&uLinkId=usr1mkqgl919blen


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)